

Enterprise AI Telemetry: May 2026
SWE-bench Verified climbed from 60% to near-100% in a single year. It's now saturated. Six frontier models score above 80%

← The February edition: The Enterprise Leader’s Guide to AI Benchmarks, what changed in 10 weeks →

In February, I argued that most AI benchmarks were saturated, contaminated, or gamed, and that enterprise leaders should pay attention to three: SWE-bench, SimpleQA, and BFCL.
I was half right. The other half got obsolete in 10 weeks. That’s par for the course in this race to Singularity!
The Stanford AI Index 2026 arrived in April. Three frontier models launched between February and May 1: Gemini 3.1 Pro, Claude Opus 4.7, GPT-5.5. SWE-bench Verified went from “the benchmark that matters” to “the benchmark everyone has 85%+ on.”
This is the May edition of a monthly series. It rewrites the February post around a different question: which benchmarks unlock which enterprise decisions, and how those decisions changed since February.
Each benchmark below has a Lexicon (what it actually is), a TL;DR (why anyone should care), and a “How to use it” (the decision it unlocks). Skip the ones that don’t apply to you.
What’s new this month
Stanford AI Index 2026 published (April 2026). 88% of organizations now use AI for at least one function. SWE-bench Verified climbed from 60% to near-100% in a single year. The frontier moved from “can it work?” to “which one, and at what cost?”
Claude Opus 4.7 launched April 16. SWE-bench Verified 87.6%, GPQA Diamond 94.2%, SWE-bench Pro 64.3%. Pricing held at $5/$25 per million input/output tokens (a token is roughly a word or word-piece; pricing is metered per million either sent in or returned by the model). A competitive move while the others raised prices.
GPT-5.5 launched April 23. Terminal-Bench 2.0 82.7%, GDPval wins-or-ties 84.9%, OSWorld-Verified 78.7%. Pricing jumped to $5/$30 (input/output), but the model uses ~40% fewer output tokens for equivalent coding tasks. Net cost for code workloads roughly flat vs. GPT-5.4.
Gemini 3.1 Pro Preview (released February 19) holds the cheapest frontier slot at $2/$12. GPQA 94.1%, MMLU-Pro 89.8%, ARC-AGI-2 77.1%. The intelligence-per-dollar leader by a wide margin.
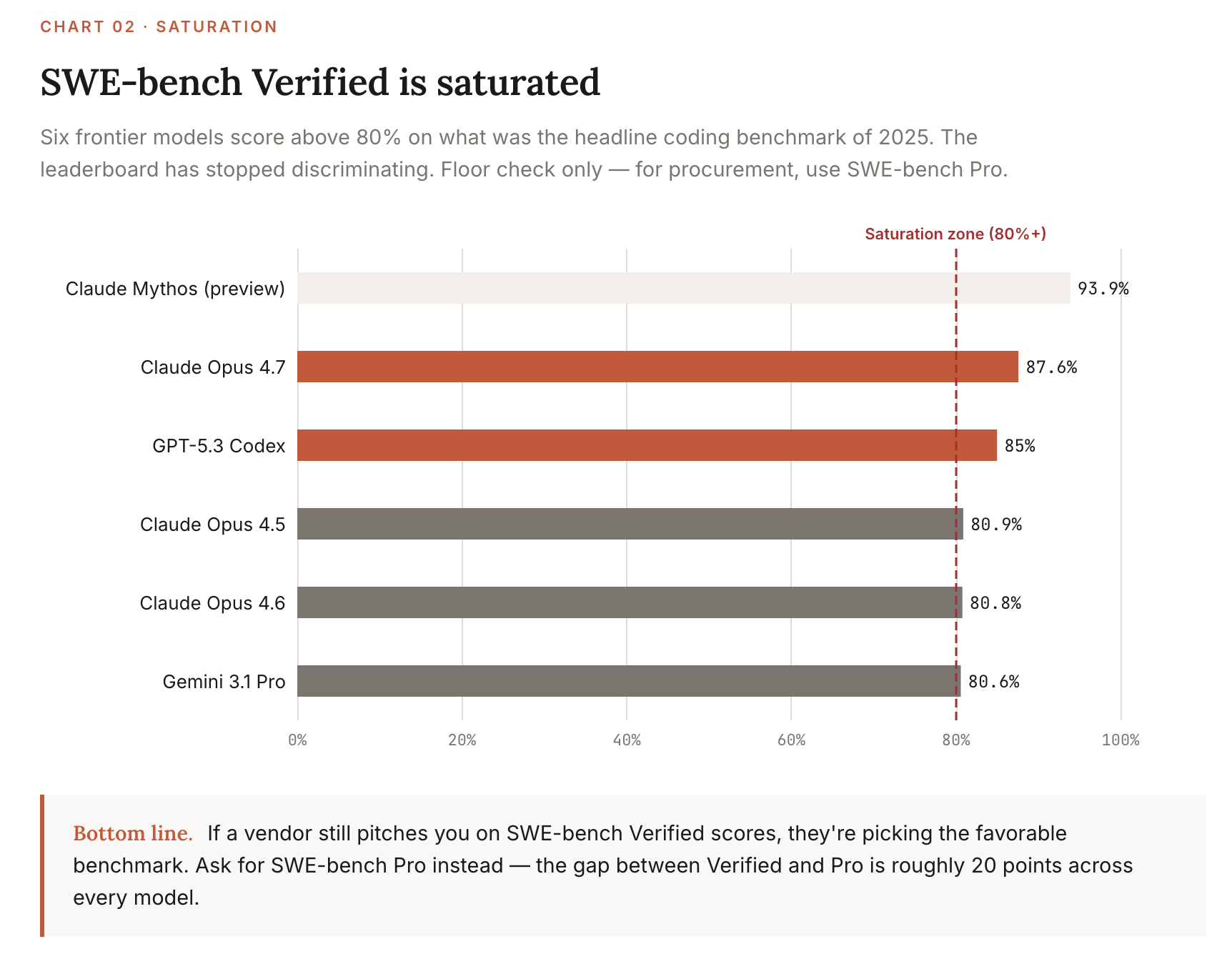
SWE-bench Verified is saturated. Six models score above 80%. The discriminating coding benchmark is now SWE-bench Pro (Scale AI), where the same models drop ~20 points and Claude Opus 4.7 still leads at 64.3%.
