

The Token Paradox: One Month Later, a Dial I Missed
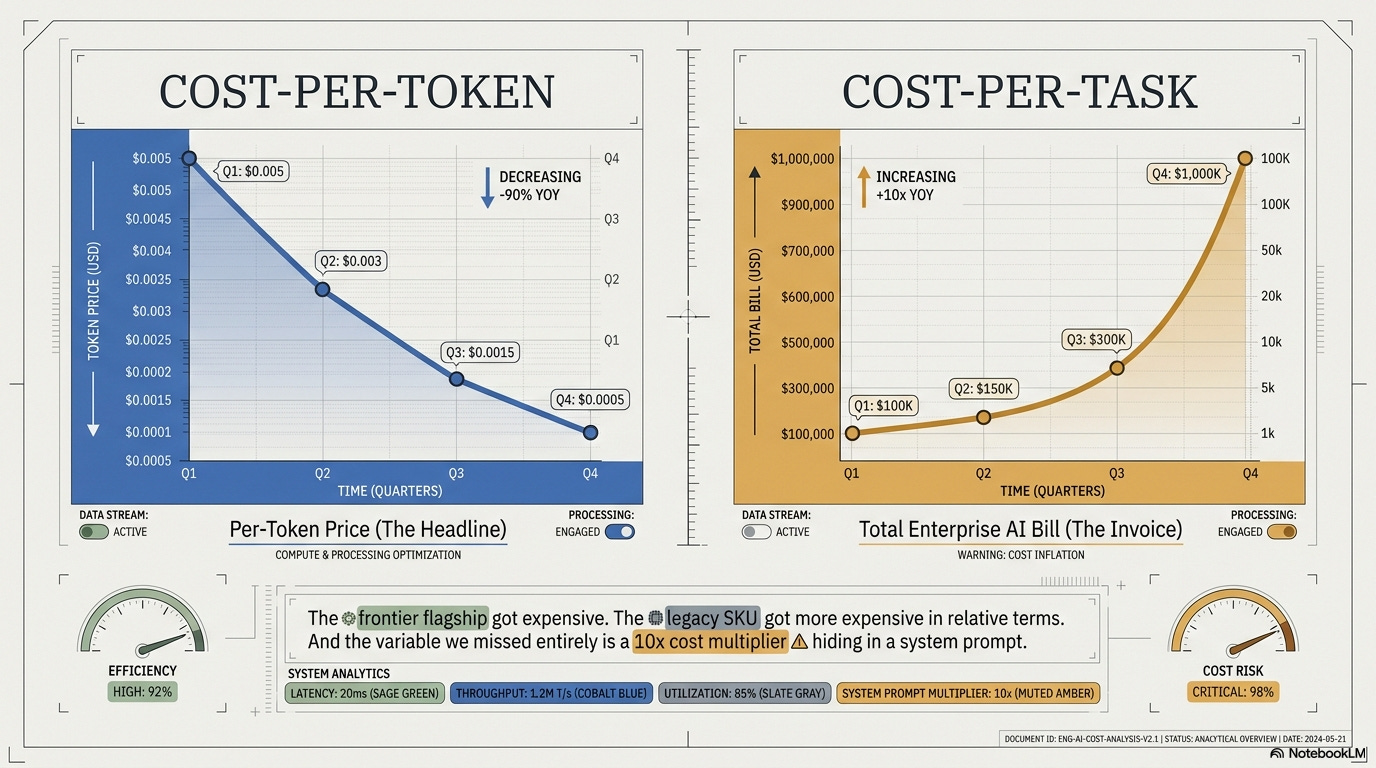
Same model. Same prompt. Ten times the bill.

The frontier flagship got expensive, the legacy SKU got more expensive in relative terms, and the variable I missed entirely is a 10x cost multiplier hiding in a system prompt.
Follow up to the April article:
The Token Paradox: Why cheap tokens made Enterprise AI more expensive
A month ago I argued the per-token price collapse didn’t matter because enterprise AI bills kept rising. That argument is still right. It just got more uncomfortable.
