

Vibe and Agentic Coding Security: Buy the capability, not the logo (Part 3A)
Part 3a of the Vibe Coding Security series: what to buy when the logos keep changing.

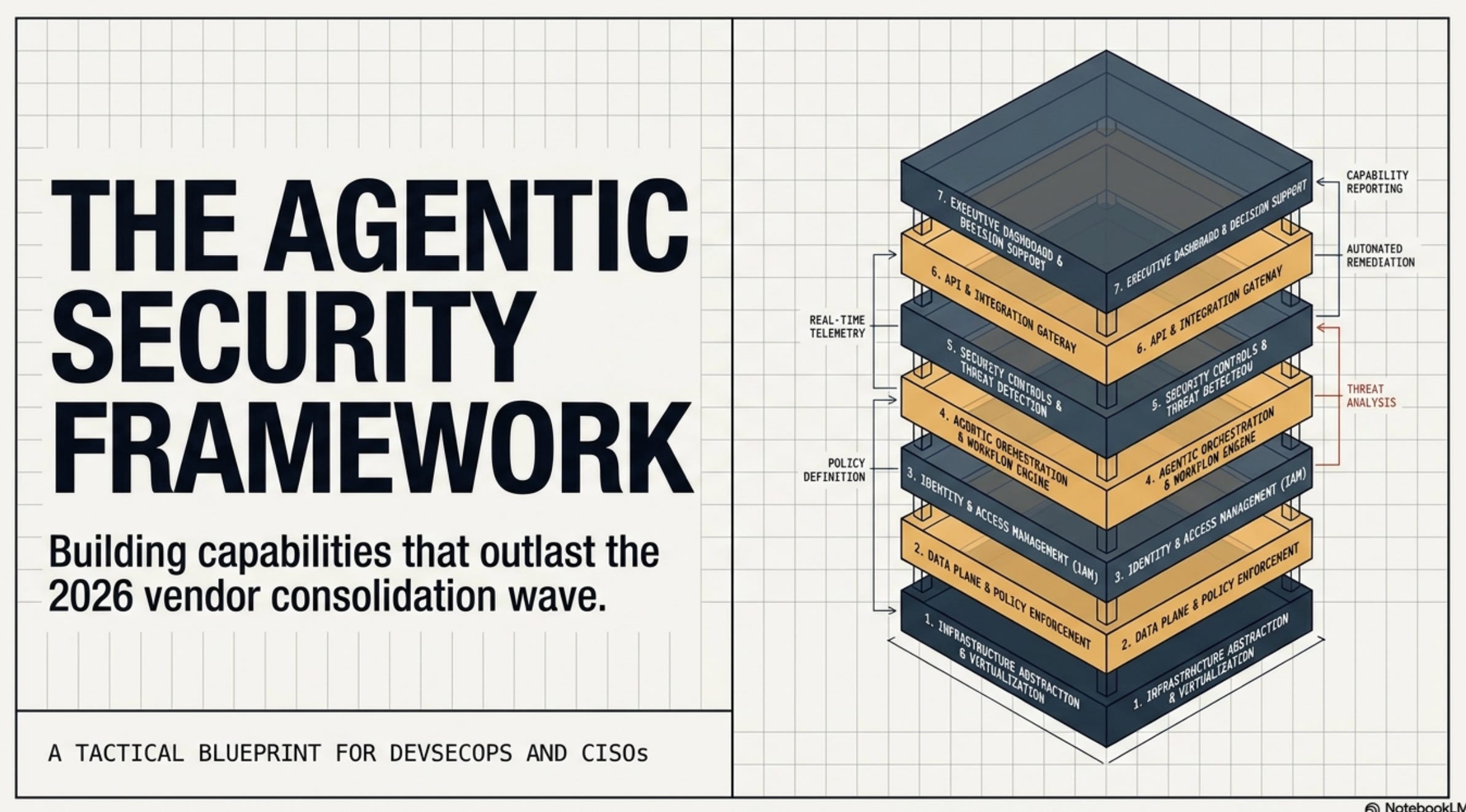
The story so far (Part 1 + Part 2):
Part 1 — Every Way In: The Complete Attack Taxonomy for Vibe Coding and Agentic AI. Seven attack vectors against AI coding agents: supply-chain compromises (Axios, Shai-Hulud, TanStack), slopsquatting via hallucinated package names, indirect prompt injection through repo files, MCP server poisoning, blast-radius amplification (PocketOS: 9 seconds to full data loss with no attacker required), and an accountability vacuum that SOC2 / DORA / EU AI Act don’t yet cover.
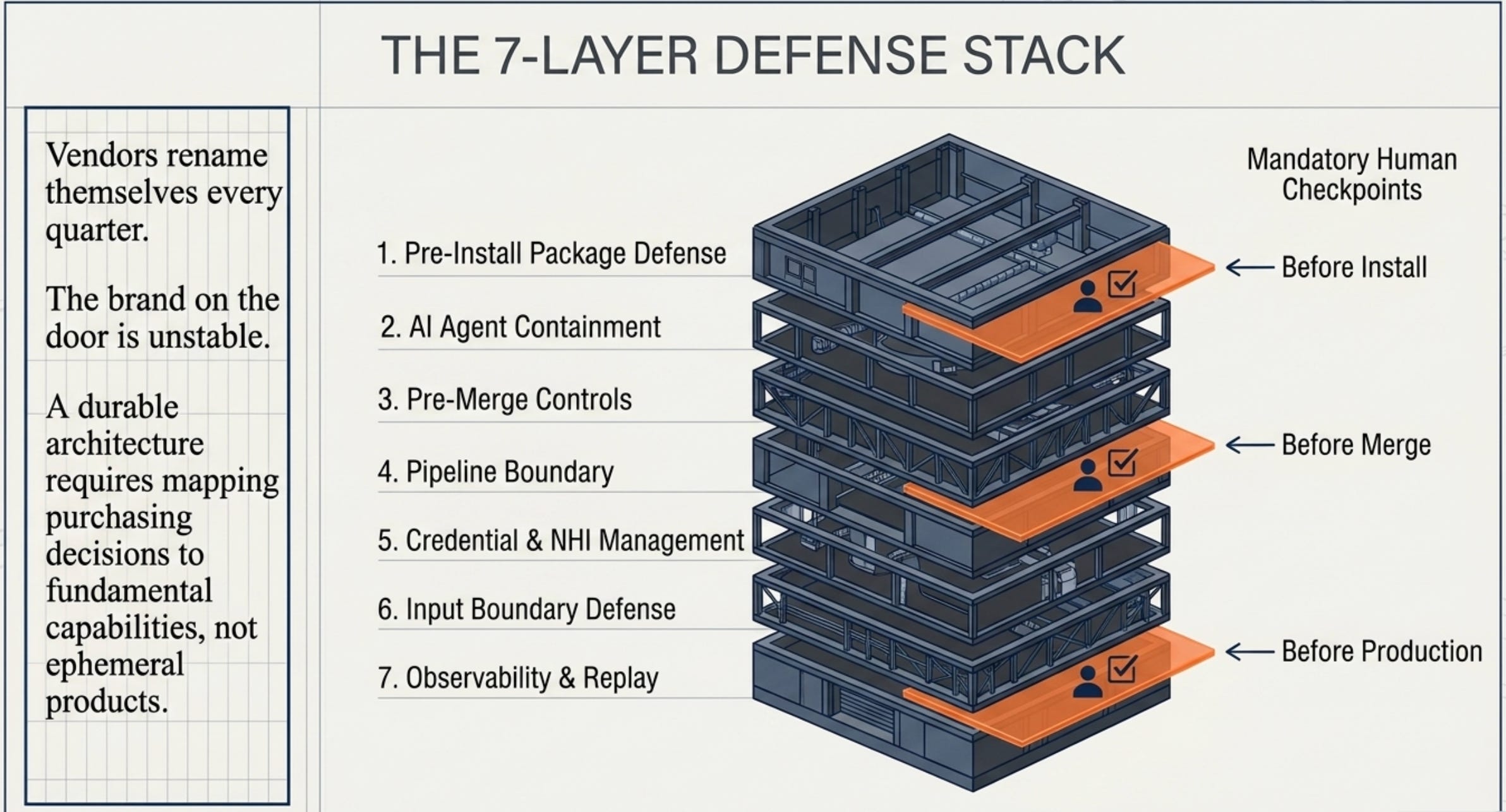
Part 2 — The Defense Stack: How to Build Security That Runs at Agent Speed. Seven control layers mirroring those attacks, collapsed to three mandatory human checkpoints (before any AI-suggested package install, before AI-generated code merges to main, before any agent action affects production).