The AI Index 2026 in one screen
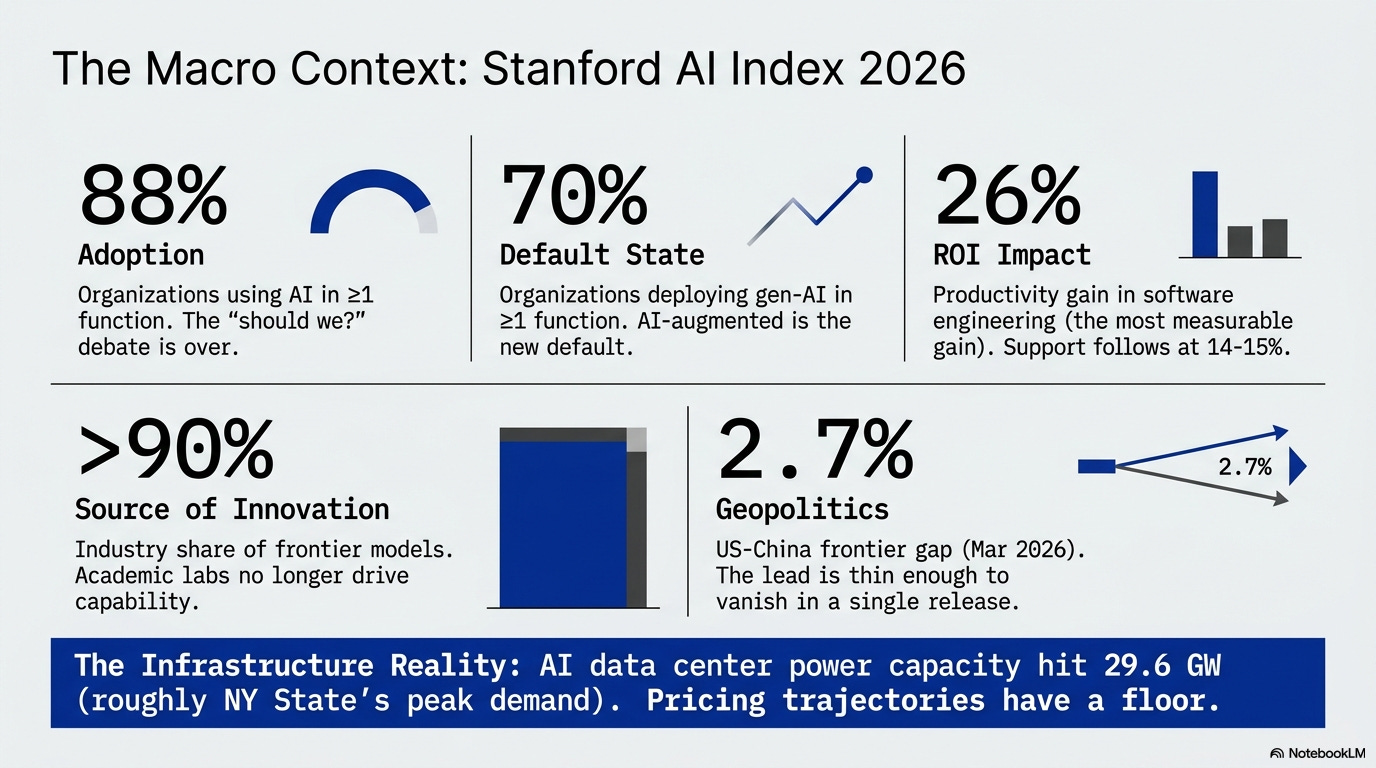
Stanford HAI’s 2026 AI Index is the closest thing the industry has to a yearly AI state-of-the-union. The five numbers I’d put in front of any enterprise board this month:

Two more numbers I think are under-discussed:
The jagged frontier is real. Top models earned IMO gold-medal scores on competition mathematics but read analog clocks correctly only 50.1% of the time. Capability curves are spiky, not smooth, which is why benchmark-by-benchmark evaluation still beats vendor scorecards.
AI data center power capacity hit 29.6 GW, roughly New York State’s peak demand. The pricing trajectory has a floor, and we may already be near it.
The full report is worth reading. The bias toward US-centric data is real, but the methodology is solid and the trend lines are credible.
Source: Stanford HAI, 2026 AI Index Report, April 2026
Benchmarks by decision
I’ve reorganized this section around the four decisions enterprise benchmarks actually serve:
Vendor selection: which frontier model to buy
Deployment scope: what to let an agent do unsupervised
Domain risk: whether a model is safe for your specific industry
Cost defense: when to push back on a vendor’s pricing
If a benchmark doesn’t help you make one of those four decisions, I’ve stopped tracking it.
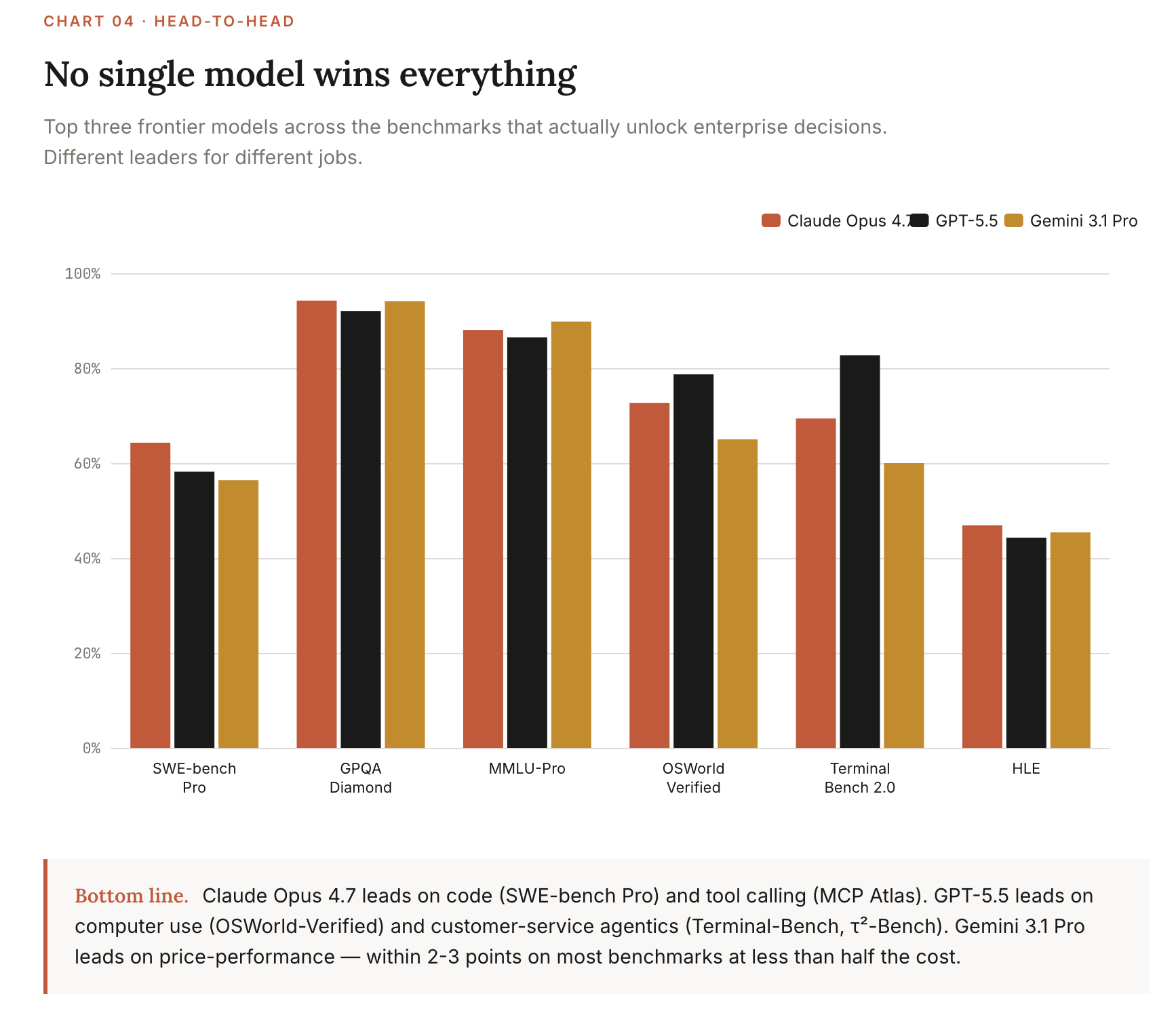
1. For vendor selection (general capability)
These benchmarks tell you which model to anchor your stack on. Most enterprises only need to pick a primary frontier vendor and one fallback. These benchmarks decide that.
MMLU-Pro
Lexicon: A hard general-knowledge test. Multiple choice across academic and professional domains, with 10 answer choices per question instead of the older MMLU’s 4.
TL;DR: This is the broad-reasoning benchmark that hasn’t yet saturated. If you need one number to compare frontier vendors on general intelligence, this is it.
What it measures: Reasoning across 14 academic disciplines including STEM, humanities, law, and medicine, designed to stay hard as models improve.
Current leader & score (May 2026): Gemini 3 Pro Preview (high) at 89.8%, with Claude Opus 4.5 (Reasoning) at 89.5% and Qwen3.6 Plus at 88.5%.
How to use it: Use MMLU-Pro to break ties on general-purpose model selection. If a vendor is ≥3 points behind on MMLU-Pro, it’s a serious general-capability gap. Differences under 2 points are noise.
Source: Artificial Analysis MMLU-Pro Leaderboard, accessed 2026-04-29
GPQA Diamond
Lexicon: Graduate-level science questions designed to be hard for non-specialists even with internet access. The “Diamond” subset is the hardest 198 questions.
TL;DR: This is the model’s “PhD smarter than a smart Googler” test. It correlates well with research-and-synthesis quality on complex enterprise problems.