In the Token Paradox piece on April 8, I said the real cost drivers were three: procurement channel, volume growth, and architecture overhead. Four weeks later, that framework is missing a fourth variable big enough to swallow the other three. Same model, same prompt, ten times the bill, depending on a setting most enterprise teams don’t know exists.
The pricing pages also moved in ways nobody priced into the April math.
A month later, four pieces of news
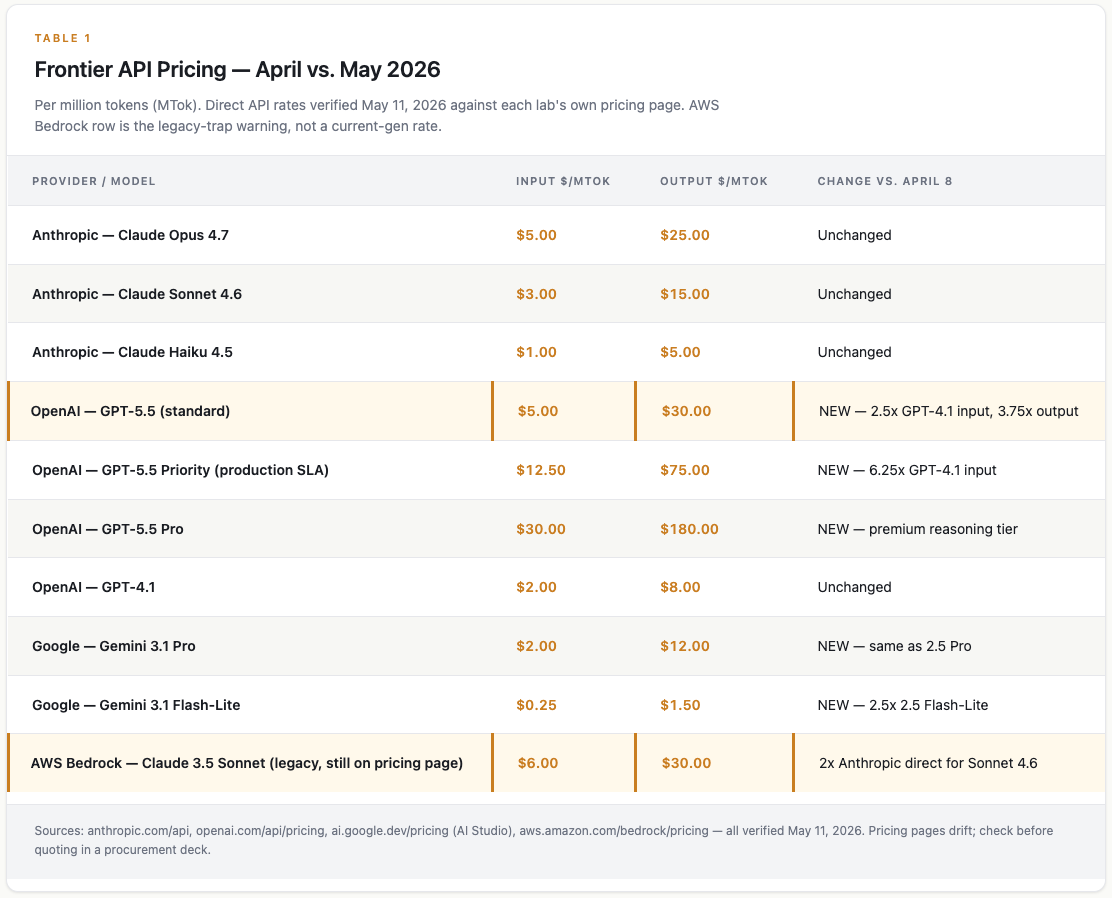
OpenAI shipped GPT-5.5 at $5 in / $30 out per million tokens (MTok). That’s 2.5x more on input than GPT-4.1 and 3.75x more on output. The production tier (called Priority, which is what an enterprise actually buys if it needs an uptime guarantee) runs $12.50 / $75. That’s 6.25x GPT-4.1 input. The Pro tier hits $30 / $180.