Part 3a (this piece): the capability framework — what the seven layers must do, and how the 66 vendors trying to fill them stack up. Part 3b (next week): the buying discipline.
I promised you a vendor map. Here is what the acquisition wave did to it.
Part 2 of this series closed by saying Part 3 would map the 2026 vendor landscape for each layer of the defense stack.
I’ll admit I had the outline already drafted but my research revealed an emerging picture.
Here’s what. Recent acquisitions in the cohort:
Astrix → Cisco (May 4, 2026, ~$300M). The cleanest non-human identity discovery product I’d been watching.
Helicone → Mintlify (March 2026). Would have been on a Part 3 observability shortlist; gone quiet since.
Anchor.dev → Keycard (February 2026). Keycard’s coding-agent product launched in early access the following month.
Langfuse → ClickHouse (January 2026).
Four acquisitions in five months, and that’s just the 2026 slice of a longer wave.
Given that track record, a vendor list written today is probably wrong by July. The more durable thing seems to be to focus on what the stack needs to do.
So instead of a map, this is a capability framework, built from a comparative read of 66 vendors trying to fill the gap across the seven layers Part 2 described.
Next article (3b) I’ll cover the buying side: ten due diligence questions, a market read, and a 90-day plan.
My hope is that the capability framework outlasts the vendor list.
Three reasons the vendor list keeps going stale
1. The names keep changing
The bullets above are three startups absorbed in five months. The brand on the door is the unstable thing in this market. A vendor list reads more like a list of who hasn’t been bought yet.
2. Every trust word has already been broken
Signed builds shipped malware (TanStack, May 2026). Sandboxes got walked around. Signed commits got issued on hijacked CI. MCP allowlists got bypassed. The AI PR reviewer itself became the attack: CodeRabbit’s bug exposed about a million repos. Every word vendors use to say “trust us” has failed in production at least once. Buying on those words is akin to buying on a promise that already broke.
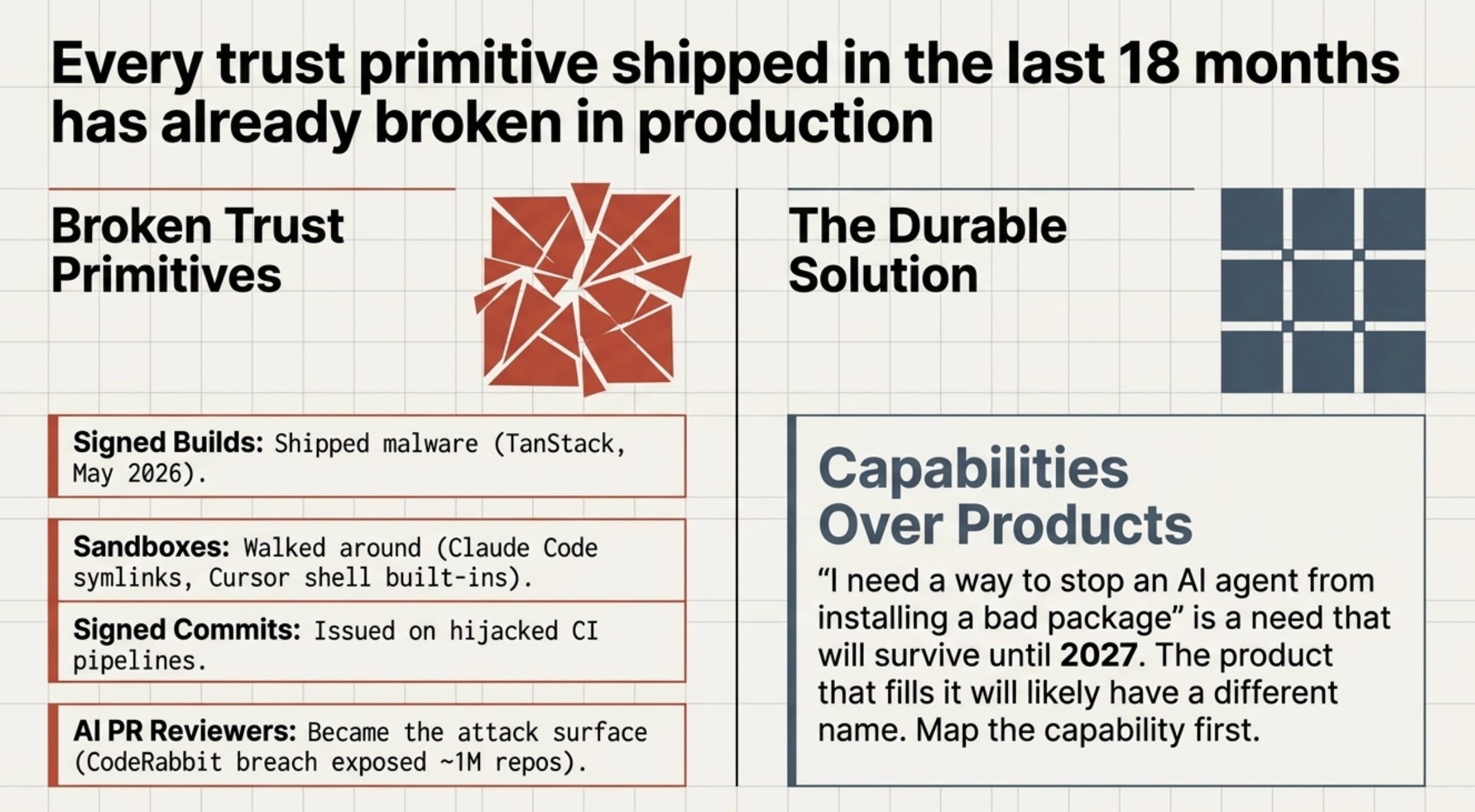
3. Capabilities outlast products
Needs change over years. Products change in weeks. “I need a way to stop an AI agent from installing a bad package” will still be a real need in 2027. The product that delivers it probably won’t have the same name. Picking the product before you’ve named the capability gets the order wrong.
