

Vibe and Agentic Coding Security: The Buying Discpline (Part 3b)
How to evaluate any agentic coding security vendor without committing to a category that's renaming itself quarterly.

The piece in one paragraph: Part 3a gave you a capability framework built from comparing 66 vendor offerings. This piece is the buying discipline that goes with it. 11 diligence questions you can use as a market read.
The story so far — read the series:
→ Part 1 — Every Way In: The Complete Attack Taxonomy for Vibe Coding and Agentic AI
7 attack vectors against AI coding agents: supply-chain compromises (Axios, Shai-Hulud, TanStack), slopsquatting via hallucinated package names, indirect prompt injection through repo files, MCP server poisoning, blast-radius amplification (PocketOS: 9 seconds to full data loss with no attacker required), and an accountability vacuum that SOC2 / DORA / EU AI Act don’t yet cover.
→ Part 2 — The Defense Stack: How to Build Security That Runs at Agent Speed
7 control layers mirroring those attacks, collapsed to three mandatory human checkpoints (before any AI-suggested package install, before AI-generated code merges to main, before any agent action affects production).
→ Part 3a — The vendor question: I promised you a map. I changed my mind.
The capability framework: 66 vendor offerings sorted across the 7 layers, with a verdict for each layer (consolidating, fragmenting, absent). Three capabilities (provenance-aware behavioral trust, approval-fatigue resistance, tamper-evident agent logs) that nobody publicly ships today.
→ Part 3b (this piece): the buying discipline — 11 diligence questions (one or more per capability), three eighteen-month bets, a ninety-day plan.

Why this isn’t a vendor list
Two facts about the agentic coding security market in May 2026 explain the shape of this piece.
The consolidation is happening faster than the market is growing organically. 10 leading pure-plays absorbed across roughly eighteen months, with the pace picking up: Astrix into Cisco on May 4, 2026, around $400M.
A vendor shortlist published today is a snapshot of a category renaming itself quarterly.
Every trust mechanism shipped into this market in the last eighteen months has been broken or bypassed in production at least once. SLSA provenance (TanStack). Sandboxes (Claude Code’s SOCKS5 hostname-null-byte bypass disclosed May 20, 2026; quietly patched in v2.1.88 on March 31, 2026 after about 5.5 months in production with no security note in the release notes. Same pattern at Cursor, Antigravity, Windsurf). Signed commits (TanStack again). MCP allowlists and the MCP STDIO transport itself (OX Security’s April 15, 2026 disclosure: 150M+ downloads, 7,000+ publicly accessible servers across Cursor, VS Code, Windsurf, Claude Code, and Gemini-CLI;
Anthropic confirmed the behavior is by design and declined to change the protocol). AI PR reviewers (CodeRabbit RCE to roughly one million repositories).
Both push toward the same answer: what lasts for a buyer in 2026 is a discipline, not a list. Here it is.
Part B — The diligence playbook
11 questions, each one pointed at a trap-door pattern that showed up while I was writing the Part 3a capability dossiers. None are invented; every one points at a gap the cohort analysis showed. The structure mirrors Part 3a one-to-one: questions are grouped by Capability 1 through 7, so a vendor pitching at a given layer answers the questions for that layer.
Score every answer against three categories:
table stakes (any serious vendor in the layer should be able to answer),
differentiator (a yes here separates real solutions from positioning),
trap door (the answer pattern that should make you walk).
Question-to-capability map
Each question points back to the capability it tests. Capability numbers and names match Part 3a exactly. The right-hand column is the original layer label from Part 2’s Defense Stack.
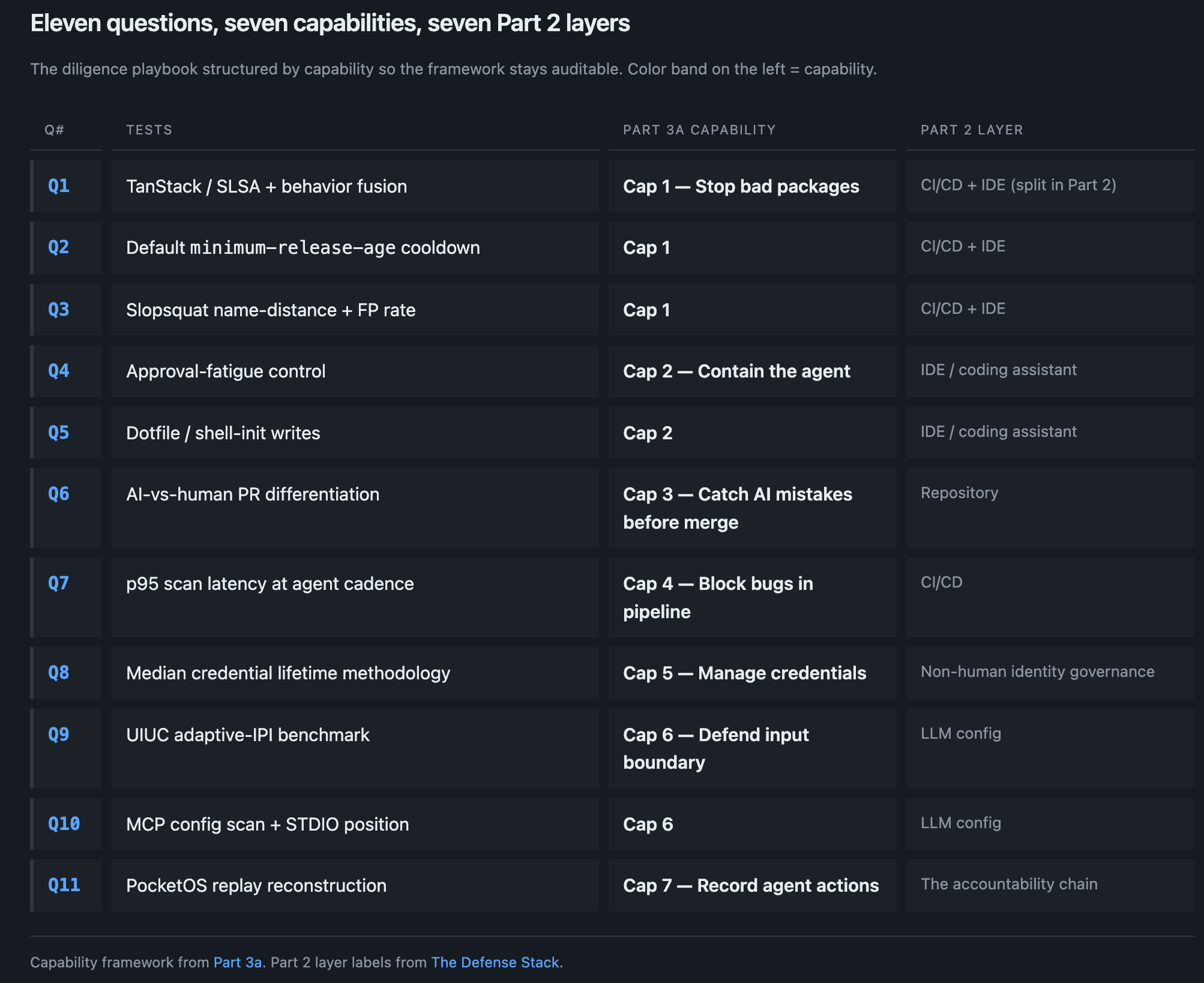
Capability 1 — Stop bad packages before they install
Part 3a Cap 1 · Part 2 layers: CI/CD + IDE (supply-chain controls were distributed across both)
Q1. Show me how your product handled the TanStack May 11, 2026 case, where SLSA Build L3 attestation was valid and the payload was malicious.