The “per-token prices are falling” narrative - GPT-5.5 is the exception.
Google held the pricing line. Gemini 3.1 Pro launched at $2 / $12, exactly Gemini 2.5 Pro pricing. No new-model premium. The cheapest tier (Flash-Lite) moved up to $0.25 / $1.50, which suggests Google is repricing the ultra-cheap floor upward while pinning the frontier flat. Google is using price to compete.
Anthropic didn’t move. Opus 4.7 stays at $5 / $25, Sonnet 4.6 at $3 / $15, Haiku 4.5 at $1 / $5. Same numbers as the April brief.
And the AWS Bedrock pricing page, verified May 11, still shows Claude 3.5 Sonnet (the 2024 model) at $6 / $30. Sonnet 4.6 ($3 / $15 direct) and Opus 4.7 aren’t on the page at all. Any enterprise running Claude through Bedrock on autopilot is paying a 100% premium for a model that’s two generations old. The legacy trap I flagged in April hasn’t been fixed; it’s gotten more expensive in relative terms because the current-gen rate at the same vendor is half.
So at the frontier: OpenAI up sharply, Google flat, Anthropic flat. Three different bets on whether smarter is what wins.
The dial nobody is using
My April piece assumed model choice and call volume were the levers. They are. But there’s a third lever, bigger than either, and most enterprises may not know it is this powerful.
Anthropic’s internal optimization playbook (a document called “The Optimization Engine,” written for the Opus 4.7 era) documents a five-step effort dial. Same model, same prompt, exponentially different token spend.
Effort level, in plain English: Picture an inspection job on a building.
“Quick eyeball” gets you a one-line answer in five minutes.
“Walk-through” gets you a real estimate in an hour.
“Full engineering inspection” gets you certainty, and a bill ten times higher, because the inspector actually checks the foundations.
The model is the inspector. The effort level is which inspection got ordered.

Low effort runs cheap and basic. Max effort runs ten times the cost and is reserved for “challenges where cost is irrelevant.” Extra High captures roughly 95% of Max performance at a fraction of the spend. Extra High is also the default in Claude Code and on claude.ai, where most pilots actually start. Most teams inherited that default and never touched it.
This matters because of how agentic workloads spend tokens. Three kinds of tokens get billed equally:
thinking tokens (internal reasoning, invisible to the user),
tool calling tokens (file reads, API calls, web searches), and
text tokens (what the user sees).
For an agent doing fifteen calls per case, the thinking and tool-call volume can be five to ten times the visible output.
So when an agent is humming along at its default Extra High setting, the bill is the per-token rate times the visible output times the effort multiplier times the agentic overhead. The pricing page shows the first number. The invoice shows the product.
The common enterprise “cost optimization” (disable thinking, toggle reasoning off) is the wrong lever. It degrades quality without proportional savings.