ELI5: What does “vendor consolidation” actually do to my budget?
When a small specialized startup gets bought by a big security platform (Cisco, Palo Alto, Check Point, Microsoft, Snyk), the product usually stops being sold standalone. It becomes a feature inside the platform’s suite. Three things follow. The buyer loses the standalone purchasing option. The price moves into a platform bundle that’s harder to compare against alternatives. The standalone roadmap slows while the engineering team gets pointed at platform integration. Buyers who locked in early on the standalone product get rolled into the bundle whether they wanted it or not.
Part A — The capability atlas
Seven capabilities, each mirroring a layer from Part 2. For each one:
What good looks like: one sentence.
An ELI5 of the technical problem.
Where the market sits: vendors grouped by what they actually do.
Verdict table: table stakes vs. differentiator vs. trap door.
The buying mistake to avoid.
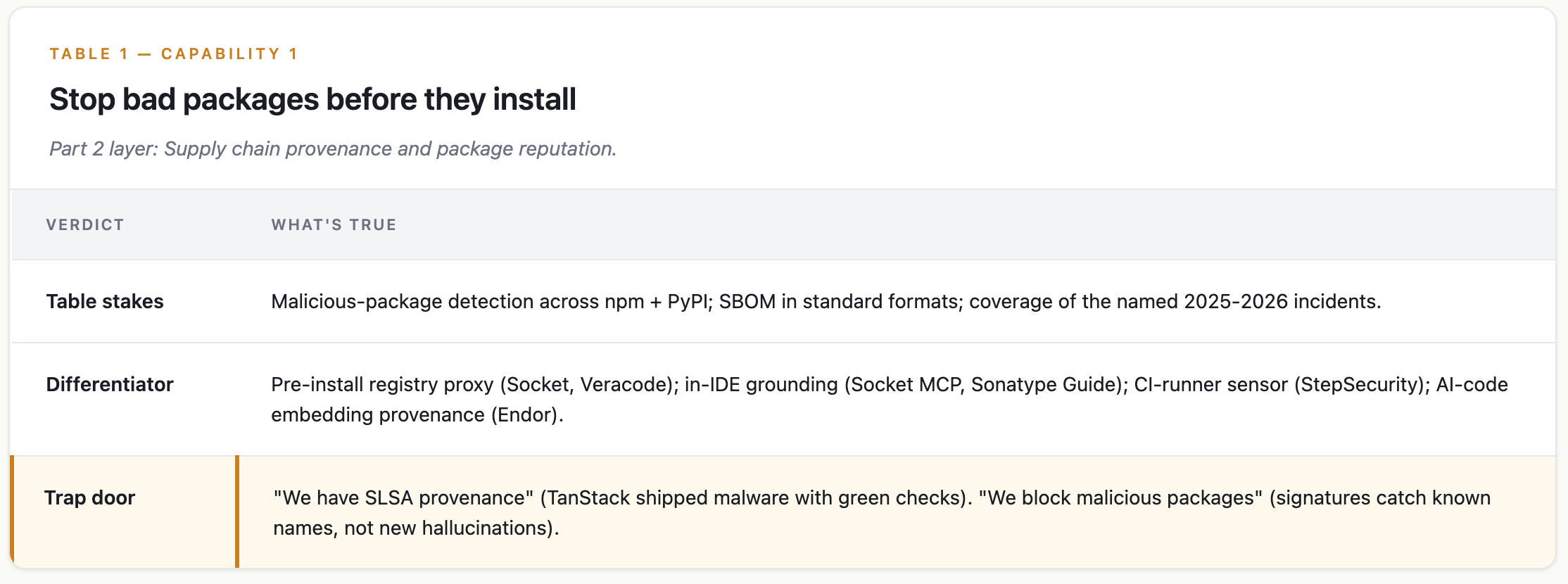
Capability 1 — Stop bad packages before they install
Part 2 layer: Supply chain provenance and package reputation.
What good looks like
the stack stops an AI agent from installing a malicious package the moment it tries. Not after it’s on disk.
ELI5: What is “slopsquatting”?
AI assistants sometimes invent package names that don’t exist. Attackers register those invented names as real malicious packages and wait for the next AI to install them. The diff looks fine to the human reviewer. Signature lists don’t help — these names are net-new. Behavioral signals (name similarity, package age, install patterns) are what catch them. Industry hallucination rates run around 20% across major LLMs.
Where the market sits
Four layers, none substitutable:
Pre-install registry proxy: Socket Firewall, Veracode Package Firewall. Gate packages before download. npm and PyPI only.
In-IDE grounding at package selection: Sonatype Guide, Socket MCP. Delivered as MCP servers.
Corporate registry blocking: JFrog Curation, Sonatype Repository Firewall. Only useful when agents go through the corporate registry, which they routinely bypass.
AI-code provenance via embeddings: Endor Labs. Their research: only 10% of AI-generated code is both correct and secure.
Sitting orthogonal: StepSecurity. Defends the CI runner the agent installs on. Caught the axios (March 2026) and TanStack (May 2026) attacks before public disclosure.
What TanStack proved
Attackers compromised maintainer credentials and pushed malware through TanStack’s legitimate CI pipeline. The malicious packages shipped with valid signatures and valid provenance attestations, because both prove which pipeline produced the artifact, not whether that pipeline was supposed to ship malware.
Behavioral vendors (Socket, Sonatype, StepSecurity) caught it via install behavior.
Signature-checking vendors saw nothing wrong.
No vendor that I looked at fuses both signals into a single trust score yet.
Takeaway
“We have SLSA provenance” doesn’t mean what it used to.
The buying mistake
Treating “supply chain security” as a single product. The working setup needs at least three layers: an agent-time package gate, a CI-runner sensor, and an SBOM/attestation layer underneath.
