

The Token Paradox: Why cheap tokens made Enterprise AI more expensive
Per-token AI prices fell 280x in two years. The average enterprise AI budget rose nearly 6x in the same period. If those two facts seem contradictory, you're not alone

Follow up May 2026 article published here.
The Token Paradox: One Month Later, a Dial I Missed
Per-token costs are down 280x. Enterprise AI bills are up 480%. The gap is an architecture problem.
I propose a four-factor fix.
Enterprise AI inference bills have become the fastest-growing line item in enterprise tech budgets. Deloitte found some firms now spend up to 50% of their IT budget on AI tokens alone. The token price is the least important number in that invoice. The costs that actually matter: agentic volume, RAG inflation, procurement routing, and legacy model inertia. Those are the ones nobody’s measuring.

The Jevons paradox, but with tokens
In 1865, William Stanley Jevons noticed something counterintuitive about James Watt’s steam engine. By making coal consumption dramatically more efficient, Watt didn’t reduce total coal demand — he exploded it. Cheaper energy made new applications viable. Factories multiplied. Coal consumption in England grew tenfold after the efficiency breakthrough.
AI tokens are running the same play.
Jevons paradox in plain English: When something gets radically cheaper to use, people don’t just use the same amount for less money — they find entirely new things to do with it. Total spending goes up, not down.
Consumption is outpacing price cuts on three fronts.
A single fraud detection task no longer means one prompt and one response. An agentic pipeline makes 10-20 LLM calls per case: retrieval, classification, summarization, decision, audit trail generation. Gartner and Oplexa both confirm agentic architectures consume 5-30x more tokens than a standard chatbot interaction.
Every RAG query — where the model pulls relevant documents before responding — stuffs 3-5x more tokens into the context window than the user’s actual question. A 500-token question about a claims policy becomes a 15,000-token prompt after the retrieval layer adds relevant documents.
RAG in plain English: Before answering your question, the model first searches a document library for relevant context and pastes it into the prompt. That’s why a 500-token question becomes a 15,000-token prompt — the retrieval layer is stuffing the context window with supporting material before the model starts thinking about your answer.
Then there’s always-on monitoring. When a fraud detection agent runs 24/7 across 500 cases a day at 15 LLM calls per case, the monthly token volume dwarfs anything a human team generates. These are workloads that didn’t exist two years ago because nobody would have paid the per-token rate.
Deloitte projects 61% of enterprises will exceed 10 billion tokens per month by 2028. Gartner predicts a 90% reduction in inference cost by 2030, and still expects net AI spending to rise. The pattern is Jevons, not paradox.
It’s what happens when you make a powerful input radically cheaper.
A quick primer on tokens
Every number in this article is denominated in tokens. Here’s what that means.