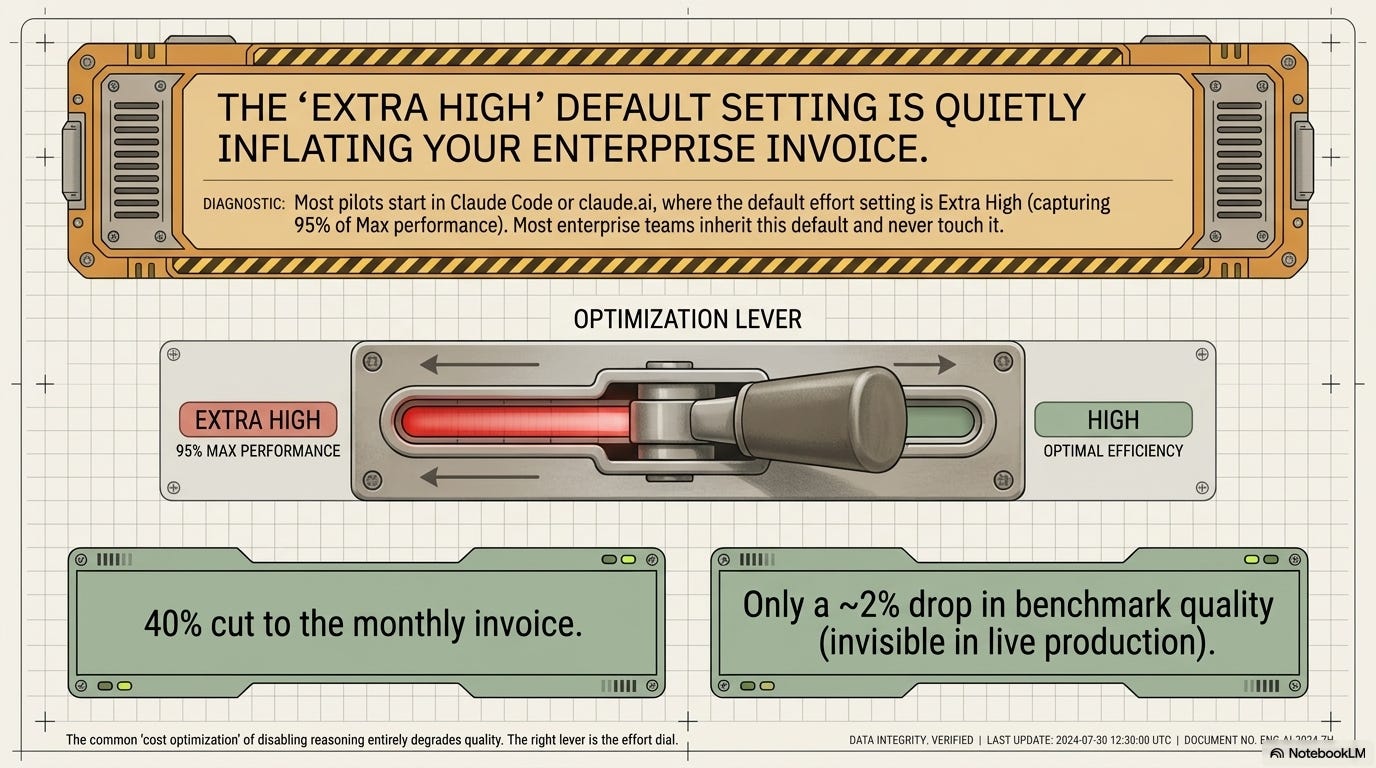
The right lever is the effort dial.
Drop Extra High to High on Claude Sonnet 4.6 and a $11,880/month fraud detection pipeline becomes roughly $7,128. That’s a 40% cut for about a 2% quality hit, and it’s a system-prompt change.
What it costs
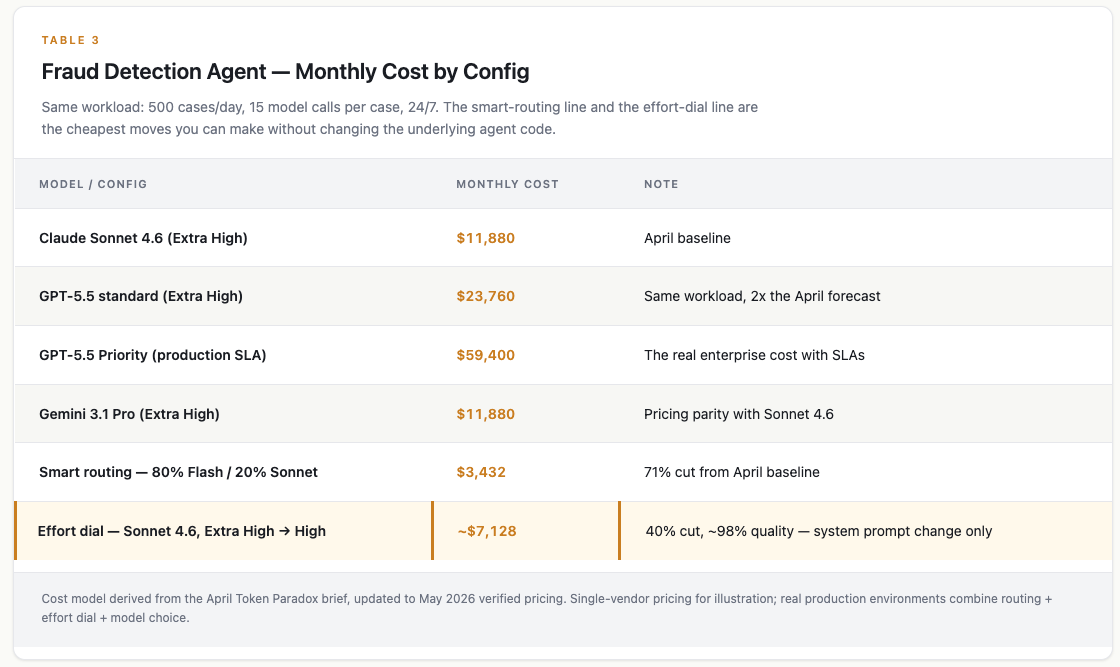
Fraud detection agent, 500 cases a day, 15 model calls per case, 24/7. Same workload, six configurations:
Three things jump out:
GPT-5.5 doubles the April forecast at the same workload, same effort level. If someone bought GPT-5.5 expecting the GPT-4.1 cost line, the invoice is going to surprise them. Priority pricing (what production environments actually pay) quintuples it.
Gemini 3.1 Pro hits pricing parity with Sonnet 4.6. Google holding $2 / $12 against Anthropic’s $3 / $15 means the procurement frontier is now a three-vendor decision, not OpenAI-led.
The effort dial is the cheapest move on the board. Drop Extra High to High on Sonnet. 40% off the bill. About 2% quality drop, measurable in benchmarks, invisible in production fraud catch rates. No model change, no procurement work, no architecture rework.
The Bedrock trap, six weeks unchanged
In April I noted that Claude 3.5 Sonnet on AWS Bedrock ($6 / $30) was a legacy premium versus Sonnet 4.6 direct ($3 / $15). The trap looked like a small procurement oversight.
It’s worse than that now. The Bedrock pricing page as of May 11 still lists Claude 3.5 Sonnet at the same rates. The newer Anthropic models aren’t on the page at all. Teams whose AI procurement runs through AWS contracts (most large finserv buyers) are paying double the direct rate for a 2024 model and don’t have the current-gen rate available through their procurement channel.