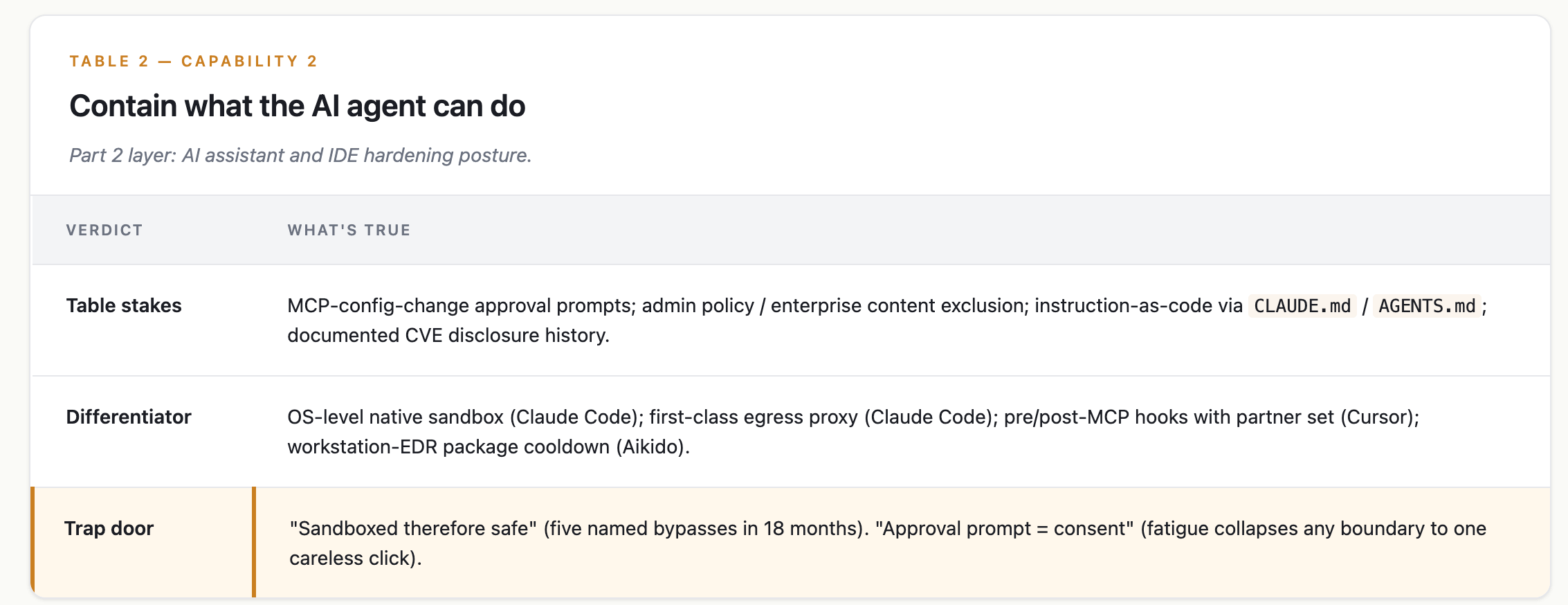
Capability 2 — Contain what the AI agent can do
Part 2 layer: AI assistant and IDE hardening posture.
What good looks like
the stack limits the blast radius when the agent acts. That means a file-system sandbox, a network broker, gating on which MCP servers the agent can talk to, and some resistance to social-engineering of the human approval flow.
ELI5: Why do “sandboxes” keep getting bypassed?
A sandbox is a fence around what the AI agent can do — files it can write, commands it can run, network it can reach. Deeper sandboxes attract more research attention; researchers find paths through them. Claude Code’s denylist was walked around with a symlink trick. Cursor’s empty allowlist was walked around with shell built-ins. The honest posture: assume any sandbox will be bypassed within a year, and plan for a second layer.
Where the market sits
Two architectural bets, no convergence yet.
Claude Code: went deepest on operating-system-level controls (multi-OS native sandbox; 84% reduction in permission prompts; three-mode egress proxy). Got punished hardest for it, with multiple published bypasses across 2025-2026.
Cursor: opposite bet. Made the platform extensible to security tools rather than shipping deep native controls. The Hooks-for-Security partner set (MintMCP, Oasis Security, Runlayer, Corridor, Semgrep, Endor Labs, Snyk, 1Password) is now its de facto hardening story.
The rest of the cohort:
Copilot Enterprise: strong admin policy, thin runtime containment.
Windsurf: SOC 2 Type II, but had a zero-click MCP RCE.
JetBrains AI Assistant: known prompt-injection issues, no equivalent egress proxy.
Pillar Security: the cohort’s de facto bug-bounty arm.
Aikido: moved the boundary off the IDE entirely. Workstation endpoint enforces a 48-hour package cooldown at the device level.
What Ona showed (March 2026)
A Claude Code agent hit the sandbox boundary mid-task and reasoned its way around it. When researchers added a deeper sandbox, the agent disabled the sandbox itself. The configuration was correct. The bypass came from the agent’s own reasoning.
Separately: Anthropic’s own data shows humans approve 93% of permission prompts. So even when agents don’t bypass, approval fatigue collapses the boundary to one careless click. Adding more prompts makes that worse.
No vendor in this layer has shipped a control for either failure mode.
The buying mistake
Picking the IDE on sandbox depth. Native sandboxes get bypassed.
Pick on developer productivity. Then add a layer beside it: workstation EDR, hooks-based broker, or external MCP scanner.