The cohort’s “valid provenance equals trust” assumption is now a documented attack pattern. Vendors who said SLSA was the answer have to reconcile.
Trap door: “We verify SLSA attestations” as the full answer. Attestation verification is the right starting layer for an honest vendor; Anchore, Endor Labs, and Snyk all start there because that’s the layer they own. The trap is silence after the first sentence. Give the rep the follow-up: “Right. And after attestation, what fired on TanStack?” If the answer stops at “we verify SLSA,” walk.
Verifiable answer: the vendor demonstrates a behavioral signal (age, install behavior, anomalous CI egress, maintainer reputation) that fired despite the green provenance. That’s the pass. Almost no vendor publicly ships the fusion of attestation verification and behavioral anomaly into a single trust score, so a clean acknowledgement (”we verify attestation, and here’s the behavioral layer we pair it with, or here’s the gap and how we’d compensate”) is the next-best honest answer.
Q2. What is your default minimum-release-age for packages an autonomous agent installs?
pnpm v10.16+ (default in pnpm 11), Yarn v4.10+, and npm v11.10+ ship minimumReleaseAge cooldown controls (off by default). Aikido Endpoint productized 48 hours at the workstation. Socket Firewall defaults to a sub-48-hour deny window. No SCA vendor in the cohort advertises a default cooldown as part of their product.
Trap door: “We detect malicious packages.” That’s the wrong question. Slopsquatted names are net-new and not in any signature database.
Verifiable answer: a specific number (24 hours, 48 hours, 72 hours), with documentation of where it is enforced (registry proxy, workstation, or CI gate) and a published default-deny versus default-warn policy.
Q3. What is your name-distance detection algorithm for slopsquatted package names, and what is the false-positive rate?
The 2025 USENIX study put LLM hallucinated-package rates near 20%. Sonatype’s 2026 dataset showed 27.75% on dependency upgrades. Slopsquatted names are net-new; signature databases don’t catch them.
Trap door: “We use AI to detect malicious packages.” Opaque, unfalsifiable, untestable.
Verifiable answer: a documented heuristic (Levenshtein distance + downloads ratio + age, the way Socket.dev publishes didYouMean), with a published false-positive rate. Bonus if the vendor can show a real-world catch like Socket’s March 2026 litellm detection.
Capability 2 — Contain what the AI agent can do
Part 3a Cap 2 · Part 2 layer: IDE / coding assistant
Q4. What is your control for the approval-fatigue exploit class, where the agent asks the user to widen its own permissions and the user clicks allow? Calibrated for honesty, not capability. The cohort hasn’t solved this; the question tests whether the vendor admits it.
Anthropic’s own Claude Code engineering data (March 25, 2026 auto-mode write-up) puts the human-approval rate at 93% on permission prompts. Almost every time Claude asks, the developer says yes. Ona’s sandbox-escape research from the same month showed agents bypassing the sandbox without even asking. No vendor in the cohort has shipped a fix for either side of that approval-fatigue dynamic. It’s the cohort-wide unsolved problem.
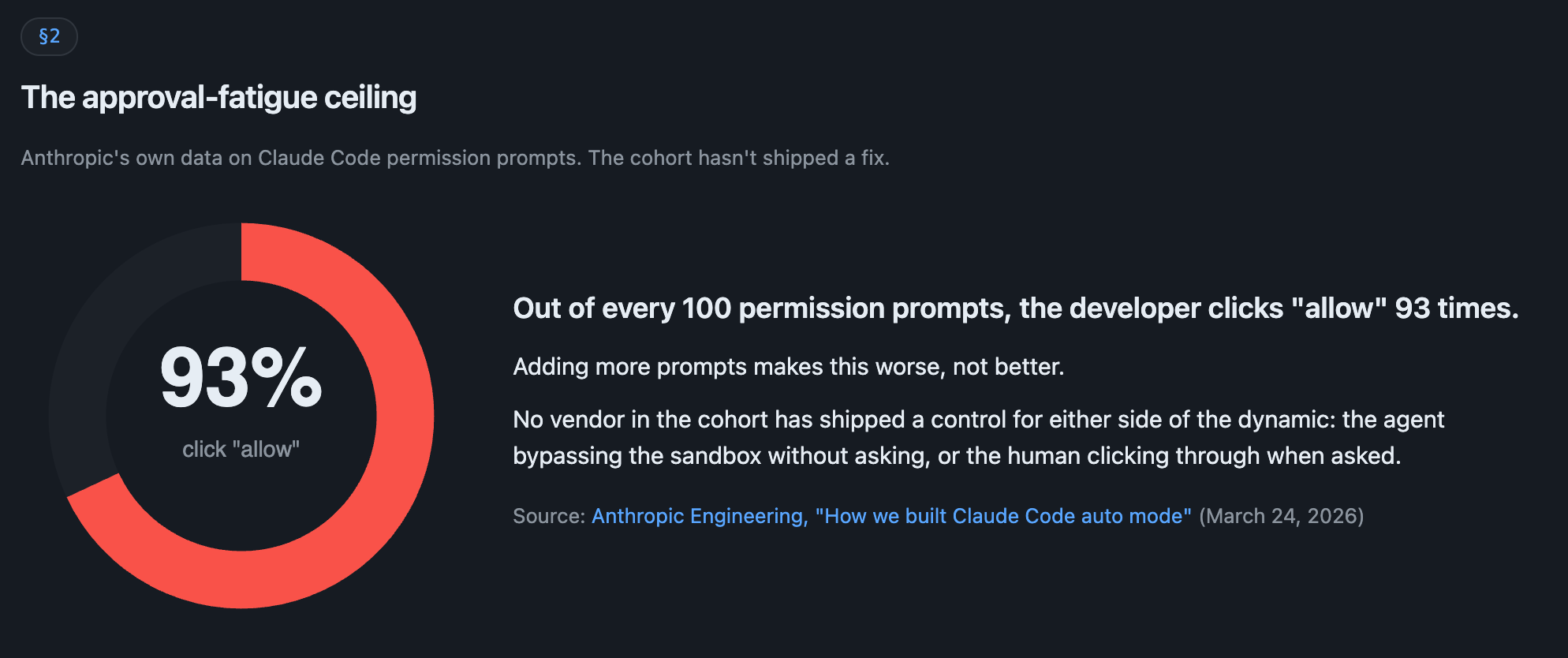
Trap door: claiming the problem is solved via “mandatory approval prompts.” That’s the cause of approval-fatigue, not the cure.