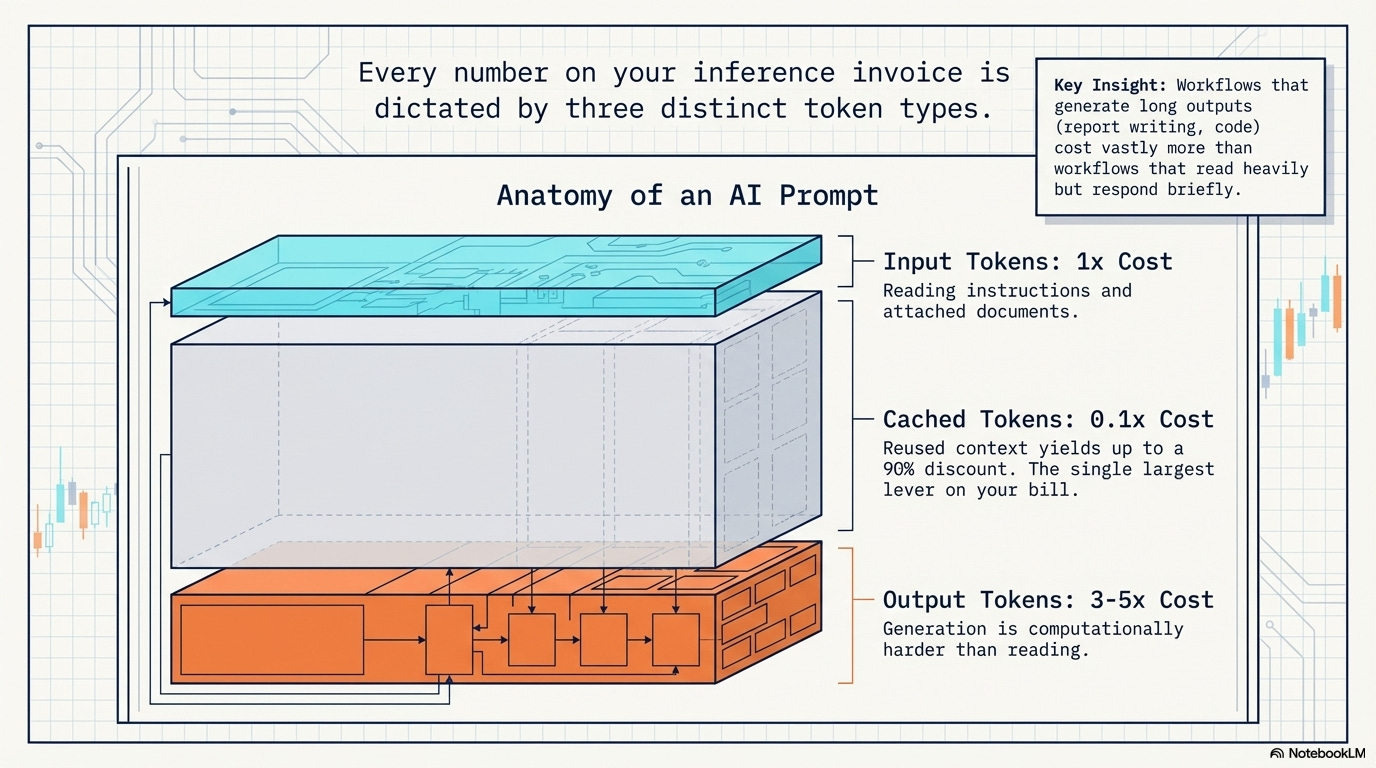
A token is roughly ¾ of a word. “Insurance” is two tokens. “Catastrophic reinsurance policy” is four. Every interaction with an AI model gets metered in tokens, and three types show up on your bill:
Input tokens are what you send to the model: your question, the documents you attach, the system instructions that tell it how to behave. A simple prompt might be 50 tokens. A RAG query that stuffs five policy documents into context might be 15,000. Input is typically the cheaper side.
Output tokens are what the model sends back: the answer, the summary, the generated report. Output costs 3-5x more than input per token because generation is computationally harder than reading. A 500-word fraud narrative costs roughly 670 output tokens.
Cached tokens are the cost optimization that’s easy to miss. When the same context gets reused across multiple queries (say, the same policy document referenced by 200 different customer questions), providers like Anthropic and Google let you cache that context. Cached input tokens cost up to 90% less than fresh input. For any workflow with repeated context, this is the single largest lever on your bill.
Pricing is quoted per million tokens. When you see “$3 / $15” for Claude Sonnet 4.6, that’s $3 per million input tokens and $15 per million output tokens.
A workflow that generates long outputs (report writing, code generation) costs significantly more than one that reads a lot but responds briefly (classification, scoring).
The real math: seven use cases
Most pricing analyses stop at quoting the per-token rate. The rate is almost irrelevant. What matters is the rate multiplied by the volume your architecture demands.
