

When does the tokenmaxxing math actually become real?
I ran the math. The per-task LLM cost is 50-300x cheaper than human typing right now, and falling 200x/year. By 2028, the cost of "the simple code" is rounding error.


A screenshot was shared in a CTO group chat I’m in. The first post was from Christoffer Bjelke, on Bluesky, dated April 21:
“We hired a junior developer to write the simple code, so we don’t have to spend a ton of money on tokens for those basic/primitive tasks.”
The second was from Sameer Goel, replying:
“Great, so now we’re optimizing LLM costs by inventing employees again. Full circle innovation.”
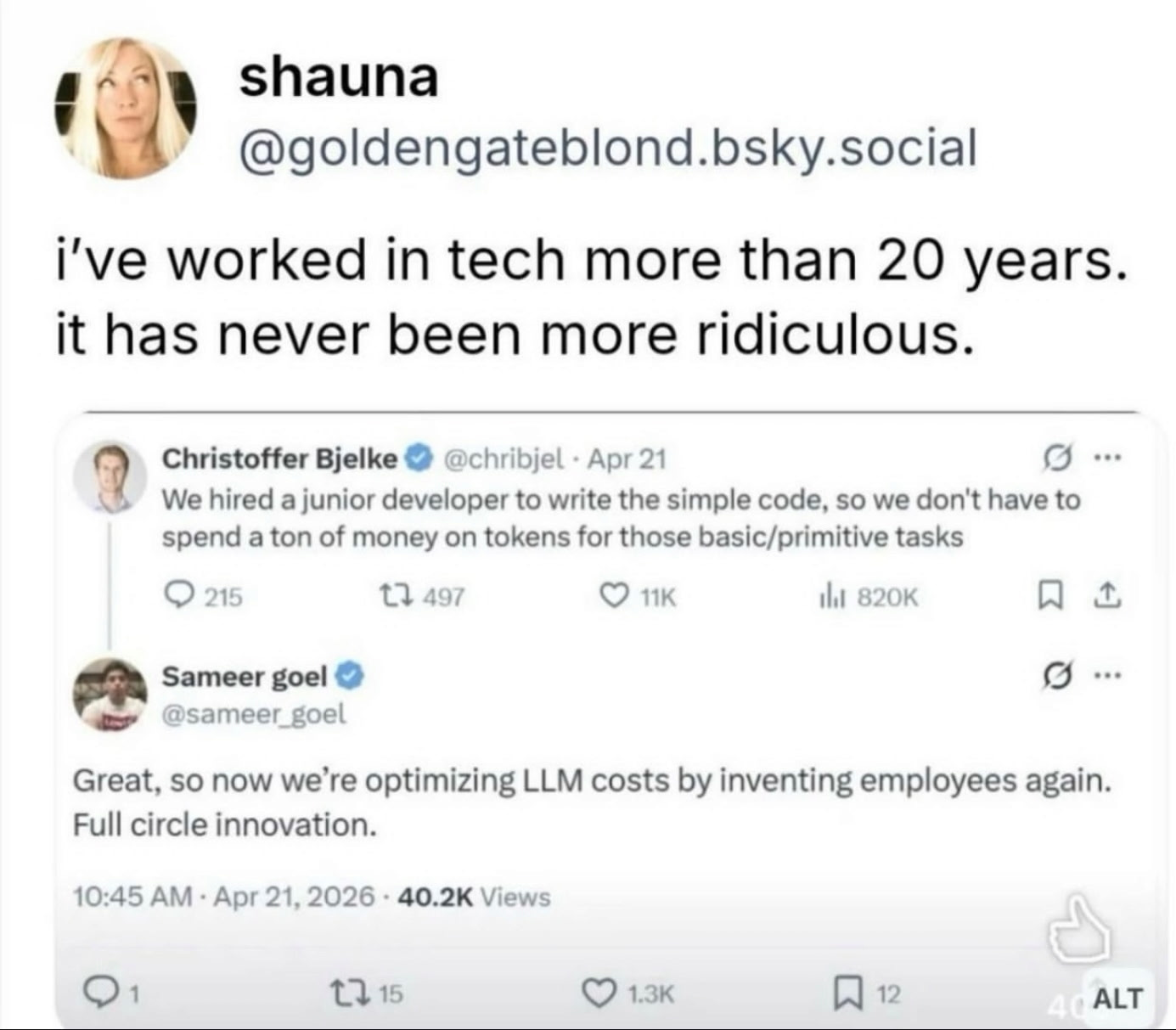
Two posts that hit a nerve. About 820,000 views in a week. The chat exploded the way chats explode when something genuinely funny sits on top of something genuinely uncomfortable.