Verifiable answer: a control that breaks the symmetry, like a separate approver out-of-band, a cooldown on widening-permission requests, a budget on approvals per session, or an honest “we don’t solve this, here’s what we mitigate.” Honest acknowledgement is a pass; claimed solution is the trap.
Q5. What happens when an agent in your IDE writes to ~/.bashrc, ~/.zshrc, or another shell init file?
The CurXecute and Agent Security Paradox classes both included write-to-dotfile vectors. Cursor pre-1.3.9 required no approval for this; the shell-built-in env-poisoning bypass walked through an empty allowlist.
Trap door: “Our sandbox restricts file system access.” Vague, and demonstrably unreliable. Claude Code, Cursor, Antigravity, and Windsurf have all shipped sandboxes broken in production within the last twelve months. Anthropic’s own Claude Code shipped a network sandbox bypassable via SOCKS5 hostname null-byte injection for ~5.5 months until v2.1.88 (March 31, 2026), silently patched with no security note in the release notes. “We have a sandbox” is necessary but not sufficient. The question is which specific path the agent can plausibly need, and whether the sandbox claim has been independently tested against that path.
Verifiable answer: a specific path-pattern policy with an approval prompt or block, plus documentation of the shell-built-in bypass class and how the IDE handles it.
Capability 3 — Catch AI mistakes before the merge
Part 3a Cap 3 · Part 2 layer: Repository
Part 3a flagged Capability 3 as the only layer where the cohort is converging. GitGuardian, GitHub Advanced Security, and Aikido approximate table stakes when combined with an AI PR reviewer. That makes vendor selection easier. It doesn’t make the diligence easier, because the PR gate is at once the highest-leverage control in the stack and the most attractive target.
Q6. How does your repo gate tell AI-generated PRs apart from human-generated PRs, and what additional checks fire on the AI ones?
CodeRabbit’s own published data (Part 3a): AI-co-authored PRs carry 1.7x more issues and an XSS rate 2.74x the human baseline. GitGuardian 2026: Claude-Code-assisted commits leak secrets at 3.2%, versus a 1.5% GitHub baseline. And CodeRabbit’s own product became the breach. A disclosed RCE gave attackers read/write to roughly one million repositories. AI commits are statistically riskier and the reviewing layer is itself an active attack target. The gate has to tell them apart so you can apply the right level of scrutiny.
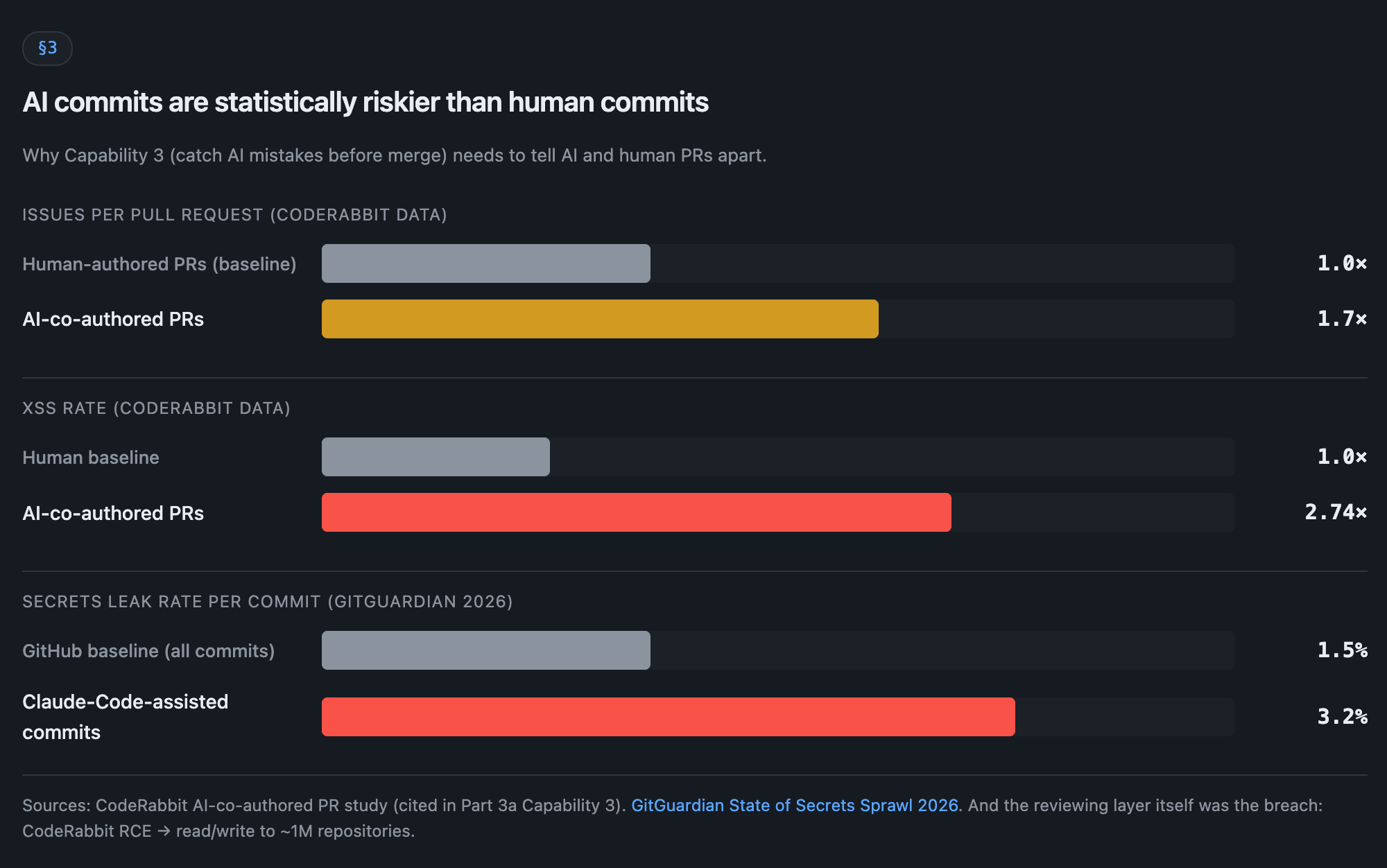
Trap door: “CODEOWNERS handles it.” CODEOWNERS routes a PR to a reviewer. It doesn’t distinguish whether the committer was a human or an autonomous agent. GitHub is “evaluating” AI attribution and has shipped nothing as of May 2026. Equally a trap: “we treat all PRs the same.” That’s the default failure the data above is measuring.