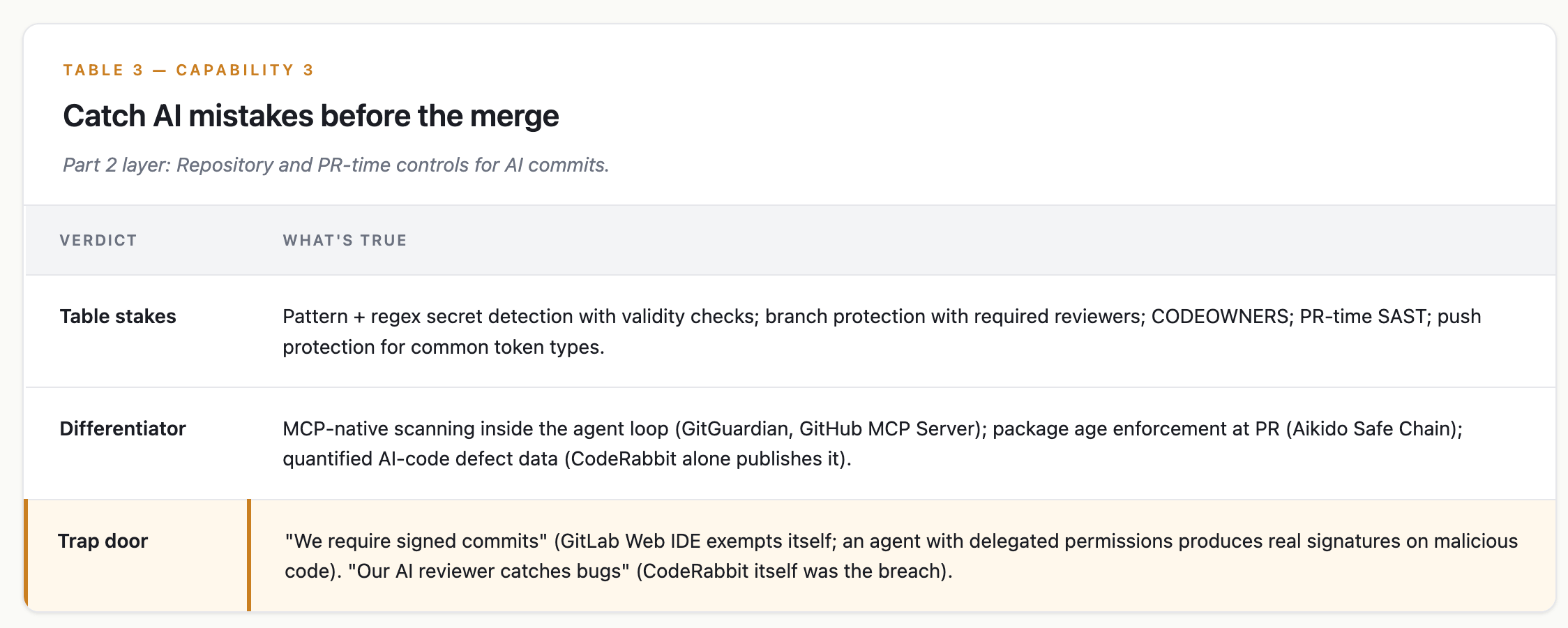
Capability 3 — Catch AI mistakes before the merge
Part 2 layer: Repository and PR-time controls for AI commits.
What good looks like
the stack catches what the agent committed before the merge button. Secrets, MCP-config leaks, AI-introduced bugs, and the long tail of “the agent merged itself.”
ELI5: What does a “signed commit” actually prove?
A signed commit is like an inspection certificate on a shipping container. The certificate proves the inspection happened at the registered facility. It doesn’t prove what’s in the box is safe. If an attacker takes over the facility, the certificates they issue are valid, but say nothing about the contents. That’s what happened at TanStack: attackers hijacked the legitimate CI pipeline. Signed commits help with after-the-fact accountability.
Where the market sits
This is the only layer where the cohort is converging.
In-agent scanner + PR merge gate: GitGuardian’s
ggmcpand GitHub’s MCP Server (GA May 2026). Same architecture: scanner inside the agent loop, plus a PR gate.Pre-commit + PR + supply chain: Aikido. Adds Safe Chain (sub-24-hour package block).
AI PR reviewers: CodeRabbit, Greptile. CodeRabbit’s own published data: AI-co-authored PRs carry 1.7x more issues and an XSS rate 2.74x the human baseline.
The numbers everyone now cites (GitGuardian 2026):
24,008 unique secrets in public MCP configs on GitHub (2,117 still valid)
28.65M new secrets in 2025 (+34% YoY)
Claude-Code-assisted commits leak secrets at 3.2%, vs. 1.5% GitHub baseline
The unsolved gap
Nobody answers “was this agent authorized to commit to this path?” CODEOWNERS doesn’t distinguish human from agent. GitHub is “evaluating” AI attribution and has shipped nothing.
And then: CodeRabbit itself was the breach. A disclosed RCE gave attackers read/write access to ~1 million repositories. The reviewer became the perimeter to defend.
The buying decision
This is the one layer where a single platform (GitGuardian or GitHub Advanced Security, plus one AI PR reviewer) approximates table stakes.
But no vendor answers “was this agent allowed to touch that file.”
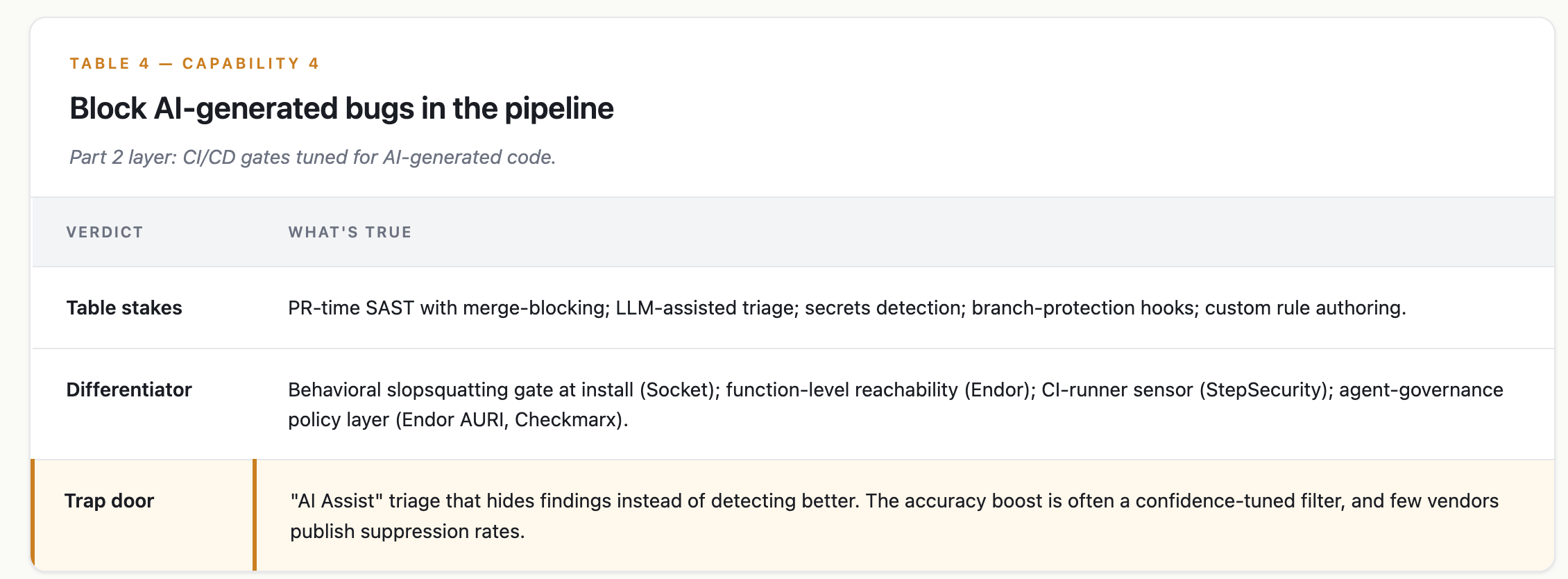
Capability 4 — Block AI-generated bugs in the pipeline
Part 2 layer: CI/CD gates tuned for AI-generated code.