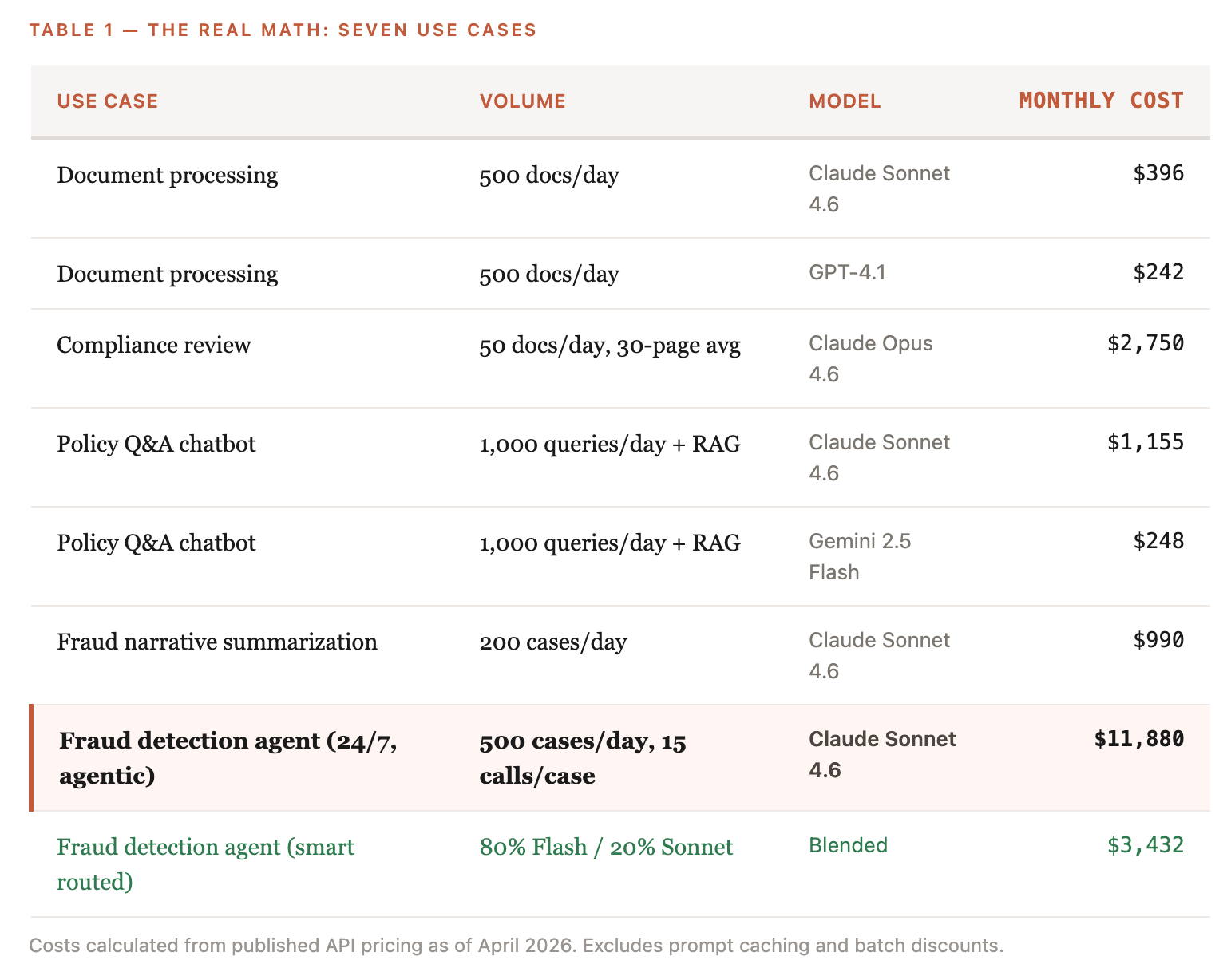
That last line is the headline. A single agentic fraud detection pipeline costs more per month than subscribing an entire 10-person claims team to Claude Pro. The volume multiplier from agentic architecture is the dominant cost variable. Not which model. Not which provider.