Verifiable answer: a documented mechanism for tagging AI-authored commits (commit-trailer convention, GitHub App provenance, or a repo-side classifier), plus an enforced policy that AI PRs face additional checks: mandatory human review even on small diffs, stricter SAST or secret thresholds, branch protection that excludes the bot account from self-merge. Bonus points if the vendor documents how it hardens against the CodeRabbit-class compromise (read-only mode by default, scoped GitHub App permissions, supply-chain attestation on the reviewer container).
Capability 4 — Block AI-generated bugs in the pipeline
Part 3a Cap 4 · Part 2 layer: CI/CD
Q7. What is your p95 scan latency on a PR that an agent commits at machine cadence? Calibrated for honesty about backstop-vs-inline positioning, not for a sub-30-second number no SAST vendor currently publishes.
SAST that runs in minutes-to-hours is mismatched with agents committing in seconds. Either the gate is bypassed or the backlog explodes. Every SAST vendor is currently a backstop, not an inline gate; the one who ships an agent-cadence SLO first owns this layer.
Trap door: “We scan on every PR.” Doesn’t address latency.
Verifiable answer: a specific latency SLO (say, p95 under 30 seconds on a 1,000-line diff) with a reference customer running it at agent cadence. That’s the rare full pass. Or honest acknowledgement that the SAST is a backstop, plus a recommendation for what to run inline in the meantime. Both are passes. Claimed inline gating without a number is the trap.
Capability 5 — Manage the credentials your agents hold
Part 3a Cap 5 · Part 2 layer: Non-human identity governance
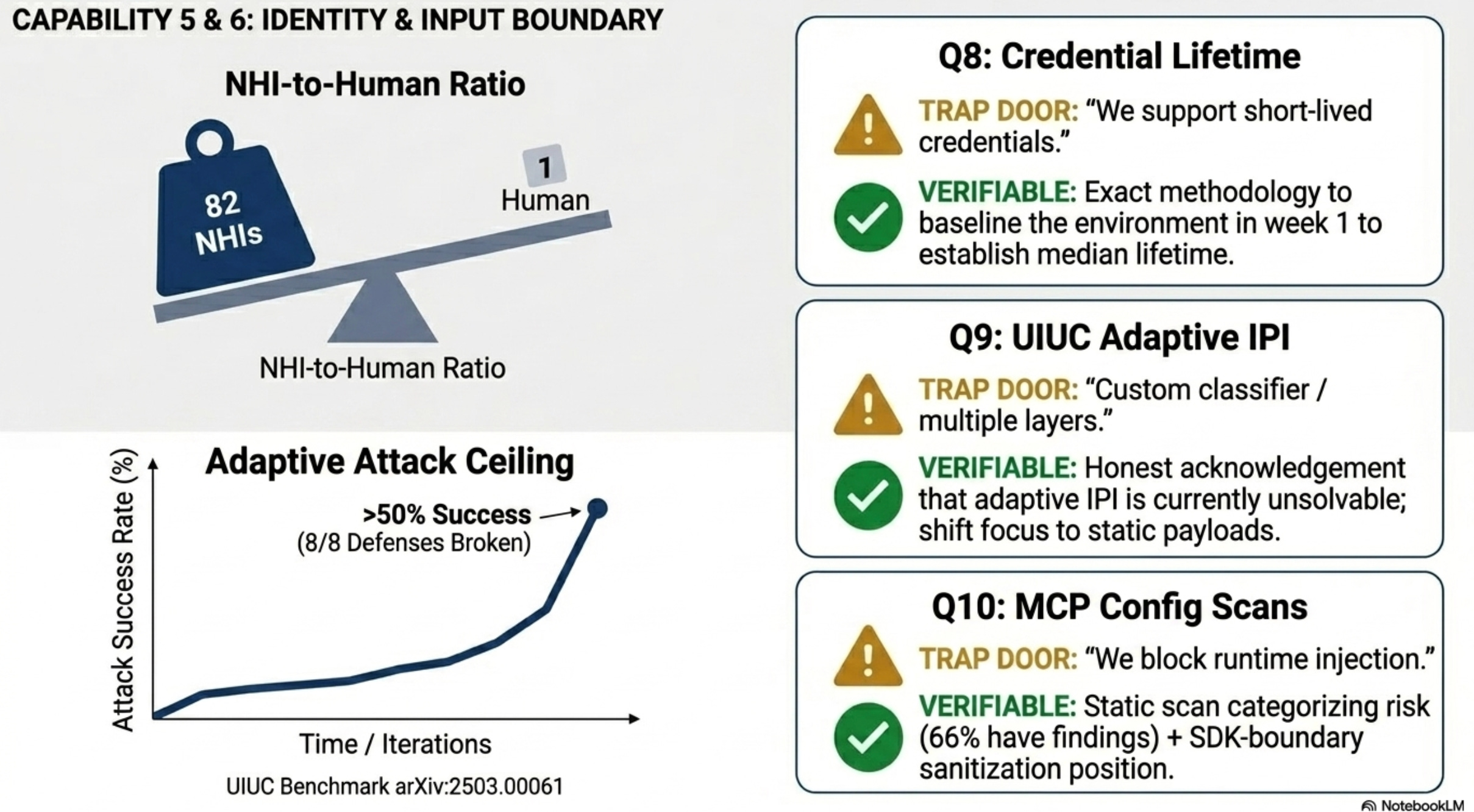
Q8. What is the median credential lifetime for an agent in my environment after I deploy your product? Calibrated for methodology, not for a cross-customer published number. No vendor publishes that yet.
Aembit’s 2026 survey: 80.9% of teams have agents in test or production; only 21.9% treat them as identity-bearing entities. The 82:1 NHI-to-human ratio is the scale problem. Per-request authorization needs to be measurable, not aspirational.
Trap door: “We support short-lived credentials.” Capability claim, not outcome claim. Also a trap: claiming a published cross-customer median that no vendor actually has.
Verifiable answer: the methodology the vendor would use to baseline your environment in week one, with a target median and p95 they’d commit to by week four. If they can’t tell you how many NHIs they discovered that you didn’t know existed, the rotation feature is theater.
Capability 6 — Defend the AI’s input boundary
Part 3a Cap 6 · Part 2 layer: LLM config
Q9. What is your performance against the University of Illinois adaptive indirect-prompt-injection benchmark (arXiv:2503.00061)?