What it measures: Adversarial expert reasoning across physics, chemistry, and biology. PhD experts hit 65%; skilled non-experts with web access hit 34%.
Current leader & score (May 2026): Claude Opus 4.7 at 94.2%, Gemini 3.1 Pro Preview 94.1%, GPT-5.4 92.0%. Approaching saturation.
How to use it: Use GPQA Diamond when the work involves expert synthesis: research summaries, regulatory analysis, technical due diligence. Don’t use it as a tiebreaker; the top three models are within sampling noise of each other.
Source: Artificial Analysis GPQA Diamond Leaderboard, accessed 2026-04-29
Humanity’s Last Exam (HLE)
Lexicon: A 2,500-question expert-level academic test across mathematics, humanities, and natural sciences. Built explicitly to be the last closed-ended academic benchmark anyone needs to write.
TL;DR: This is where the frontier still has room to run. Top models score 44-47%. Anything claiming “AGI-level reasoning” should be testable here.
What it measures: Reasoning at the limit of human expert knowledge. Many questions require novel reasoning chains, not pattern recall from training data.
Current leader & score (May 2026): Claude Opus 4.7 (Adaptive) at 46.9%, Gemini 3.1 Pro 45.4%, GPT-5.5 (xhigh) 44.3%. (Note: a research preview called Claude Mythos has shown 56.8% on a public snapshot, but it’s gated.)
How to use it: Watch HLE quarterly. It’s the cleanest signal of whether the frontier is still moving on hard reasoning, and the only major benchmark where today’s frontier is genuinely unimpressive. Don’t use it for procurement decisions yet.
Source: Artificial Analysis HLE Leaderboard, accessed 2026-04-29; Nature publication on HLE methodology
2. For deployment scope (agentic capability)
These benchmarks tell you what an AI agent can be trusted to do without a human in the loop. The single biggest deployment question this year is “where does the autonomy line move?” These benchmarks are how you answer it.
SWE-bench Verified
Lexicon: A coding benchmark built from real GitHub issues across open-source Python projects. Models must read the issue, navigate the codebase, and produce a working patch.
TL;DR: This was the benchmark of 2025. It’s now saturated. Useful as a floor (anything under 75% is deprecated), useless as a discriminator at the frontier.
What it measures: End-to-end ability to fix real software bugs autonomously.
Current leader & score (May 2026): Claude Opus 4.7 at 87.6%, GPT-5.3 Codex 85.0%, Gemini 3.1 Pro 80.6%. The AI Index 2026 documents the year-over-year jump from 60% to near-100% as one of the steepest capability gains on record.
How to use it: Floor check only. If a model scores under 75%, don’t use it for code-generation workloads. For frontier comparison, use SWE-bench Pro (below).