I typed back: “I love doing this math. Standby! Crunching some numbers.”
I wasn’t being clever. I just wanted to know if the math actually worked.
The math
A US-based junior developer, fully loaded — salary, benefits, laptop, manager time, health plan, the whole thing runs $95K to $130K a year. That’s roughly $360 to $500 per workday.
A “simple coding task” in current LLM economics is something like 2,000 input tokens and 1,000 output tokens. Pricing it across the current model lineup at input/output rates per million tokens:
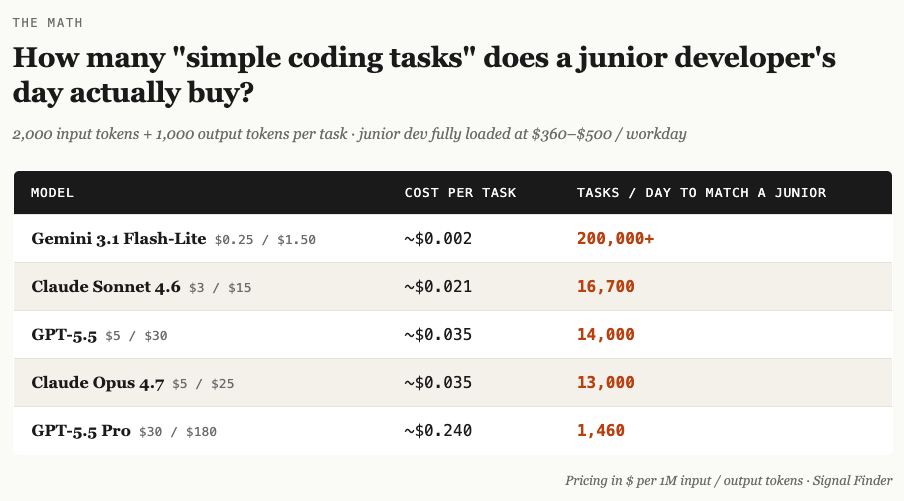
A junior dev ships maybe 100 to 300 tasks a day if you’re being generous about what counts as a task. At Sonnet pricing, the same throughput costs $2 to $6 a day in inference. The per-task gap, even at the most expensive frontier tier, runs 50 to 300 times cheaper than a human typing code.
And it’s getting worse. Or better, depending on which seat you’re sitting in.
Epoch AI tracks per-token inference price decline at roughly 200x per year since January 2024.
Stanford HAI’s 2026 Index reports that GPT-3.5-equivalent inference dropped 280x in eighteen months.
By 2028, on the current curve, the per-task cost of “the simple code” is rounding error at every tier.
Not metaphorically. Actually a rounding error.
I worked through the architecture-side of this a few weeks ago — the per-token rate was always the least important variable on the AI bill. The hiring math is that same mistake on the labor side.
So Bjelke’s startup, on the spreadsheet, made a call today’s token prices make look ridiculous. They paid five-figures-monthly in salary to do something that costs single-digit dollars a day in tokens. From a pure cost lens, the move looks irrational. That’s why Goel’s tweet got the laugh.
Except
The math has been “real,” in the sense of being wide enough to justify the cut, for about 18 months. Long enough that if it were going to drive the great purge, it already would have. People are still being hired.
Andrew Bosworth at Meta says senior engineers should spend tokens “with no upper limit,” equal to their salary, and they’ll get tenfold output.
Jensen Huang says he’d be alarmed if a $500K engineer didn’t burn $250K in tokens.
Both are right about what they’re describing. Neither is pointing to a place where the cost arithmetic broke companies and forced them to swap people for inference. They’re pointing to places where token spend went up alongside hiring, not instead of it.
So when does the math actually become real?
Maybe it never does. Maybe the math was always asking the wrong question.
What the units don’t measure
Even if cost goes to zero, even if every task you can name can be done by an LLM for a fraction of a cent, what’s left for humans?