A mid-market insurer running 500 fraud cases a day through an agentic pipeline at $11,880/month can apply smart routing — 80% Gemini Flash for routine checks, 20% Claude Sonnet for complex cases — and land at $3,432, a 60-70% reduction without changing the workflow.
The model selection with smart routing is the cost killer here.
Three pricing traps most teams never model
There’s a persistent claim in enterprise AI circles: cloud marketplaces charge a 30-50% markup over direct API access. We checked first-party pricing pages for AWS Bedrock, Azure OpenAI, and Vertex AI against direct API rates from Anthropic, OpenAI, and Google.
For current-generation models, base per-token rates match. Claude Sonnet 4.6 costs $3/$15 per million tokens whether you go through Bedrock or directly through Anthropic. GPT-4.1 is $2/$8 on both Azure and OpenAI’s API. The blanket markup narrative is wrong.
The real premiums are more specific. And more dangerous.
Legacy model inertia is the most common silent cost trap.* AWS Bedrock still lists Claude 3.5 Sonnet at $6 input / $30 output per million tokens, exactly double the current Claude Sonnet 4.6 rate. Teams that deployed six months ago and never touched their model parameter are paying a 100% premium for a previous-generation model.
Data residency requirements add another layer. Singapore, EU, and UK workloads get routed through regional endpoints that carry a 10% premium on both Bedrock and Vertex. For regulated financial institutions, this isn’t optional: MAS FEAT Principles, the UK’s SM&CR, and ECB Model Risk Management frameworks require audit trails and data locality that a US-based API call can’t satisfy.
The regulatory alphabet decoded: MAS FEAT = Monetary Authority of Singapore’s principles requiring AI in financial services to be Fair, Ethical, Accountable, and Transparent — with documented evidence for each. SM&CR = the UK’s Senior Managers and Certification Regime, which places personal liability on named executives for third-party risk decisions, including AI vendors. ECB Model Risk Management = European Central Bank guidelines requiring validated governance for any model influencing financial outcomes. The common thread: regulators want a paper trail. A bare API call to
api.anthropic.comdoesn’t produce one. A marketplace deployment does.