Source: SWE-bench Leaderboards, BenchLM SWE-bench Verified, accessed 2026-04-29
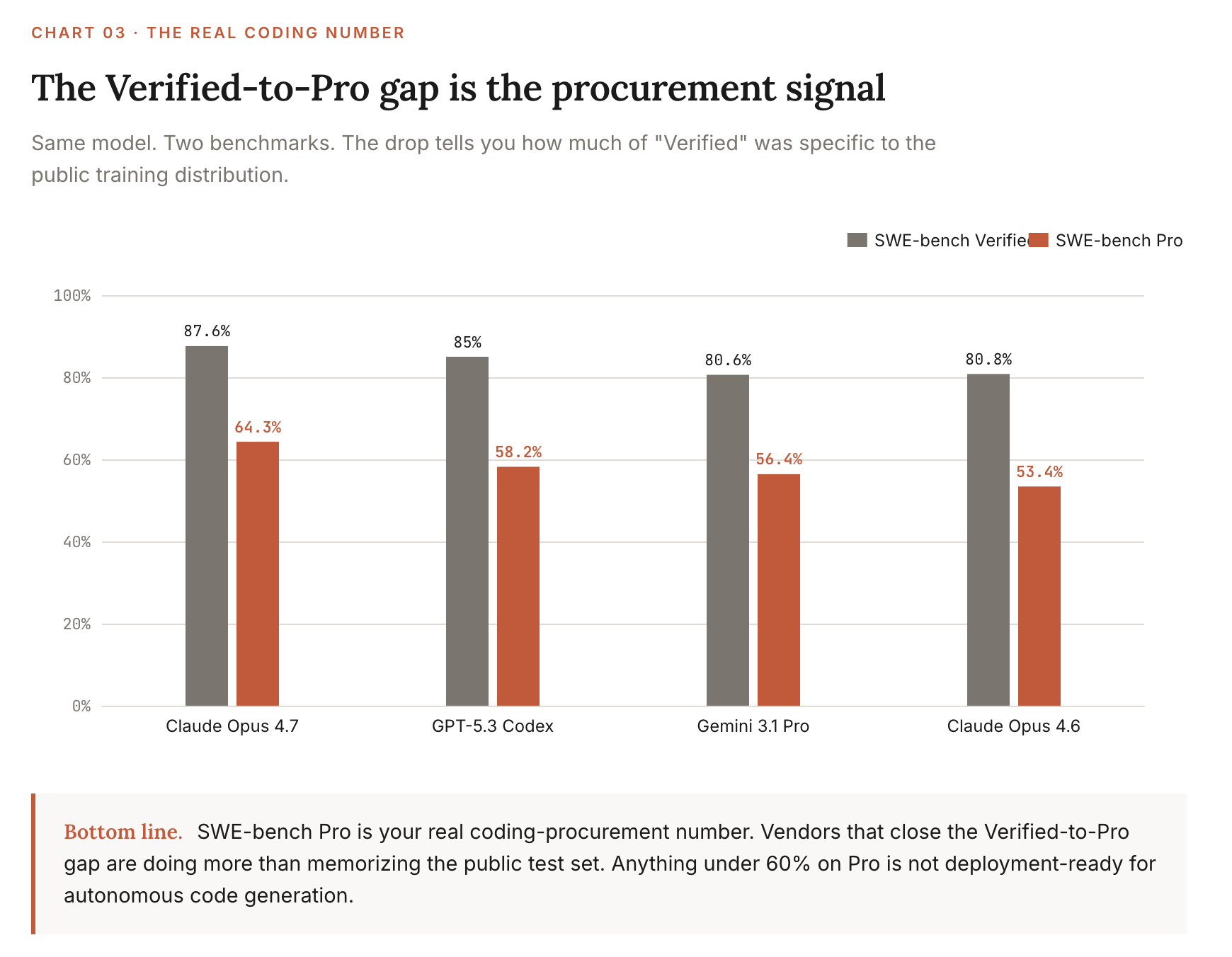
SWE-bench Pro
Lexicon: Scale AI’s harder follow-up to SWE-bench. More languages, harder bugs, stricter evaluation. Sometimes called the “real” SWE-bench among practitioners.
TL;DR: This is the benchmark to watch for code now. Same models that hit 85-87% on Verified drop to 60-64% here. The gap is the size of the leaderboard reshuffle.
What it measures: Code generation across multi-language repositories with tighter correctness checks and adversarial test design.
Current leader & score (May 2026): Claude Opus 4.7 at 64.3%, with all major models clustering 20+ points below their Verified scores.
How to use it: This is your real coding-procurement number. If a vendor only quotes Verified, ask for Pro. The gap is informative. A vendor that closes the Verified-to-Pro delta is doing more than memorizing the public training distribution.
Source: Scale AI SWE-Bench Pro Leaderboard, accessed 2026-04-29
OSWorld-Verified
Lexicon: A computer-use benchmark. The model is given a real desktop environment and must complete tasks like “find this file and email it” using mouse, keyboard, and screen pixels, same as a human would.
TL;DR: This tells you whether an agent can run unsupervised inside the GUI software your enterprise actually uses. It’s the closest thing to a “RPA replacement” benchmark.
What it measures: Multi-step computer-use tasks across browsers, file systems, and productivity software in a verified, reproducible environment.
Current leader & score (May 2026): GPT-5.5 at 78.7%, with specialized vision-tuned models (Holo3-35B-A3B at 82.6%) topping the leaderboard. Claude Opus 4.6 led the standard OSWorld benchmark at 72.7%.
How to use it: Use OSWorld scores when scoping computer-use deployments: RPA replacement, browser automation, desktop assistants. Anything under 65% means the agent will need a human checkpoint roughly every 3 steps.
Source: XLANG Lab OSWorld-Verified, BenchLM OSWorld-Verified, accessed 2026-04-29
τ²-Bench (and Terminal-Bench 2.0)
Lexicon: Two practitioner-favorite agentic benchmarks. τ² (Tau-squared) tests multi-turn, tool-using agents in domains like retail, airline, and telecom. Terminal-Bench 2.0 tests command-line agents in real shell environments.
TL;DR: These are the benchmarks that mirror enterprise customer-service and DevOps deployments most directly. If you’re scoping a chatbot replacement or a SRE assistant, watch these.
What it measures: End-to-end task completion with tool use, policy adherence, and multi-turn conversation in realistic enterprise contexts.
Current leader & score (May 2026): Terminal-Bench 2.0: GPT-5.5 at 82.7%, Claude Opus 4.7 69.4%. τ²-Bench Telecom: GPT-5.5 at 98.0%, with several Chinese models (GLM family) scoring above 98%.
How to use it: Use Terminal-Bench scores for DevOps/SRE agent procurement. Use τ²-Bench Telecom for customer-service agent procurement. Be wary of the GLM scores until you validate them on your own data; that part of the leaderboard is moving suspiciously fast.