Tasks were the unit the spreadsheet could measure, not the unit the work was ever made of. What I actually do, when I watch closely, isn’t tasks. It’s a dozen other things that happen on top of tasks.
I hold Context across systems and people nobody explicitly told me. The agent finishes the ticket. I notice the ticket was the wrong ticket. That notice is the work and judgement. Nobody filed a ticket for notice this is the wrong ticket, and nobody will.
I notice when the obvious answer is wrong.
ARC-AGI-3 is the latest reasoning benchmark. It’s a set of puzzles designed to be unfamiliar by construction. Humans solve them at 100%. Frontier models score under 1%. The benchmark isn’t asking “can the model do the task.” It’s asking “can the model recognize that the obvious approach is wrong on a problem it has never seen before.” That recognition “this looks right and isn’t“ is the part the per-token math doesn’t inc;ude in the pricing, because it doesn’t appear in any task anyone handed you. It appears in the moment you decide the task itself is mis-specified.
I’m the name on the bug report. Liability has to attach to something that can be summoned to a meeting. The compiler that built itself doesn’t have a name on it.
Anthropic published a case earlier this year where 16 agents collaborated to produce a 100,000-line compiler that boots Linux 6.9 on x86, ARM, and RISC-V for about $20K of inference. Astonishing piece of work. Also: when that compiler ships into production and corrupts a customer’s data, who picks up?
Some person, eventually. Someone has to sign.
I grow into the thing I don’t yet know how to do.
The juniors of today are the seniors of 2030. There’s no lateral-hire market for “a person who already knows what good looks like in your specific stack and your specific business.“
That person is developed, slowly, by writing bad code under supervision and getting it sent back. Cut the bad-code-under-supervision step, and you don’t get the senior in five years. You get a market in which everyone is bidding for the same diminishing pool of people someone else already trained.
Which is a fine strategy if you’re confident someone else is going to keep doing it for you.
I bring context the agent can’t pick up and what this client said in the meeting last quarter, what the regulator hinted at off the record, the political weight of the email I’m about to send.
The agent can read the email; it can’t read the room. Yet.
And the most valuable work in any senior role is the work that never had a task associated with it. Problems nobody pointed at anyone are the ones that quietly compound into next quarter’s crisis.
What the cost arithmetic was actually solving for
The spreadsheet was solving for “how cheaply can we replicate the typing.”
The work was asking “who notices the things nobody told them to notice.”
Those are not the same question. The math might work; but the question doesn’t.
Bosworth and Huang are right about senior token spend. A senior who knows what to ask for and can read what comes back is the most productive configuration enterprise software has ever produced.
I’d argue it’s the most output any enterprise tool has unlocked in my working life.
But that argument quietly requires the senior. It assumes someone already knows what good looks like, what to ask for, what the output should look like before it arrives.
It fails to tell you how the next one of those “seniors“ gets made.
The honest answer is they get made the way they’ve always gotten made. Slowly. By doing work that’s slightly above their skill level, getting it wrong in legible ways, having someone more experienced catch it, and trying again.
If we remove that loop because the per-task math says the loop is expensive, we’re not optimizing. We’re eating the seed corn and calling it efficiency. Short term efficiency.
Back to the screenshot
Bjelke’s startup did the only honest thing. They noticed they needed a human and they hired one. The internet mocked them for it because the industry has trained itself to read “hiring” as a regression from some imagined fully-automated future. They named the problem statement correctly. What they recognized even if they didn’t articulate it this way in the post (and my interpretation of it) is that some part of what a junior developer does is the typing, and the part they were going to need wasn’t the typing.
It was the slow, expensive, biological process of someone learning what good code looks like by writing bad code under supervision.
The typing was the cheap part. The learning was the asset.
When the typing is cheap, there’s nobody to call when it goes wrong. Someone still has to pick up. The math never asked who.
I keep coming back to Goel’s line: full circle innovation. He meant it as the punchline. Read it the other way, though, and it might be the most honest thing anyone has said about this whole moment. Automation got invented. The industry ran it against the cost of people. The industry discovered it still needed people. It hired them back. Not because anyone got the math wrong, but because the wrong thing was being measured all along.
So here’s what I’m sitting with: if the per-task cost goes to zero next year and at the current curve, it basically does — what is the question that actually needs answering about why anyone still hires?
What’s the part of your team’s work that never showed up on any spreadsheet?