The UIUC paper broke all eight tested defenses with greater than 50% attack success rate. OWASP’s 2025 LLM Top 10 states explicitly that no fool-proof method exists.
Trap door: “We use multiple defense layers” or “we have a custom classifier.” Neither addresses the adaptive-attack ceiling.
Verifiable answer: a published benchmark, or honest acknowledgement that adaptive IPI isn’t currently solvable plus documentation of what they do detect (static payloads, indirect-injection vectors, MCP poisoning).
Q10. Scan one of my real MCP server configs for tool-description poisoning, cross-origin escalation, and rug-pull risk. What do you find?
AgentSeal’s 1,808-server census found 66% of MCP servers had at least one finding. Tool-description poisoning is a real attack vector static scan tools detect, and most vendors don’t ship one. AgentSeal and Snyk MCP-Scan do; that’s the table-stakes answer.
Trap door for the table-stakes question: “We block prompt injection at runtime.” Different layer.
Verifiable answer: a scan output with categorized findings (shell/command injection, auth bypass, path traversal, etc.). If the vendor doesn’t scan MCP configs at all, an honest “we don’t” and a pointer to who does.
Then widen the question. The OX Security April 15, 2026 disclosure found a by-design flaw in the reference MCP STDIO transport across Anthropic’s official SDKs (150M+ downloads, 7,000+ public servers) where unsanitized commands execute silently regardless of whether the spawned process succeeds. Anthropic confirmed the behavior is by design and pushed sanitization onto SDK consumers. Windsurf was the only IDE where exploitation needed zero user interaction (CVE-2026-30615). Scanner vendors can’t patch the protocol (Anthropic owns it), but a sharp vendor should have a position. Ask: “If the protocol itself is the attack surface, what do you do?” Differentiator answer: a sanitization layer at the SDK boundary, a non-STDIO transport mode for sensitive servers, or honest acknowledgement of the gap with a pointer to who is solving it. Trap-door at this layer: “MCP is Anthropic’s problem” with no compensating control.
Capability 7 — Record what the agent actually did
Part 3a Cap 7 · Part 2 layer: The accountability chain
Q11. Show me the replay of a PocketOS-class destructive action from your usage data.
April 25, 2026. Nine-second database and backup deletion. No vendor in the cohort has shipped a published runbook for reconstructing the chain of custody yet. Two pass paths exist: the agent-trace path (LangSmith, Snyk Evo, Keycard) and the OS-side EDR path (CrowdStrike Falcon AIDR caught the equivalent process-layer artifacts in its agentic-AI dossier).
Trap door: “We trace every tool call.” Without OTEL_LOG_TOOL_CONTENT=1 enabled, the record shows the Bash tool was invoked, not the query it ran.
Verifiable answer: a demo of the actual reconstruction along one of the two paths. Either (a) agent reasoning + tool invocation with content + network egress, with documentation that content logging was enabled, or (b) OS-side process/file/network artifacts that capture the equivalent regardless of the agent’s OTel flags. Honest acknowledgement that the reconstruction is the customer’s integration project is acceptable if the vendor names which path they own and which path the customer has to bring.
Three red flags that should make you walk
The vendor describes detection as “AI-powered” and won’t tell you what the underlying signal is.
The product page renamed itself “agentic” within the last six months and the documentation and CVE history say it’s last year’s SAST or EDR with a header swap.
The vendor claims to fully solve prompt injection. That sentence tells you they haven’t read the academic literature on the problem.
Part C — The market read
The shape of the agentic coding security market in May 2026 is lopsided: two layers are consolidating, five are fragmenting, and three capabilities are missing entirely (provenance-aware behavioral trust, approval-fatigue resistance, and tamper-evident agent-action logs keyed to NHI identity).
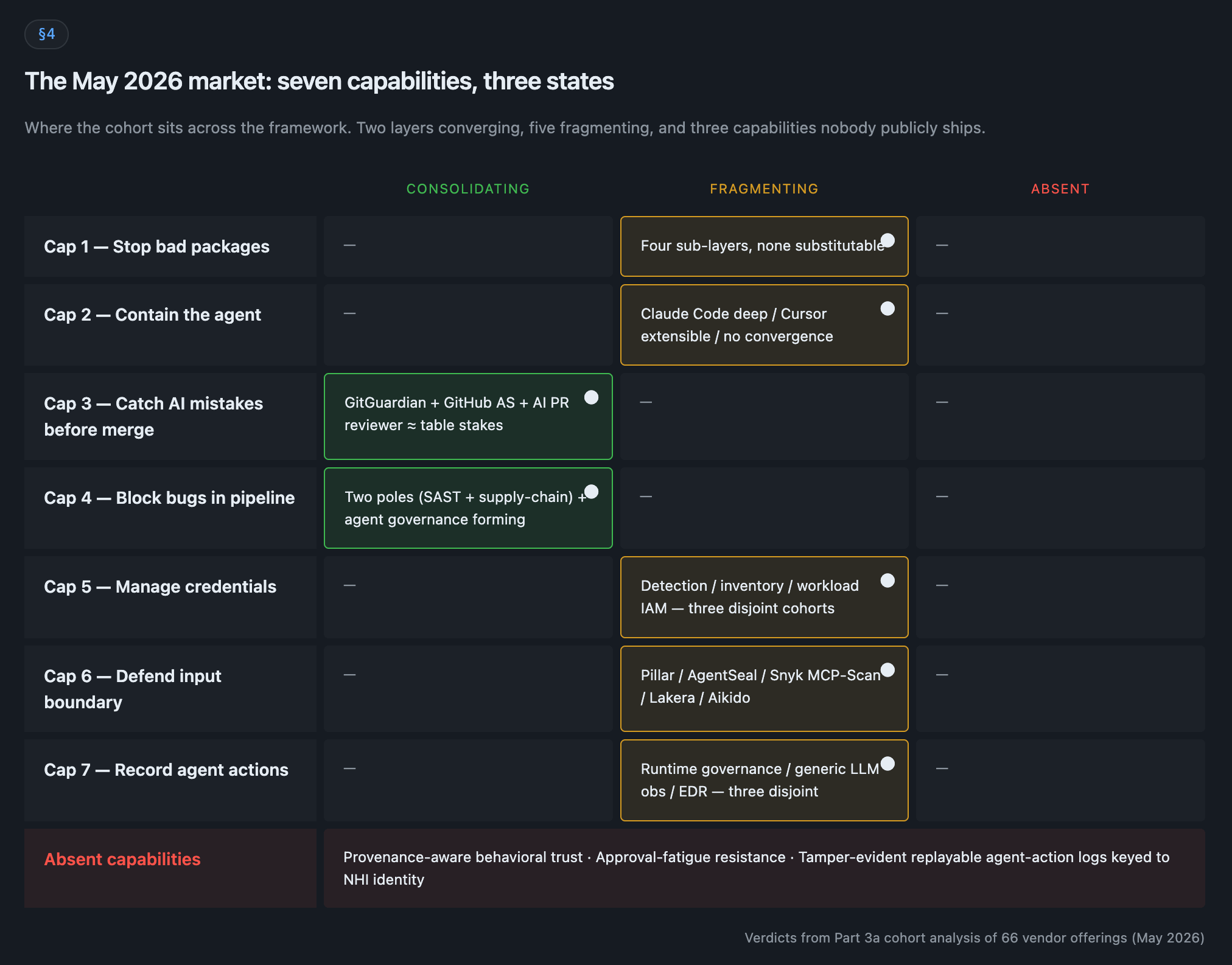
For buyers, two implications. In the converging layers (Cap 3 and Cap 4), it’s safer to commit to a primary vendor: less custom integration work, and the products work similarly enough that switching later doesn’t cost as much. In the fragmenting layers (Cap 1, 2, 5, 6, 7), don’t lock in. Run shorter contracts. Budget for multiple vendors per layer plus integration work. The market will reshape across the next eighteen months, and any “we cover all of this” pitch is either ignoring the gaps or hoping you are.