Source: Sierra Research τ-bench, Artificial Analysis τ²-Bench, accessed 2026-04-29
MCP Atlas (emerging)
Lexicon: Scale AI’s tool-use benchmark for the Model Context Protocol, Anthropic’s open standard for AI-to-tool integration. Tests whether agents can correctly call external services through MCP.
TL;DR: If your enterprise integration roadmap involves MCP (and increasingly it will), this is the benchmark for it. Currently the cleanest read on agentic tool-call accuracy.
What it measures: Tool-call accuracy, parameter selection, and multi-tool coordination through the MCP standard.
Current leader & score (May 2026): Claude Opus 4.7 at 79.1%, Gemini 3.1 Pro 78.2%, GPT-5.5 75.3%.
How to use it: New benchmark. Track but don’t gate procurement on it yet. The MCP standard itself is still maturing. Revisit in three months.
3. For domain risk (financial services and other regulated work)
Public benchmarks systematically miss domain-specific reasoning. For regulated industries, the benchmarks below are mandatory floor checks. Private benchmarks built on your own data will always be the real test.
FinanceBench
Lexicon: Patronus AI’s financial QA benchmark. The model is given a public-company SEC filing and must answer specific questions like “what was operating margin in FY23?”
TL;DR: This is the closest public proxy for “can the model read a 10-K without making things up?” Best-in-class scores still leave room for error on every fifth question.
What it measures: Open-book financial QA against SEC filings: straightforward extraction, not reasoning over multiple statements.
Current leader & score (May 2026): OpenAI o1-class reasoning models lead at ~67%, with newer frontier models likely higher but not yet systematically evaluated.
How to use it: Mandatory floor for any model touching financial documents. A score under 60% means the model is wrong on more than 4 out of 10 financial questions. Not deployment-ready for any client-facing or compliance-adjacent work.
Source: Patronus AI FinanceBench, arXiv original paper
XFinBench
Lexicon: A graduate-level financial reasoning benchmark with 4,235 questions across statement judgment, multiple choice, and financial calculation. Built from finance textbooks, multi-modal (handles tables and equations).
TL;DR: This is the harder financial test. Where FinanceBench checks if the model can read filings, XFinBench checks if it can do graduate-level financial reasoning.
What it measures: Financial calculation and judgment across diverse graduate-level topics: corporate finance, investments, derivatives, risk management.
Current leader & score (May 2026): Frontier model evaluations remain partial; assume nothing scores above 70% until you see verified numbers.