This is the second time I’ve checked. Nothing has updated. Six weeks for AWS to publish a current-gen Claude price on Bedrock, and the answer is still no.
Update (May 11, same day): Anthropic and AWS just announced Claude Platform on AWS, which goes live today. It’s the native Claude Platform (not Bedrock) running inside your AWS account at Anthropic’s published pricing—$3 / $15 for Sonnet 4.6, $5 / $25 for Opus 4.7. No markup, no legacy SKU trap. For teams on AWS contracts, this is the path that should have existed six weeks ago.
In practice: A regional bank running 100 million Claude tokens a month through their existing AWS contract on autopilot spends $600K/year. Direct API at the current-gen rate: $300K. Same model family, half the bill, same compliance posture. The procurement team doesn’t know to ask because the SKU isn’t on the AWS pricing page. The model team assumes the cloud team handled it. The cloud team assumes procurement handled it. Nobody is individually wrong. The bill is double.
Caveat for the large-enterprise reader: if you have an AWS Enterprise Discount Program, your actual Bedrock rate may be negotiated below the public number. The 100% premium claim applies to the standard-pricing path. If your contract is negotiated, check the real rate before reading this as a procurement red flag.
To be fair
The strongest counter to the frontier-inversion thesis: GPT-5.5 may cost more per token but reasons better, so fewer calls = lower total cost. If a bounded task that took GPT-4.1 ten turns now takes GPT-5.5 four turns, the higher per-token rate may still net out cheaper.
On focused tasks, this works. The May 2026 enterprise benchmarks show GPT-5.5 using about 40% fewer output tokens on coding work. Terminal-Bench 2.0 at 82.7%. SWE-bench Verified saturated. The reasoning advantage is empirically real.