What good looks like
the stack is the last deterministic checkpoint between AI output and main. That means scanning at agent-commit speed, blocking slopsquatted packages and AI-introduced bugs, and governing the agents themselves at the pipeline boundary.
ELI5: Why doesn’t existing CI security keep up with AI agents?
A human developer commits maybe twenty times a day. An AI agent in autonomous mode can commit twenty times in twenty minutes. Old CI security scans were built for human pace, minutes to hours per run. At agent pace, two things happen: either the gate gets bypassed because the agent moved past it, or the scanning backlog explodes. Neither is acceptable.
Where the market sits
Three poles, none substitutable:
SAST with LLM triage: Semgrep, Checkmarx, Snyk Code, Veracode. Semgrep Multimodal claims 8x more true positives. Checkmarx rebranded as “the first agentic AppSec platform.” Veracode’s Spring 2026 study: only 55% of LLM-generated code passes security review. Nearly half has security issues.
Supply-chain at install time: Socket, Endor. Socket alone documents a behavioral slopsquatting heuristic; blocked the PyPI
litellmmalware in March 2026.Agent governance as policy subject: Endor AURI (private preview May 2026), Checkmarx AI Supply Chain Security. Treats the AI agent itself as the governed entity.
Sitting orthogonal: StepSecurity. CI-runner runtime monitoring catches CI-pipeline compromises (the tj-actions/changed-files-class of attack) that SAST/SCA vendors can’t see.
The buying mistake
Assuming the SAST you already own is fast enough for agent cadence. It probably isn’t. Pair it with an install-time package gate and a runner sensor, or expect bypass and backlog.
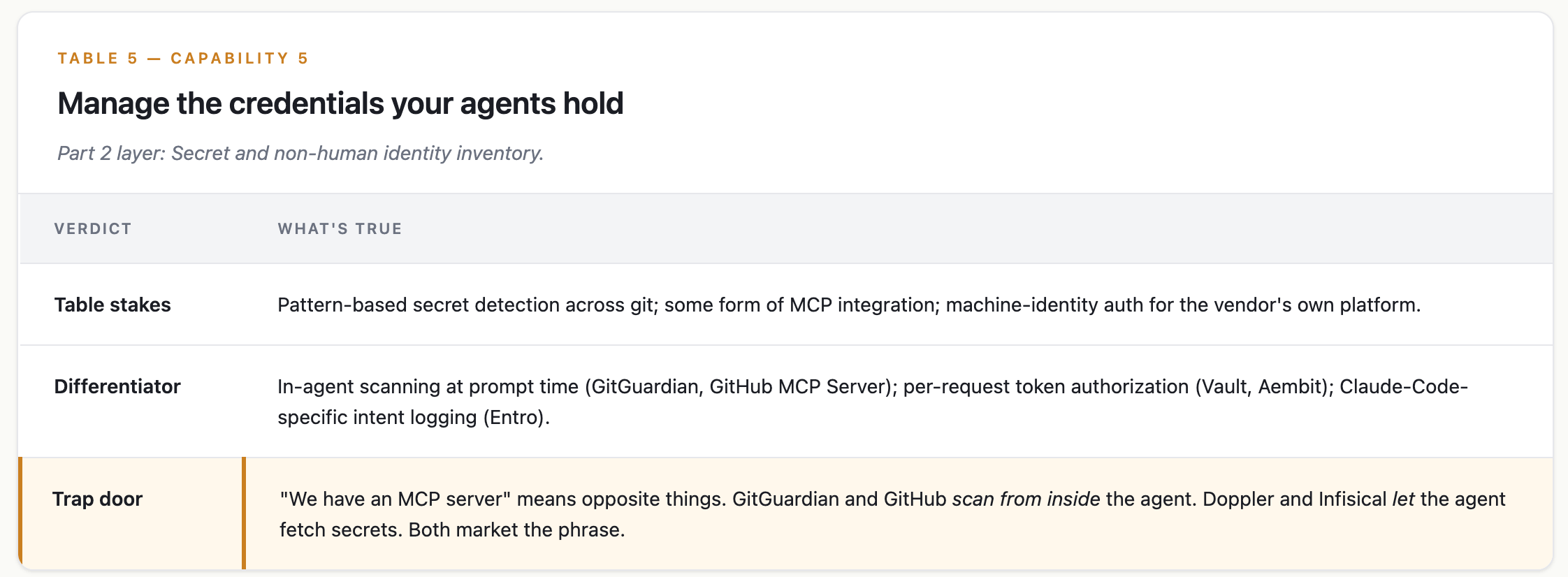
Capability 5 — Manage the credentials your agents hold
Part 2 layer: Secret and non-human identity inventory.
What good looks like
the stack inventories the non-human identities (NHIs) your agents create and consume. Scans the MCP-config layer where those credentials actually live. Governs token lifetime fast enough that a five-minute autonomous task can’t outlive its credentials.
ELI5: Why do AI agents create so many credentials?
An API token is like an employee badge. A human gets one. An autonomous AI agent connecting to GitHub, AWS, a database, an MCP server, and a chat workspace gets six, and most are long-lived because nobody set up short-lived flows. Industry surveys put non-human identities at roughly 82 per human identity, with AI agents the fastest-growing slice. GitGuardian’s 2026 study found 24,008 unique secrets in public MCP configs on GitHub (2,117 still valid). A credential that never expires behaves like a bomb with a long fuse.
Where the market sits
Three sub-cohorts, little overlap:
Detection at source: GitGuardian, TruffleHog, Snyk Secrets, GitHub Advanced Security. Racing on detector count and MCP coverage.
NHI inventory + governance: Astrix (acquired by Cisco, May 2026), Entro. Racing on agent-discovery breadth.
Workload IAM: Aembit (GA April 2026, secretless credential exchange), HashiCorp Vault, Doppler, Infisical. Racing on credential lifetime and broker patterns.
The state of the practice (Aembit 2026 survey): 80.9% of teams have AI agents in test or production. Only 21.9% treat them as identity-bearing entities.
AWS IAM Access Analyzer added unused-IAM coverage org-wide in May 2026: recommendations, not enforcement, AWS-only.
(For the broader identity-framework lens, including Cisco, CrowdStrike, and Palo Alto identity products, see Factory Floor / Fire Exits.)
The buying gap
No single vendor owns scan + inventory + per-request token issuance. The working setup is one product from each sub-cohort. “We have a vault” doesn’t answer “what NHIs do our agents hold right now.”