How to use it: Use XFinBench when scoping models for analyst-augmentation or research workflows. Pair with a private benchmark on your own deal documents. Public XFinBench scores don’t predict performance on proprietary data formats.
Anthropic’s Finance Agent benchmark (private)
Lexicon: Anthropic’s internal evaluation for Claude on financial agentic tasks: multi-step workflows like “build a DCF model from these filings.”
TL;DR: Vendor-published, so handle with skepticism. But the year-over-year delta is informative even if the absolute number isn’t.
What it measures: End-to-end financial-agent task completion with tool use.
Current leader & score (May 2026): Claude Opus 4.7 at 64.4% (vs. 60.7% for Opus 4.6).
How to use it: The 4-point year-over-year improvement is the takeaway. Vendor benchmarks are unreliable for cross-vendor comparison but useful for tracking single-vendor capability evolution.
Source: Anthropic Claude Opus 4.7 announcement, April 2026
4. For cost defense (price-performance)
Benchmark scores tell you what’s possible. Pricing tells you what’s affordable. The benchmarks-per-dollar question is the one most procurement teams aren’t asking. Vendors prefer it that way.
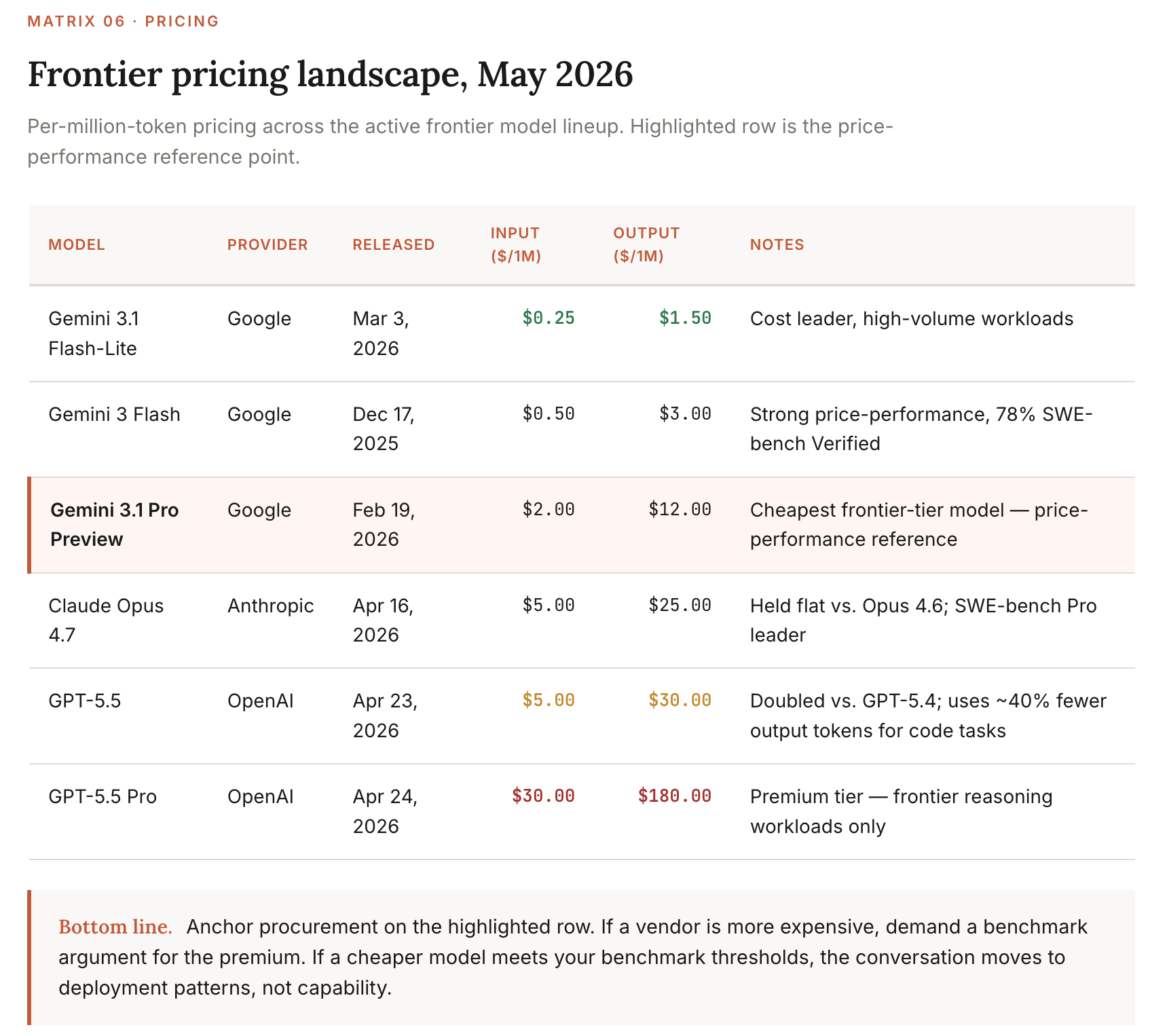
Pricing landscape (May 2026)
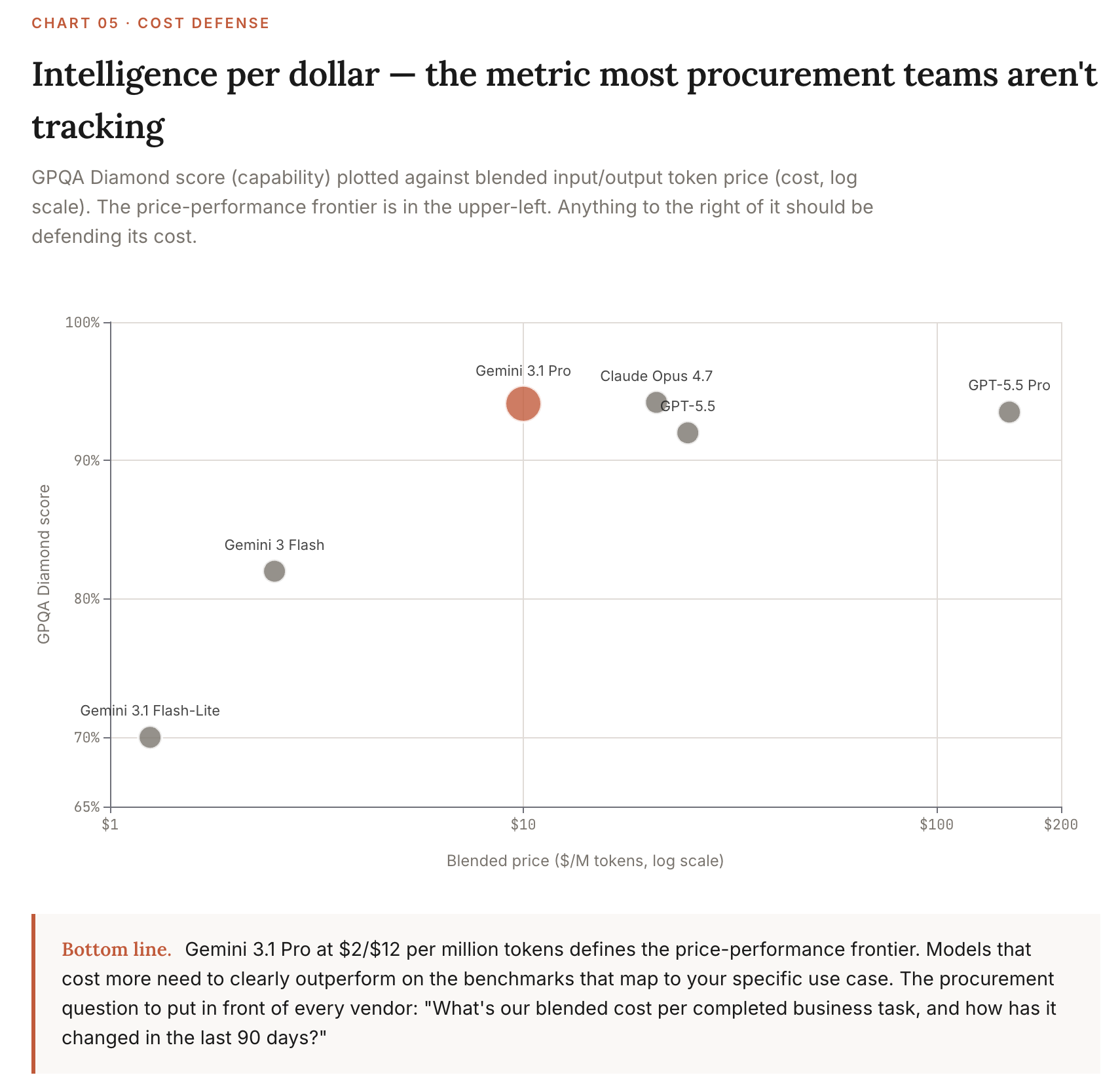
Intelligence-per-dollar (the metric that matters)
The metric that matters in pricing is the ratio of capability to cost, not absolute cost. The token economics that matter for enterprise:
Per-token inference prices have fallen ~200x per year since January 2024, per Epoch AI. The median rate over the longer term is closer to 50x. Either way, a workload that cost $1,000/month a year ago costs single-digit dollars now.
Total enterprise AI spend has risen 320% over two years despite per-token prices falling 280x. The reason: agentic workflows consume 10-100x more tokens per task than chat workflows. Cost per token down. Tokens per task way up. Net cost up.
Gemini 3.1 Pro at $2/$12 is the price-performance frontier for general-purpose workloads. It’s within 2-3 points of Opus 4.7 on most reasoning benchmarks at less than half the cost.
GPT-5.5’s price hike is partially compensated by 40% lower output token use on coding tasks, but only on coding. For chat-style workloads, GPT-5.5 is genuinely more expensive than GPT-5.4.
How to use this: When a vendor pitches you, ask for benchmarks-per-dollar, not benchmarks. If they can’t or won’t compute it, they’re not pricing competitively. The cost-defense question to put in front of every procurement: “What’s our blended input/output cost per completed business task, and how has it changed in the last 90 days?”