For agentic workloads, weaker. Token volume in agents is gated by effort level and tool-call overhead, not by model capability. A smarter model running at Max effort burns more tokens than a less-smart model running at High. The right comparison is cost-per-task at the effort level your system prompt defaults to.
Cost-per-token is the headline you see; cost-per-task-at-default-effort is the invoice you’ll get.
What stayed true
The April thesis (Jevons Paradox in action, where falling per-unit cost drives total spend up) is intact and accelerating.
Jevons in plain English: When the steam engine made coal use more efficient, total coal demand went up, not down, because efficiency made coal worth using for new things. Same logic: cheaper tokens get used for more things, total spend keeps rising.
Epoch AI’s 200x/year per-token decline is still tracking. Deloitte’s number (61% of enterprises expecting more than 10 billion tokens per month by 2028) is still tracking. Gartner’s 90% inference cost reduction by 2030 is still tracking. None of this contradicts the headlines about cheaper tokens. It explains them.
Smart routing still works. The 80% Gemini Flash / 20% Claude Sonnet split that cut a $11,880 baseline to $3,432 in April is the same number today, because Gemini held its pricing and Anthropic held its pricing.
The EU AI Act Omnibus deal pushed the August 2026 high-risk obligations to December 2027 (covered in AI Waypoints Edition > 9). For EU enterprises that were treating that deadline as a procurement forcing function, urgency drops. For US enterprises and for finserv globally (where the MAS, FCA, and ECB model-risk rules are unchanged), no impact.
What broke: the assumption that the frontier flagship would be the cheapest place to do frontier work. GPT-5.5 reset that.
The framework, one factor wider
April version: three factors driving enterprise AI cost — procurement channel, volume, architecture.
May version:
Procurement
Procurement decides whether you pay 100% premiums on legacy SKUs (Bedrock, six weeks unchanged).Volume
Volume decides how much Jevons hurts.Architecture
Architecture decides whether a retrieval-augmented generation (RAG) pipeline spends 3-5x on context bloat.Model effort level
Effort level decides which of those token counts is multiplied by 1x, 2x, or 10x.
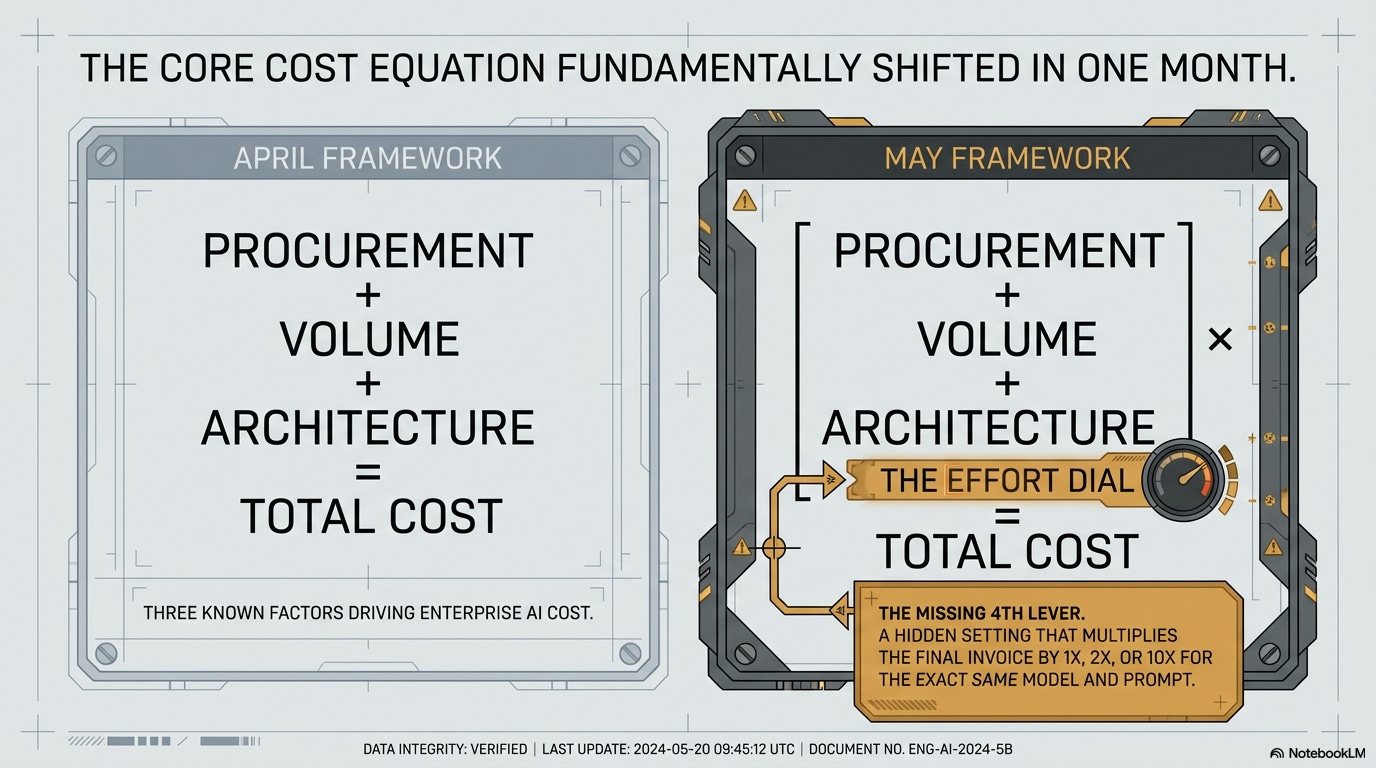