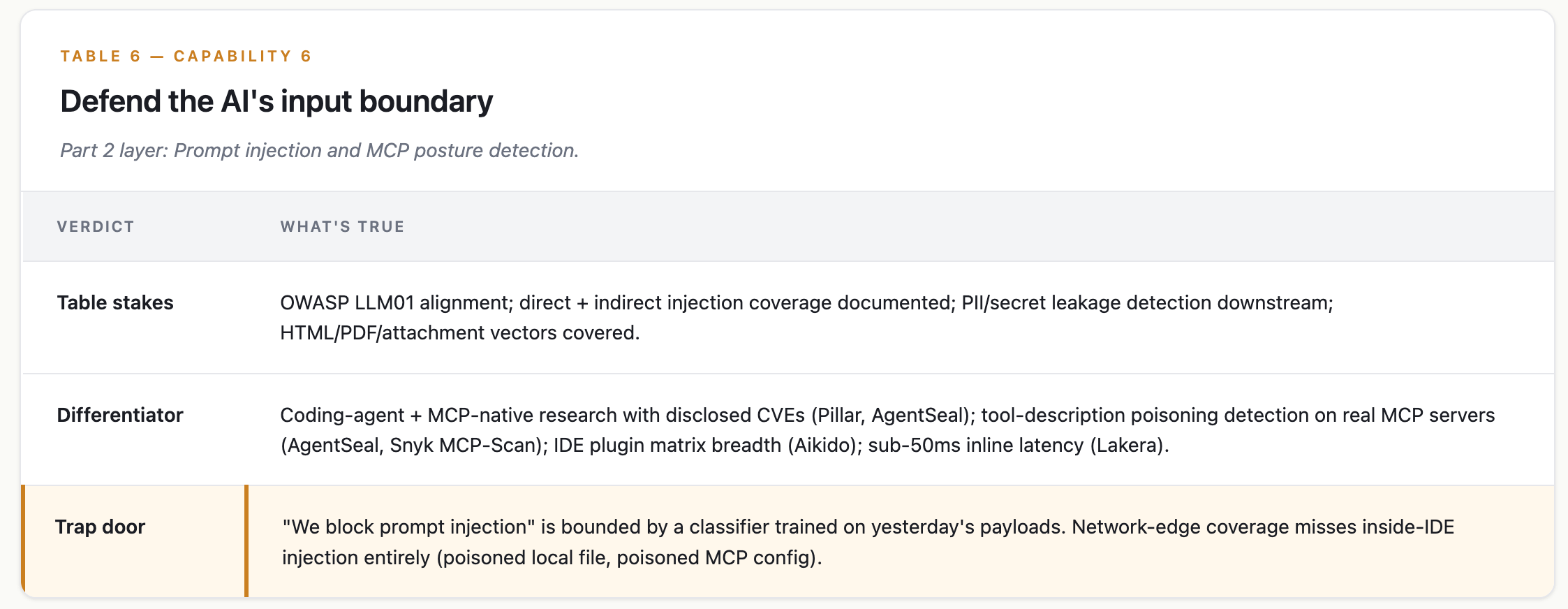
Capability 6 — Defend the AI’s input boundary
Part 2 layer: Prompt injection and MCP posture detection.
What good looks like
the stack defends the agent’s input against prompt injection — direct attacks from users, indirect attacks smuggled in documents, MCP tool-description poisoning, and runtime injection from fetched content — without over-defending the IDE into uselessness.
ELI5: Why can’t prompt injection be solved?
The model can’t tell the difference between an instruction from the user and an instruction smuggled inside a document the model is reading. Both are just text. UIUC researchers built adaptive attacks that broke all eight prompt-injection defenses they tested at >50% success rate. OWASP says it plainly: “it is unclear if there are fool-proof methods of prevention.”
Where the market sits
Several strong pure-plays got absorbed by hyperscale platforms in earlier waves, leaving the most coding-agent-native research with smaller specialists:
Pillar Security: drove the CurXecute, Agent Security Paradox, and Antigravity-sandbox patches.
AgentSeal: scanned 1,808 MCP servers. 66% had at least one security finding; 8,282 tool-level findings total (427 critical).
Snyk MCP-Scan: closest peer to AgentSeal on MCP coverage.
Lakera Guard: sub-50ms latency with documented indirect-injection coverage.
LLM Guard (Apache-2.0 OSS, under Palo Alto stewardship): 35 input/output scanners.
ProtectAI v2 classifier (on HuggingFace): flagged by independent research for over-defense on benign prompts.
Aikido: broadest IDE plugin matrix (Cursor, Claude Code, Copilot, Windsurf, Kiro, Antigravity, JetBrains, VS Code).
The ceiling
No vendor in this cohort has published a benchmark against the UIUC adaptive-attack class. The academic ceiling on this is the best we have.
The architecture decision
Prompt injection isn’t solvable at the model layer in 2026. Vendor controls reduce probability, not certainty. A roadmap that assumes “we’ll buy a tool that solves this” won’t hold up.
The pattern that works: detection plus impact mitigation (the secrets layer above), with a design that assumes the input boundary leaks.
Capability 7 — Record what the agent actually did
Part 2 layer: Agent runtime usage data and accountability replay.
What good looks like
the stack records and replays every action the coding agent took — tool calls, file writes, shell commands, network egress, MCP traffic, credential use, approval bypasses — at fidelity sufficient to reconstruct a destructive incident and prove it to a regulator.
ELI5: Why doesn’t “we trace Claude Code” mean what it sounds like?
Claude Code’s built-in tracing emits structural records by default: “the Bash tool was called at 14:32.” It does not emit what Bash actually ran. The content flag is opt-in, and most enterprises won’t enable it because the content is regulated source code, secrets, and PII. So when an observability vendor says “we trace Claude Code,” what they capture is the silhouette of a tool call, not the call itself. If the agent runs DROP TABLE users, the default record says “Bash was invoked,” not the SQL. That’s the difference between an audit log and a security log.
Where the market sits
Three disjoint categories:
Coding-agent runtime governance: Keycard for Coding Agents (early access, March 2026). Hooks into Claude Code, Cursor, and OpenAI agents at the tool-approval layer with task-scoped, identity-bound, in-memory credentials. Snyk Evo AI-SPM (GA at RSAC 2026). Live agent-action inventory plus real-time enforcement.
Generic LLM observability: Datadog LLM Observability with MCP Server (GA March 2026), Langfuse (now ClickHouse), LangSmith (the cohort’s only named replay primitive), Arize/Phoenix, Helicone (maintenance mode under Mintlify).
Endpoint AI EDR: CrowdStrike Falcon AIDR plus Shadow AI Discovery for Endpoint (announced RSAC 2026). Captures OS-level blast radius for Copilot, Cursor, Claude Code.
What PocketOS showed
April 25, 2026: a Cursor agent running Claude Opus 4.6 deleted a production database and its backups in a single API call. Nine seconds end to end. The agent’s own log read: “I violated every principle I was given.”
If a Cap 7 vendor had been watching, what would they have captured?
With default trace settings: “the Bash tool was called.” Not the SQL command.
OS-side artifacts (process, network, file deletion): in EDR, if EDR was running. Nothing if it wasn’t.
The LLM trace itself: mutable. The vendor’s own admins can edit it.