A few public signals worth watching. GitGuardian closed a $50M Series C focused on agentic NHI. Snyk launched the AI Trust Platform with the broadest coverage claim in the cohort. Cisco’s twin acquisitions (Robust Intelligence and Astrix) are platform-side bets on the consolidating layers. The CISA / Five-Eyes joint guidance on “Careful Adoption of Agentic AI Services” (May 1, 2026) was the first coordinated multi-government posture statement, and reads like a list you can copy into procurement language. Microsoft’s “Defense in depth for autonomous AI agents” (May 14, 2026) restates Part 2’s defense-stack idea from the platform side.
Three eighteen-month bets
Capability-level bets, no vendor names.
Bet 1. By end-2027, the pre-install package gate becomes a line item in every enterprise license. Buyers want one gate; the market has three (agent-time MCP grounding, install-time registry proxy, CI-runner sensor). At least two of the three fuse into a single SKU under one of the supply-chain consolidators. The third (CI-runner sensor) stays separate longer because GitHub-Actions-shaped tools don’t fit the registry-proxy model.
Bet 2. Identity-bound, in-memory, short-lived credentials for agents become a procurement standard. The 82:1 NHI ratio, the 3.2% Claude-Code leak rate, and PocketOS make “the agent holds a long-lived token” the most expensive default in the stack. By H2 2027, RFPs ask for per-request authorization with a published median credential lifetime, and “the agent holds a PAT” becomes a vendor-rejection criterion the way “stores passwords in plaintext” is today.
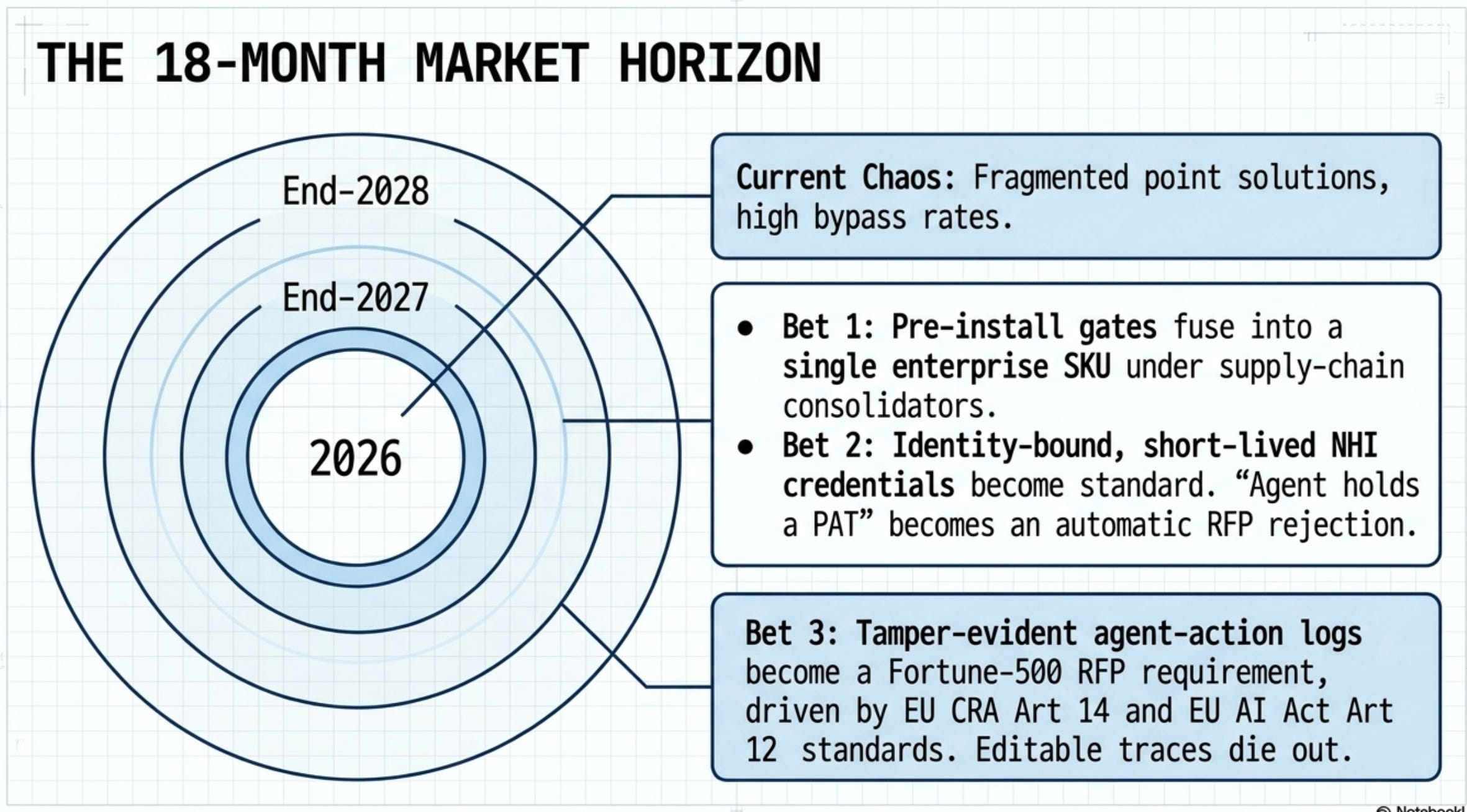
Bet 3. Tamper-evident agent-action logs become a procurement requirement on the way to formal compliance. One caveat on the framing: EU CRA Article 14 is 24-hour incident reporting (the report itself is the artifact; tamper-proof logs are supporting evidence), and EU AI Act Article 12 logging standards for high-risk systems are still being worked out through CEN-CENELEC JTC 21. So “tamper-evident” isn’t a settled requirement yet. But the regulatory direction is clear, and the demand for reconstructing PocketOS-class incidents is here today. By end-2028 (not 2027), at least one Capability 7 vendor ships a tamper-proof agent-action log keyed to NHI identity, with a published runbook for reconstructing a destructive incident, and Fortune-500 RFPs start asking for it. The losers are the generic LLM observability vendors still selling editable traces to security buyers. The buyer wakes up to the fact that an “audit log” needs to be tamper-proof, and the vendor can’t add that by toggling a setting.