The fourth one wasn’t visible in April because the Anthropic document describing it wasn’t public yet. It’s also the one with the largest unmodeled cost variance: a 10x range on the same model on the same prompt, set in a place most enterprise teams never edit, defaulting to the second-highest position.
What to do differently than I said in April
Three things.
First, audit your effort level today. If your agents started in Claude Code or claude.ai, the default is Extra High. Drop non-critical agents to High. Measure quality. Most teams get 40% off the bill with no measurable production drop. For Claude code users, train developers to use /effort and /model as needed to tune their work.
Second, if Anthropic spend runs through AWS Bedrock, migrate to Claude Platform on AWS (launched May 11). You get current-gen Claude at native pricing without leaving your AWS account. If Bedrock is locked into an existing contract, request current-gen Claude SKUs or move the workload to Claude Platform on AWS. The legacy premium no longer has an excuse.
Third, if you bought a GPT-5.5 plan based on the headline $5 / $30 rate, check whether your contract is Standard or Priority. Production SLAs run on Priority. The real cost is $12.50 / $75. Your CFO needs to know before the first invoice arrives.

My April article argued that falling per-unit prices wouldn’t help, because volume and architecture would absorb the savings. The May refresh adds: the floor is rising faster than I described, and the ceiling is a dial nobody documented.
If a 10x cost multiplier was hiding in a system prompt this whole time, what other dials are buried in the configuration layer at vendors that don’t publish internal playbooks?
References:
The Token Paradox (April 8, 2026): https://ai.kramadoss.com/p/the-token-paradox-why-cheap-tokens
Enterprise AI Benchmarks: May 2026: https://ai.kramadoss.com/p/enterprise-ai-telemetry-may-2026
Anthropic API pricing: https://www.anthropic.com/api
OpenAI API pricing: https://openai.com/api/pricing/
Google AI Studio pricing: https://ai.google.dev/pricing
AWS Bedrock pricing: https://aws.amazon.com/bedrock/pricing/
Anthropic, “The Optimization Engine: Engineering Test-Time Compute in Claude” (internal Tier 1 playbook, Opus 4.7 era)
Epoch AI per-token price decline data
Deloitte AI Institute enterprise token forecasts
Gartner inference cost projections
Stanford HAI 2026 AI Index
EU AI Act Omnibus delay: Council of the EU press release, May 7, 2026