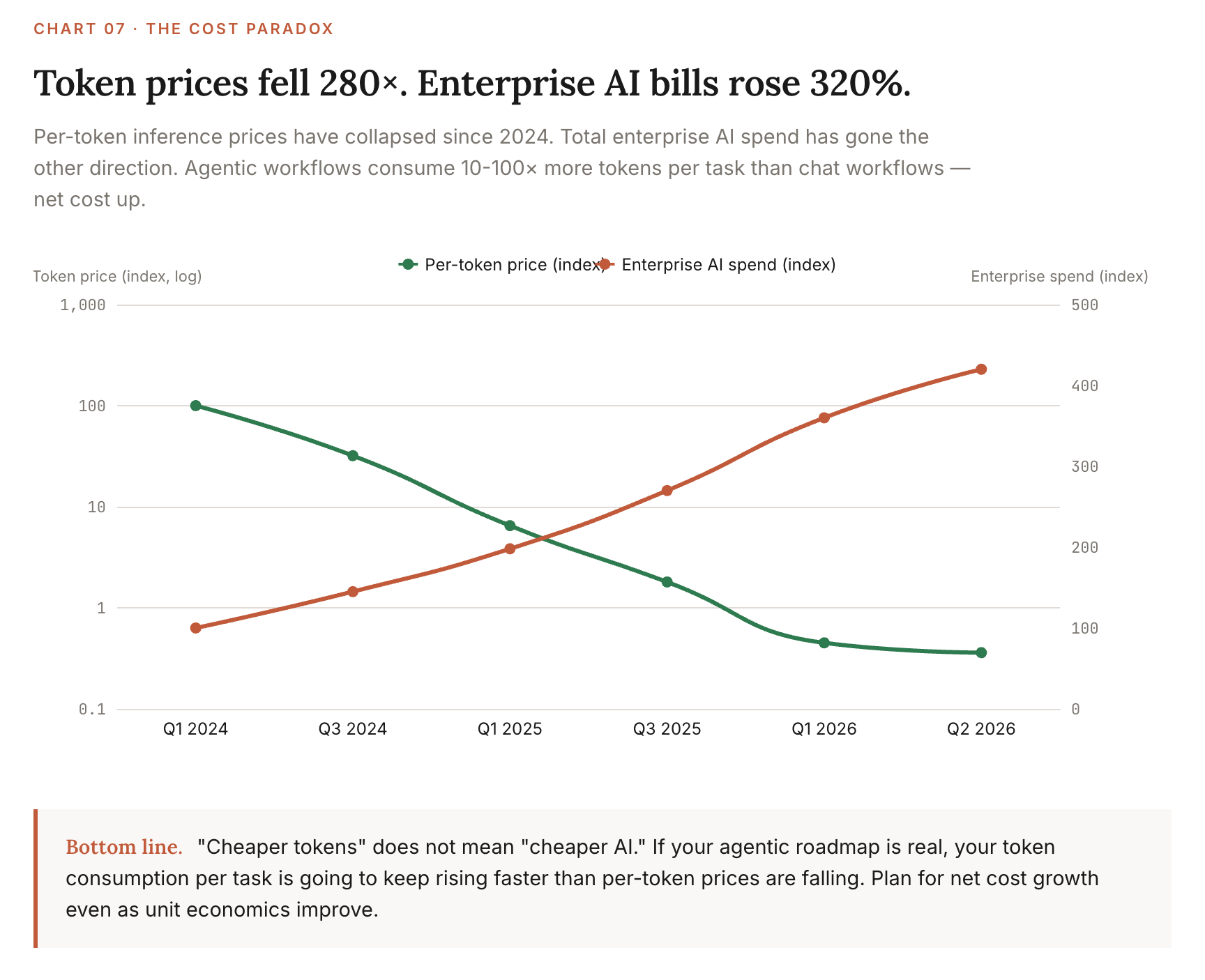
Sources: Epoch AI LLM inference price trends, Anthropic pricing, OpenAI pricing, Google Vertex AI pricing, accessed 2026-04-29
What changed since February
The compressed delta. Only entries where something material moved.
Benchmark February 2026 leader May 2026 leader What changed SWE-bench Verified Gemini 3.1 Pro / Opus 4.6 cluster ~80% Opus 4.7 at 87.6% Saturated. Move to SWE-bench Pro for procurement. GPQA Diamond Tightly clustered ~91% Opus 4.7 94.2%, Gemini 3.1 Pro 94.1% Approaching saturation. HLE Frontier ~44% Frontier ~46-47% Slight movement. Still where the room to run is. OSWorld Claude Opus 4.6 ~73% GPT-5.5 78.7% (Verified subset) Verified split adopted. Use Verified scores only. Frontier pricing (mid-tier) Claude Opus 4.6 $5/$25 Multiple models $2-$5 input Gemini 3.1 Pro is the new price-performance benchmark. Frontier pricing (top-tier) GPT-5.4 $2.50/$15 GPT-5.5 $5/$30 OpenAI raised prices. Anthropic held flat.
Updated May 2026. Re-check quarterly.
Emerging benchmarks to watch
MCP Atlas (Scale AI): tool-use accuracy through the Model Context Protocol. As MCP becomes the de-facto integration standard, this benchmark will matter more than BFCL within two quarters.
ARC-AGI-2: second generation of the Abstraction and Reasoning Corpus. Designed to resist saturation. Gemini 3.1 Pro at 77.1%, the first time a frontier model has cleared 70%.
FrontierMath Tier 4: Epoch AI’s hardest math test. GPT-5.5 (xhigh) at 35.4%. The room-to-run benchmark for quantitative reasoning.
GDPval: OpenAI’s professional-task benchmark, evaluating model performance on white-collar work tasks. GPT-5.5 wins-or-ties 84.9% of evaluations against human professionals. Still vendor-published, so handle with care.
Red flags this month
SWE-bench Verified is contaminated by saturation. Six models score above 80%. The benchmark has stopped discriminating. Vendors who quote Verified scores instead of Pro scores are picking the favorable benchmark.
GPQA Diamond is approaching saturation. Top three models within 0.1% of each other. Stop using it as a tiebreaker; the differences are inside the noise floor.
Vendor-published benchmarks remain the dominant source for many specialized capabilities. Anthropic’s Finance Agent number, OpenAI’s Expert-SWE, Google’s MMMLU: all useful directionally, none usable for cross-vendor comparison.
Chinese model scores on agentic benchmarks (GLM family, Qwen3) are climbing faster than independent verification can keep up. Three GLM variants score above 98% on τ²-Bench Telecom. Either there’s a real capability frontier shift happening, or there’s benchmark contamination (the model trained on data that overlapped the test set). Both are plausible. Validate on your own data before any procurement decision.
The 1M-token context windows are not free. Gemini 3.1 Pro and GPT-5.5 both ship with 1M context, but pricing is per token consumed, not per token provisioned. Long-context queries cost real money. The “we’ll just stuff the whole knowledge base into context” pattern is more expensive than it looks.