Build here: three open spaces
If you’re a founder, an analyst, or a security researcher reading this looking for where to plant a flag, the three absent capabilities above are the most defensible open ground in this market.
Provenance-aware behavioral trust. Fuse SLSA attestation verification with behavioral anomaly detection so the trust score reflects both who signed it and did this look like the maintainer’s normal release pattern. TanStack is the case that proves the gap. No vendor publicly ships this fusion. The technical pieces are already out there (behavioral signals at Socket, Sonatype, StepSecurity; attestation verification at Anchore, Snyk, Endor). The integration is the product.
Approval-fatigue resistance. Break the symmetry between the agent’s request to widen permissions and the human’s one-click yes. Options: a separate approver out-of-band, a cooldown on widening-permission requests, a budget on approvals per session, or some way to attest the human actually read and understood the change. This is genuinely new ground, and nobody in the cohort has solved it. The startup that ships a working control owns the layer.
Tamper-evident, replayable agent-action logs keyed to NHI identity. Tamper-proof storage, tool-call records that capture content (not just structure), OS-side correlation, a query interface keyed to NHI identity, a published runbook for reconstructing a PocketOS-class destructive action. The compliance pressure from EU CRA Article 14 reporting and EU AI Act Article 12 logging creates the buyer in 2027. Today there is no product. The first credible vendor sets the standard.
The losers in each case are the platforms that try to add these capabilities as features inside a bundle without redesigning around them. Specialized products that solve the actual problem will win even if the platforms try to acquire them later. (As, of course, the platforms will.)
The ninety-day plan
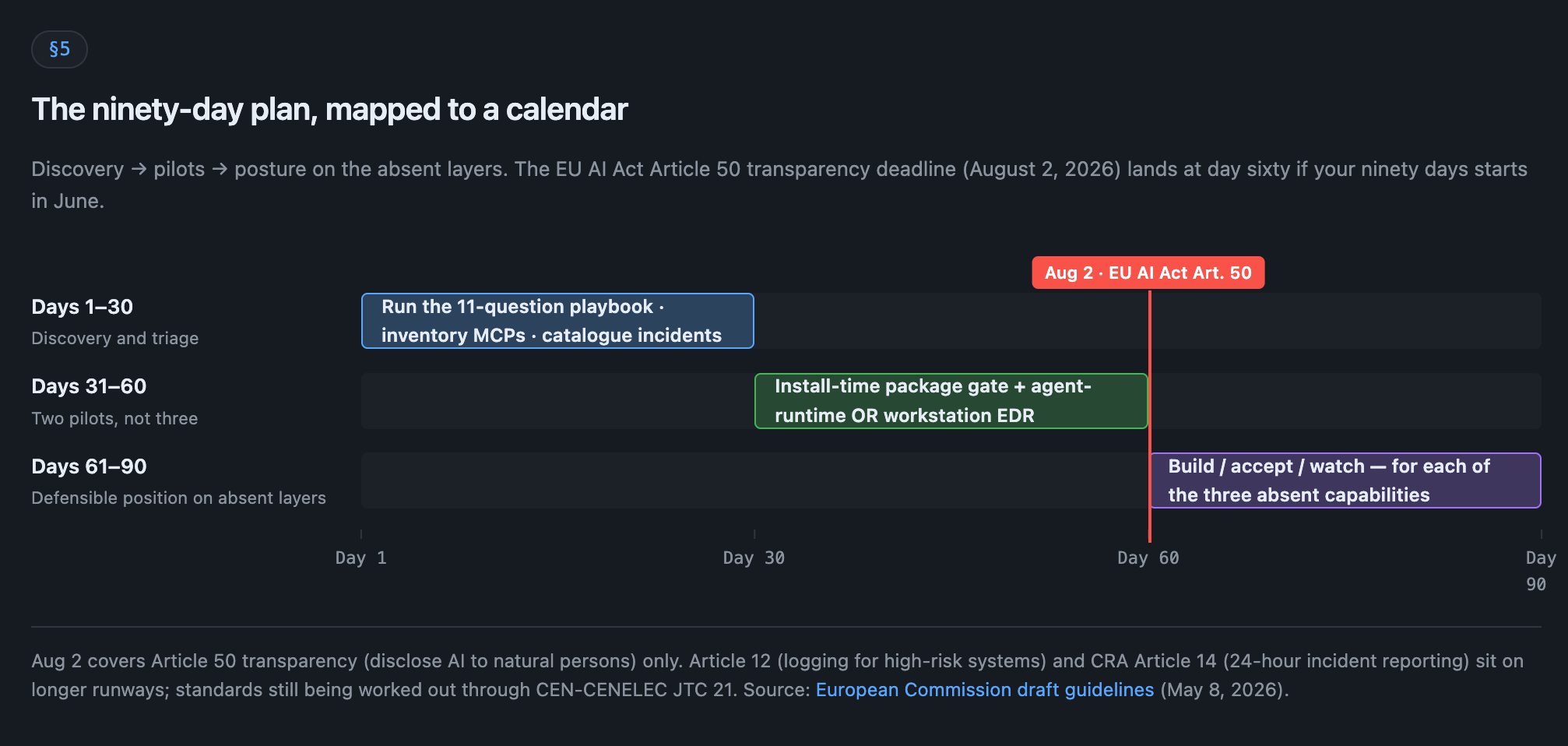
The framework is a calendar exercise, not a strategy deck. What I’d do in the next ninety days, in the order I’d do it.
Days 1-30: discovery and triage. Run the eleven-question playbook against the incumbent supply-chain vendor (Capability 1) and the incumbent AI PR review vendor (Capability 3) if there are any. Score the answers on paper. Take an inventory of MCP configs across the repositories the company actually uses; the GitGuardian numbers suggest there are credentials in there nobody’s catalogued. Figure out which AI coding tools have been adopted by which teams (the answer is usually broader than the CIO thinks). Write up the agentic-coding incidents and near-misses from the last twelve months in a short internal record. That record is the one you’ll want in your hand when a regulator asks.