Then there’s priority tier pricing. Google’s Vertex AI charges an 80% premium for priority access with guaranteed uptime. For a customer-facing chatbot, latency matters. For batch document processing overnight, it doesn’t. Teams often default to priority tier for everything.
A compliance team running Claude 3.5 Sonnet on Bedrock because “it’s working fine” is spending $6/$30 per million tokens when they could be on Sonnet 4.6 at $3/$15, same quality tier, half the price. That’s a one-line configuration change. Across 50 documents a day for a year, the legacy premium adds up to roughly $19,800 in unnecessary spend.
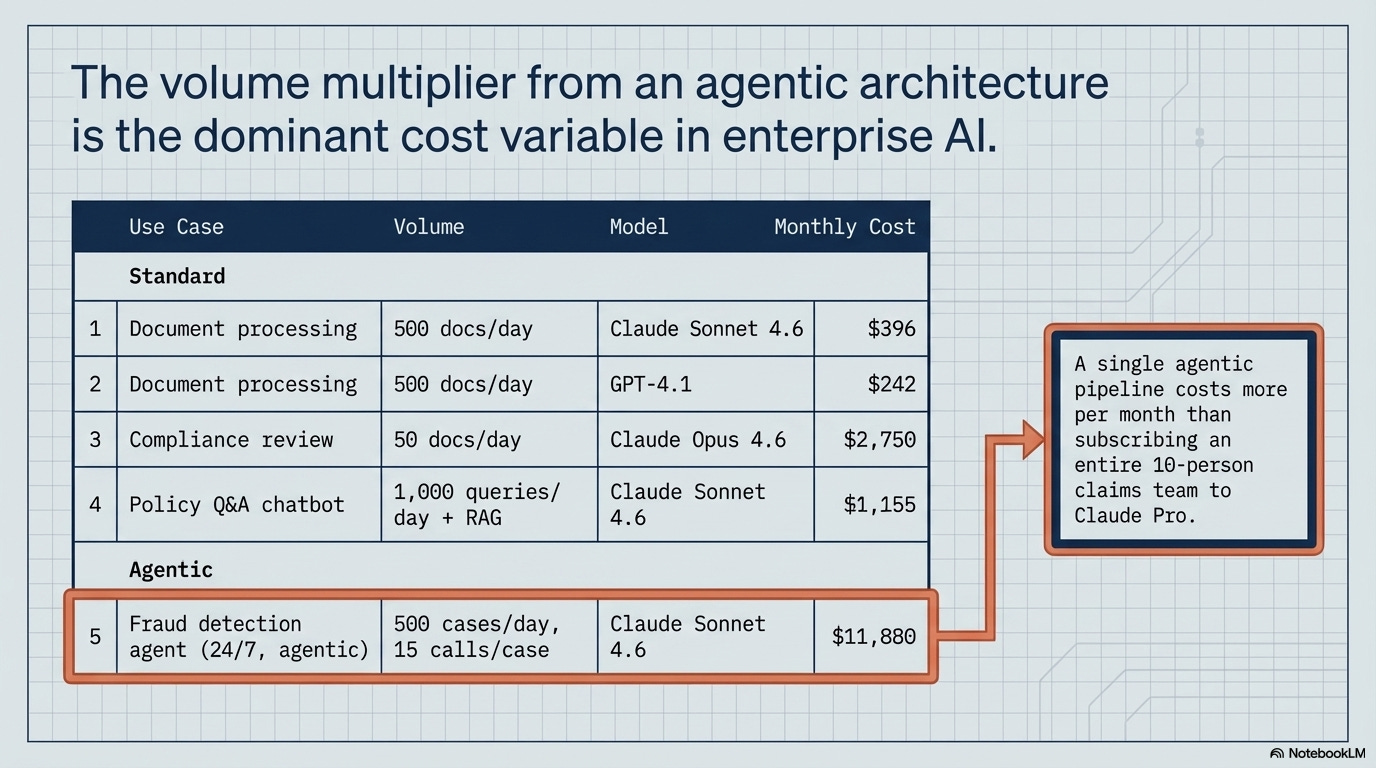
Here’s the thing pricing-only analysis misses: for large regulated firms, marketplace procurement isn’t a choice and it’s the compliance-friendly path. A named senior manager under SM&CR must be personally accountable for third-party AI risk. Bare API calls don’t provide the audit trail to satisfy that. The marketplace “premium” (where it exists) buys regulatory defensibility.
For current models, the premium is often zero. Most of them had to be on marketplace anyway.
Subscription vs. API: an architecture decision
The subscription-vs-API debate gets filed under procurement. It belongs under architecture.
Claude Pro costs $20/month and caps at roughly 44,000 tokens per 5-hour window. Over a working day (two windows), that’s about 88,000 tokens. Over 20 working days, roughly 1.76 million tokens per month. At API rates for Claude Sonnet 4.6, that volume costs about $10.56.
The subscription charges nearly twice its own API-equivalent compute at the cap. What it buys is product surface: the UI, web search integration, computer use, and zero-configuration access. For most individual knowledge workers, that’s the better deal. The break-even for Claude Pro vs. API is roughly 1,667 interactions per month (about 83 per working day). Almost nobody doing ad-hoc work hits that.
Where subscriptions win outright:

For a 10-person claims team at $200/month, you get built-in web search, document analysis, and computer use with no engineering overhead. The API equivalent would require building a UI, managing auth, and maintaining a deployment, all to save roughly $95/month in raw compute.