What enterprise leaders should do this month
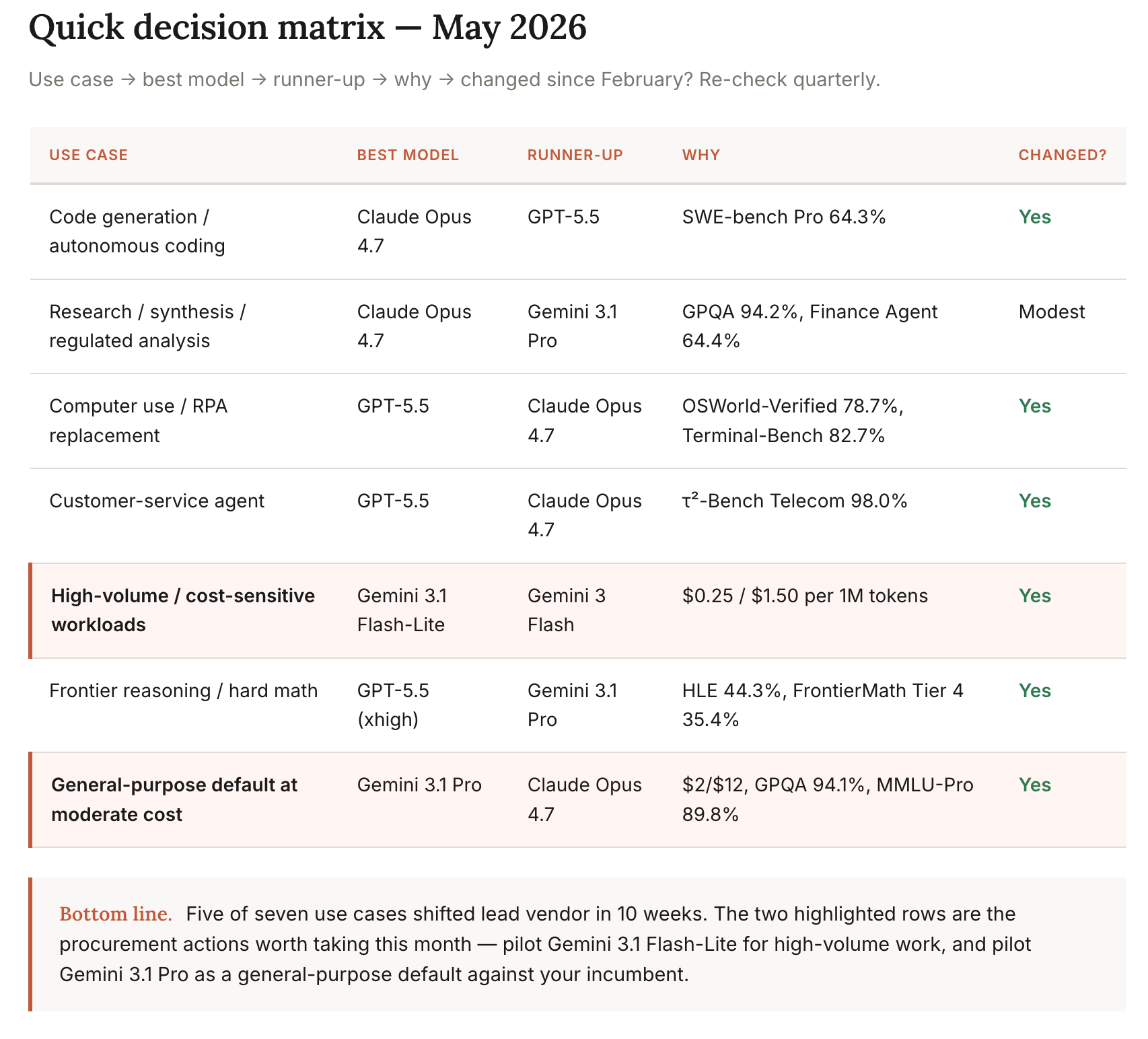
Update your benchmark stack to match the May 2026 reality. If your procurement decks still cite SWE-bench Verified, MMLU classic, or HumanEval, replace with SWE-bench Pro, MMLU-Pro, and the relevant agentic benchmark for your use case.
Run a benchmarks-per-dollar exercise on your top three vendors. Multiply input/output token volume by current pricing. Compare. The price-performance ranking has shifted; the procurement contracts you signed in Q4 2025 are probably renegotiable.
Build a private benchmark on your own data this quarter. Public benchmarks predict average-case performance on average-case problems. Your enterprise has neither. The 100-prompt private eval is the single highest-ROI investment in AI procurement discipline.
Pilot Gemini 3.1 Pro against your incumbent for at least one workload. At $2/$12 it’s the cheapest frontier model. The risk-adjusted procurement question this month is “why are we paying 2-5x more than this baseline?”
Read the AI Index 2026 yourself. Stanford HAI’s report is the cleanest source on the state of the industry. Skim time: 30 minutes. Better than any vendor briefing you’ll get this quarter.
Previous editions
February 2026: The Enterprise Leader’s Guide to AI Benchmarks
Next month: how the AI Index’s 28.3% US adoption number maps onto enterprise sectors, and which industries are systematically over- and under-represented in benchmark coverage.
Sources & methodology
All scores verified against ≥2 independent sources where possible. Where only one source was available, the benchmark entry notes it.
Primary leaderboards consulted:
Artificial Analysis, accessed 2026-04-29
SWE-bench Leaderboards, accessed 2026-04-29
Scale AI SWE-Bench Pro Public, accessed 2026-04-29
BenchLM, accessed 2026-04-29
llm-stats.com, accessed 2026-04-29
Berkeley Function Calling Leaderboard (BFCL), accessed 2026-04-29
XLANG OSWorld-Verified, accessed 2026-04-29
Epoch AI benchmarks, accessed 2026-04-29
Primary first-party sources:
Stanford HAI 2026 AI Index Report, April 2026
Anthropic, Introducing Claude Opus 4.7, April 16, 2026
OpenAI, Introducing GPT-5.5, April 23, 2026
Google, Gemini 3.1 Pro and Flash announcements, February-March 2026
Methodology notes:
All pricing as of May 1, 2026, based on official vendor API pricing pages
Where multiple variants of a model exist (high/low/Adaptive), the highest publicly tested score is reported with the variant noted
Research-preview models (e.g., Claude Mythos) are mentioned for context but not used as the lead score for any benchmark. Gating distorts comparison.
Scores marked † indicate single-source verification
Hit reply with the benchmark you’d add to next month’s edition. I’ll work the best one in.