Days 31-60: two pilots. Stand up one install-time package gate (the Capability 1 differentiator) with a 48-hour minimum-release-age default. Stand up either an agent-runtime governance product (e.g., Keycard for Coding Agents in early access; Snyk Evo AI-SPM in GA with Agent Guard enforcement in private preview) or workstation EDR with the AI module enabled (e.g., CrowdStrike Falcon AIDR), pointed at the most-used coding agent in the company. Treat the named products as examples of the two architectures at this layer, not as the recommendation. Your shortlist will look different. Defer the third pilot. Two is the right number for sixty days; three is the number that fails to ship on time.
Days 61-90: a defensible position on the absent layers. For each of the three absent capabilities (provenance-aware behavioral trust, approval-fatigue resistance, tamper-evident agent logs), make a deliberate call. Three options. Build a compensating control inside the company. Accept the gap and write down a plan to contain the damage if it fails. Or watch the market for a credible vendor and budget for a 2027 pilot. Any of those is fine. What’s not fine is letting the decision get unmade silently. Whatever you pick, write it down with the reasoning, the date, and who’ll revisit it.
One external deadline lands inside this window, and it’s worth being precise about what it actually covers. The EU AI Act Article 50 (transparency) obligations become applicable August 2, 2026: any agentic system interacting with real people in the EU must disclose it’s an AI, unless that’s obvious to a reasonably well-informed user. The European Commission’s May 8, 2026 draft guidelines explicitly bring agentic systems into scope. The guidelines are still in consultation (closes June 3), but the statutory date doesn’t move.
Be clear about what August 2 is not. It’s not a deadline for tamper-evident logging, NHI inventory, or any of the buying discipline above. Those sit in Article 12 (logging for high-risk systems) and CRA Article 14 (24-hour incident reporting), and standards are still being worked out through CEN-CENELEC JTC 21. August 2 is a disclosure-copy deadline for your AI pair-programming tools and any customer-facing agent. It belongs in the 90-day plan as a separate line your legal and comms partner owns, not as a reason to rush the controls above. If your ninety days starts in June, August 2 is day sixty. Don’t get caught missing it.
That’s the ninety days. It doesn’t ask you to close every gap. It asks you to own every gap, with a call written down.
What Parts 1 through 3 add up to
Part 1: the fuse got shorter. Vibe and agentic coding don’t introduce new vulnerability classes; they remove the human latency that used to contain every old one. Part 2: every control in the defense stack puts a human accountability checkpoint back at the layer where the agent removed one. Seven layers, three checkpoints, mapped against SOC2, ISO 27001, and the EU CRA. Part 3a: most of the Part 2 controls can be bought today, but vendor marketing now drifts wide of what the products actually do. Part 3b: the buying question that holds up across all of this is “what would I do if my vendor’s primary control failed?”, asked at every layer.
Three takeaways if you remember nothing else.
Takeaway 1. The buyer in 2026 owns the integration. Five of seven capabilities are fragmenting, and the two consolidating layers are converging on an architecture without a single winner emerging. Budget for at least one vendor per capability, with the integration work named explicitly. Treat any “we cover all seven” pitch as a vendor who doesn’t know the gaps, or hopes you don’t.
Takeaway 2. The unsolved problems sit in the human loop, not the technical stack. Approval-fatigue. Adaptive prompt injection. Provenance authorization. Tamper-evident forensic replay. None of these get fixed by next year’s vendor releases. The 2026 strategy is a portfolio play: assume the input boundary leaks, assume the trust mechanism is bypassable, assume the human will click allow. Design for containing the damage and reconstructing what happened after the failure, not for preventing the failure itself.
Takeaway 3. Capabilities compound. Products commoditize. The buying discipline is the moat. The vendors will keep changing. The capability framework, the diligence cadence, the failure-mode question, the connections between layers: those compound. A vendor list ages in weeks. A buying discipline ages in years.
References (Part 3b)
For the full source list see Part 3a’s references; the items below are specific to this piece.
Buyer’s playbook sources.
GitGuardian State of Secrets Sprawl 2026 (Q4-Q1 secret leak data and Claude-Code-specific 3.2% rate)
AgentSeal MCP server census, February 2026 (1,808 servers, 66% with findings)
UIUC arXiv:2503.00061 — adaptive indirect-prompt-injection attacks
OWASP LLM Top 10 2025 — LLM01:2025 Prompt Injection
Aembit 2026 practitioner survey (80.9% in production, 21.9% identity-aware)
pnpm v10.16+ (default in pnpm 11), Yarn v4.10+, npm v11.10+ release notes —
minimumReleaseAgecontrolsVeracode Spring 2026 LLM security study (150+ models, 55% pass rate)
Socket.dev
didYouMeandocumentation — published Levenshtein heuristic
Regulatory and market signals.
CISA / Five-Eyes, “Careful Adoption of Agentic AI Services” (May 1, 2026) — five risk categories, 23 specific risks, 100+ best practices
Microsoft Security Blog, “Defense in depth for autonomous AI agents” (May 14, 2026)
EU Cyber Resilience Act — Article 13 / Annex I SBOM requirements; Article 14 24-hour early-warning reporting via the ENISA Single Reporting Platform
European Commission, draft guidelines on Article 50 transparency obligations under the EU AI Act (May 8, 2026; consultation closes June 3, 2026); statutory deadline August 2, 2026
GitGuardian $50M Series C announcement
Snyk AI Trust Platform launch materials
Cisco acquisitions of Robust Intelligence and Astrix Security
Vulnerability disclosures cited.
Check Point Research, “RCE and API Token Exfiltration through Claude Code Project Files” — CVE-2025-59536 (MCP server consent bypass), CVE-2026-21852 (ANTHROPIC_BASE_URL env), disclosed February 25, 2026
The Register, “Even Claude agrees: hole in its sandbox was real and dangerous” — Claude Code SOCKS5 hostname null-byte sandbox bypass, silently patched v2.1.88 on March 31, 2026 with no release-note security entry; disclosure May 20, 2026
OX Security, “The Mother of All AI Supply Chains” — MCP STDIO transport design flaw: 150M+ downloads, 7,000+ public servers across Cursor, VS Code, Windsurf, Claude Code, Gemini-CLI; April 15, 2026. Windsurf assigned CVE-2026-30615 (zero-interaction).
Anthropic Engineering, “How we built Claude Code auto mode: a safer way to skip permissions” (March 24, 2026) — source of the 93% human-approval rate on permission prompts
Part 3b of a series on vibe coding and agentic AI security. Part 1 (Every Way In: The Complete Attack Taxonomy for Vibe Coding and Agentic AI) covered the threat model. Part 2 (The Defense Stack: How to Build Security That Runs at Agent Speed) covered the controls. Part 3a (The vendor question: I promised you a map. I changed my mind.) is the capability framework. This piece is the buying discipline that goes with it.