Where API wins outright: any workflow where machines generate prompts. Agentic pipelines, batch document processing, 24/7 monitoring, RAG-powered chatbots serving hundreds of users. Once you cross ~100 interactions per day per workflow, the subscription model doesn’t scale and the API’s batch processing (50% discount) and prompt caching (up to 90% input cost reduction) create savings no subscription can match.
The 4-factor framework
AI model pricing has the same fragmentation: three frontier labs, three cloud marketplaces, open-source alternatives, and a new batch of reasoning models all competing on different dimensions.
The shift from per-unit to outcome-based pricing is now happening at the model layer itself.
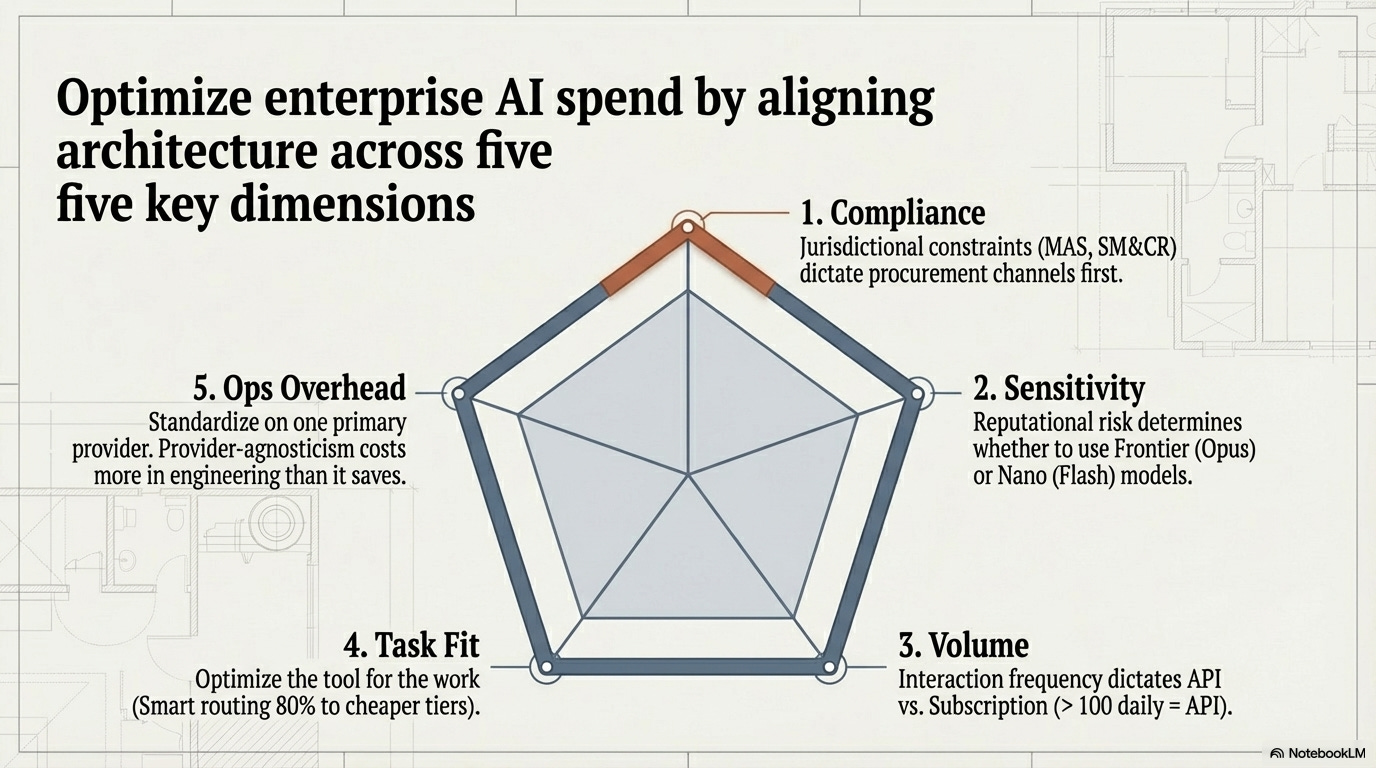
A pricing comparison alone won’t save anyone. Four factors determine the actual number.