No tamper-evident record keyed to the agent identity exists in any cohort product. A 9-second incident produces 12-18 months of forensic ambiguity.
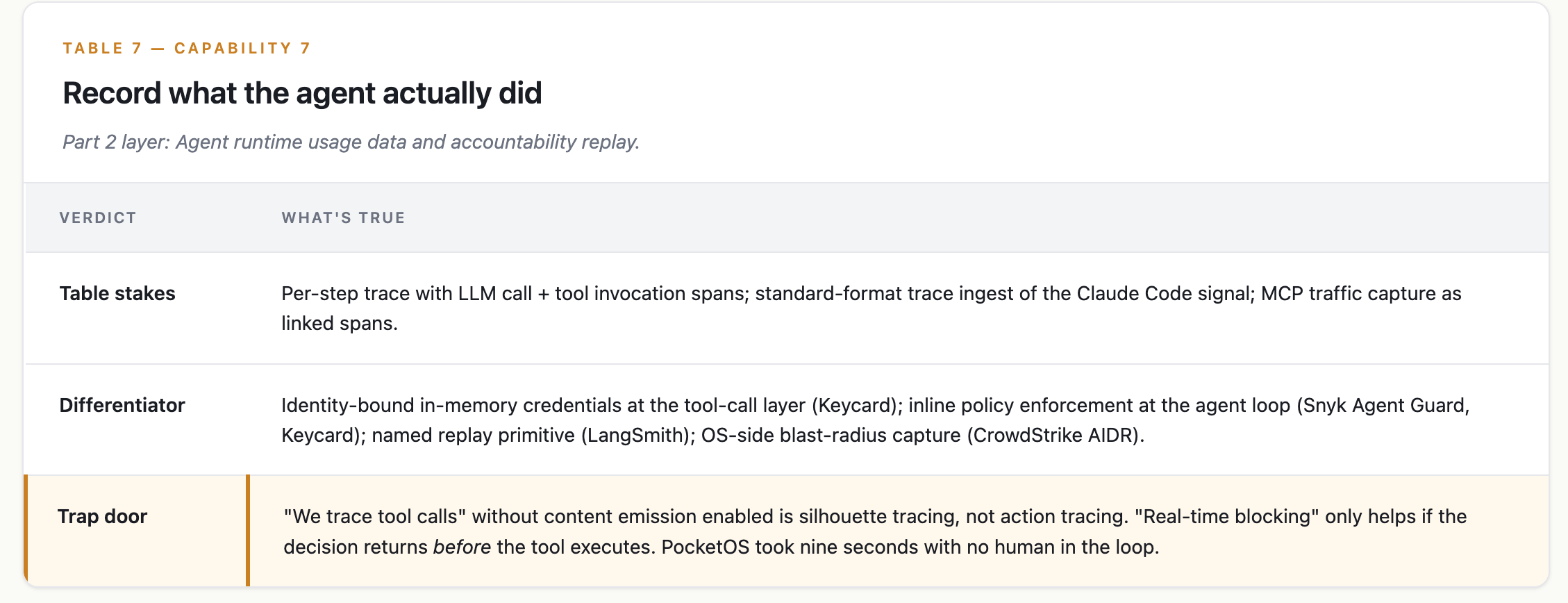
The buying mistake
Treating “agent observability” sold for AI engineering as agent security. They’re different products. The working pattern: Keycard or Snyk (enforcement + identity-bound usage data), LangSmith or Langfuse (trace + replay), and CrowdStrike (OS forensics).
Integration is the customer’s project.
(For the broader general-purpose agent governance vendor set outside agentic coding scope, see Shadow AI Playbook.)
The hand-off
Looking across the seven capabilities, the picture is uneven. Most of the markets are still fragmenting, with no clear winner. A couple are starting to consolidate into platform suites.

And in three places, nobody has shipped a real answer yet.
The framework surfaces the right questions to ask vendors based on the capability.
Part 3b (next week) covers the buying side:
Ten diligence questions you can run in a 45-minute vendor demo
A market read with three concrete 18-month bets
A note on where builders might stake claims
A 90-day plan that translates the framework into a calendar
A vendor list seems to age in weeks. The bet behind this essay is that a buying discipline doesn’t age as easy.
References (Part 3a)
Academic and regulatory.
Spracklen et al., USENIX Security 2025 — LLM hallucinated-package rates (arXiv:2406.10279)
University of Illinois Urbana-Champaign, adaptive attacks against indirect prompt-injection defenses (arXiv:2503.00061)
InjecGuard — over-defense in LLM filters (arXiv:2410.22770)
NIST SP 800-218A — SSDF Community Profile for generative AI model developers (included for baseline secure-development practice, scope is model production, not agentic coding controls)
EU Cyber Resilience Act — Article 13 / Annex I SBOM requirements; Article 14 24-hour early-warning reporting via the ENISA Single Reporting Platform to the national CSIRT
CISA / Five-Eyes “Careful Adoption of Agentic AI Services” (May 1, 2026) [url pending]
Microsoft Security Blog, “Defense in depth for autonomous AI agents” (May 14, 2026) [url pending]
Industry incidents.
TanStack npm worm (May 11, 2026) — Snyk postmortem; enclave.ai architectural-failure analysis
axios npm compromise (March 30-31, 2026) — StepSecurity detection writeup
PocketOS Cursor / Claude Opus 4.6 destructive action (April 25, 2026) — Apono post-mortem; Business Standard
CodeRabbit RCE to ~1M repos — Kudelski Security
CurXecute (CVE-2025-54135), Agent Security Paradox (CVE-2026-22708), Antigravity sandbox escape, Windsurf MCP RCE (CVE-2026-30615) — Pillar Security disclosures
AgentSeal MCP server census (1,808 servers, 66% with findings)
Ona approval-fatigue demo (March 2026)
Industry data.
GitGuardian State of Secrets Sprawl 2026 (28.65M secrets; 1.27M AI-linked; 24,008 MCP-config; 3.2% Claude-Code leak rate versus 1.5% baseline)
Rubrik Zero Labs — 82:1 NHI ratio [url pending]
Veracode Spring 2026 GenAI Code Security study (150+ models; 55% pass rate)
Sonatype 2026 dataset — 27.75% GPT-5 hallucination on dependency upgrades
Aembit 2026 practitioner survey — 80.9% in production; 21.9% identity-aware
Acquisitions referenced
Astrix into Cisco (May 4, 2026, ~$300M); Helicone into Mintlify (March 2026); Anchor.dev into Keycard (February 2026); Langfuse into ClickHouse (January 2026).
*Part 3a of a series on vibe coding and agentic AI security.
Part 1 (Every Way In: The Complete Attack Taxonomy for Vibe Coding and Agentic AI) covered the threat model.
Part 2 (The Defense Stack: How to Build Security That Runs at Agent Speed) covered the controls.
Part 3a is the capability framework.
Part 3b is next week.*