1. Sensitivity tier. What’s the regulatory and reputational consequence of a wrong output? Compliance interpretation and customer-facing advice need frontier models (Opus, GPT-5.4). Internal summarization and data extraction can run on Flash or nano-class models at 10-50x lower cost.
2. Volume bracket. Is this 30 queries a day or 30,000? Below a few hundred daily interactions, subscription pricing wins. Above that, API with batch processing (50% discount) and prompt caching (up to 90% input cost reduction on repeated context) changes the economics entirely.
3. Task-level fit. Not every task needs the best model. Research from MIT and Deloitte finds only 5-15% of enterprises capture meaningful bottom-line AI value, often because teams optimize the tool without redesigning the work around it.
Model selection works the same way: route 80% of traffic to a cheaper model that’s good enough for the task and you cut costs 60-70% without degrading the outcome that matters.
4. Operational overhead. This is less intuitive for many organizations. Running Claude on Bedrock and GPT on Azure means managing two billing systems, two identity and access control frameworks, two monitoring stacks, and two compliance certification scopes. Switching providers mid-deployment typically takes weeks to months of engineering effort.
Pick a primary provider and go deep. Maintain a tested secondary. Full provider-agnosticism is a fantasy that costs more in operational overhead than it saves in per-token arbitrage.
One thing worth pushing back on
The Jevons framing has an escape hatch built into it: it can make the cost explosion sound inevitable. It wasn’t. It was the compound result of architecture decisions nobody modeled: deploying agentic pipelines without counting LLM calls per task, leaving legacy models running on autopilot, defaulting to priority tier pricing for batch workloads that could have waited. Jevons explains the macro pattern. It doesn’t excuse the micro decisions.
The 4-factor framework also has a geographic blind spot. It covers sensitivity, volume, task fit, and operational overhead. For a mid-market US insurer, that’s sufficient. For a firm operating under MAS in Singapore, SM&CR in London, or ECB oversight in Frankfurt, there’s a fifth factor the framework doesn’t capture: jurisdictional compliance requirements that dictate procurement channel before any cost optimization begins. We kept the framework at four because some readers operate in a single jurisdiction where compliance is a procurement input, not a model selection variable.
If you’re running cross-border operations, add a fifth factor. Put it first, because it constrains everything downstream.
What this means for technology leaders
Only 5-15% of organizations report meaningful bottom-line AI impact, despite process-level wins at firms like Aviva (£100 million saved) and Zurich UK (98% claims accuracy). The explanation, per Sean Eldridge at Gain Life: “the surrounding process absorbs the efficiency rather than eliminating cost.” Insurance operates on combined ratios near 100%. There’s no margin to absorb an unplanned AI cost surprise.
There’s also a ticking clock. OpenAI reported $3.7 billion in revenue against an estimated $5 billion in losses. Current API pricing is venture-subsidized. Open-source models (Qwen, Llama, DeepSeek) create a pricing floor that makes dramatic increases unlikely, but building an architecture that assumes today’s rates are permanent is a bet on continued subsidy.
Three moves for this quarter:
Audit your model versions. If any production workload is running a model from more than six months ago, check whether a newer version at a lower price point matches or exceeds quality. Legacy model inertia is the most common silent premium.
Map your volume multipliers. Count actual LLM calls per task, not per user query. If agentic workflows are generating 10-20 calls per task, the per-token rate is a rounding error next to the architecture decision.
Measure cost per outcome, not cost per token. Allianz’s fraud detection pipeline caught 29% more fraud. At $11,880/month, that’s cheap. The same pipeline catching nothing new at $3,432/month is expensive. The right denominator is the business outcome, not the token.
What’s the single largest AI cost surprise your team has encountered, and was it the rate or the volume?
References: