

The $20 subscriptions for generative AI are ending
What replaces them is a menu of options, not a single number.

On March 26, Anthropic quietly tightened five-hour session limits on Free, Pro, and Max plans, conceding that about seven percent of users would now hit caps they used to clear. In early April, Anthropic blocked OpenClaw and similar third-party agent frameworks from running on Pro and Max plans after a single autonomous agent was reportedly burning the equivalent of $1,000 to $5,000 a day in API cost. On April 14, Anthropic flipped enterprise from $200 flat per seat to $20 base plus usage — “double or even triple the cost for heavy users,” in one analyst’s read of the change.
Nineteen days. One lab. Three price changes, all pointing the same direction.

Look across the four US frontier labs and the pattern repeats:
OpenAI (ChatGPT)
Free — ad-supported (February 2026)
Go — $8/month
Plus — $20/month (held, but lost ground)
Pro — $100/month (launched April 9)
Pro Max — $200/month
Google (Gemini)
AI Plus — $7.99/month (late January 2026)
AI Ultra — $249.99/month (with Gemini 3.1 Pro and Deep Think)
xAI (Grok)
SuperGrok Lite — $10/month (March 2026)
SuperGrok — $30/month
SuperGrok Heavy — $300/month
Anthropic (Claude)
Max — $100/month
Max — $200/month (monthly only)
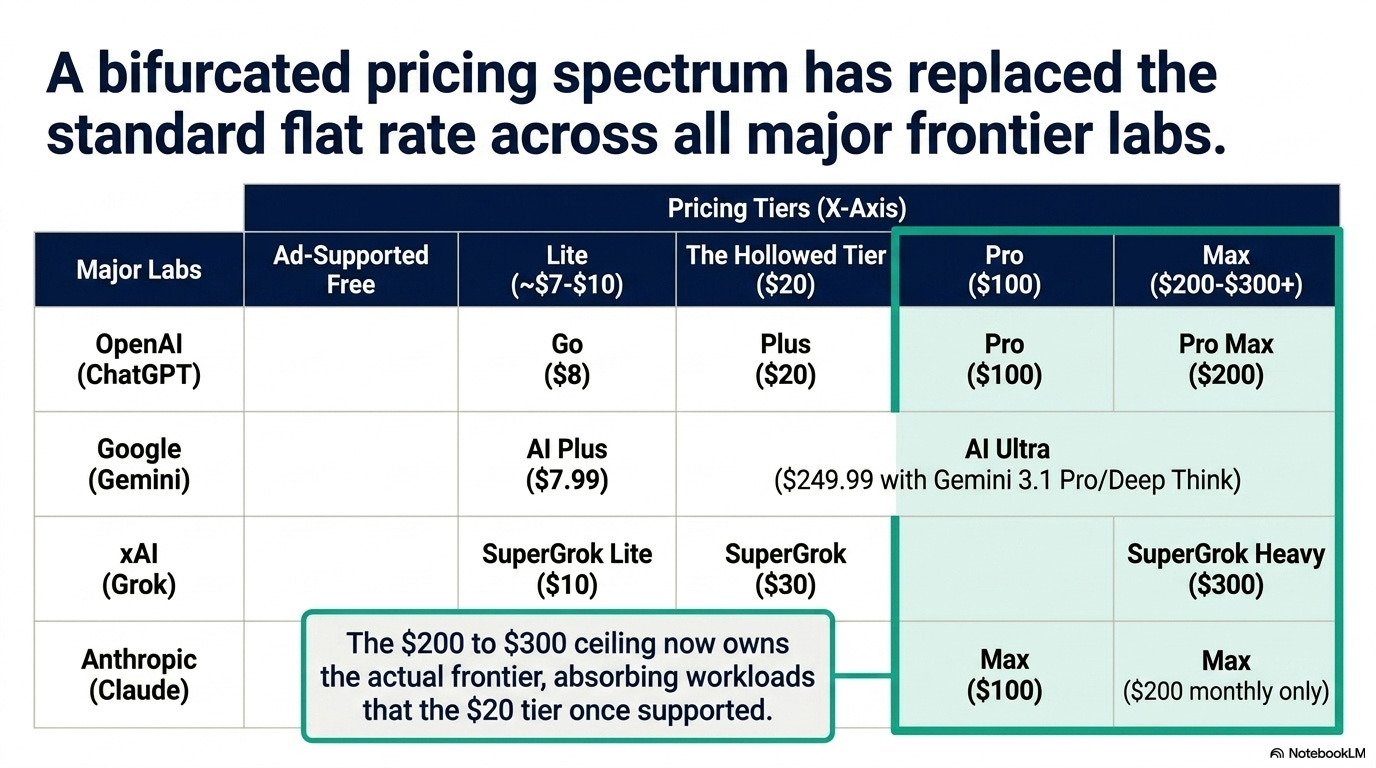
The same pattern every time: a degraded free tier, a sub-$10 lite, the original $20 still standing but stripped, a $100 mid-Pro that ate the $20 tier’s old job, and a $200 to $300 ceiling that owns the actual frontier.
The math that never worked
Three weeks ago I argued enterprise AI bills had risen 480% while per-token prices fell 280x. The consumer side is the same paradox compressed into one $20 invoice.
Per-token inference cost is falling fast.
Epoch AI clocks the median decline at 50 times per year across benchmarks; if we restrict the window to post-January 2024 and it’s 200 times per year. Stanford’s 2026 AI Index has GPT-3.5-equivalent inference dropping 280x in 18 months.
The decline is algorithm-driven, not just hardware.
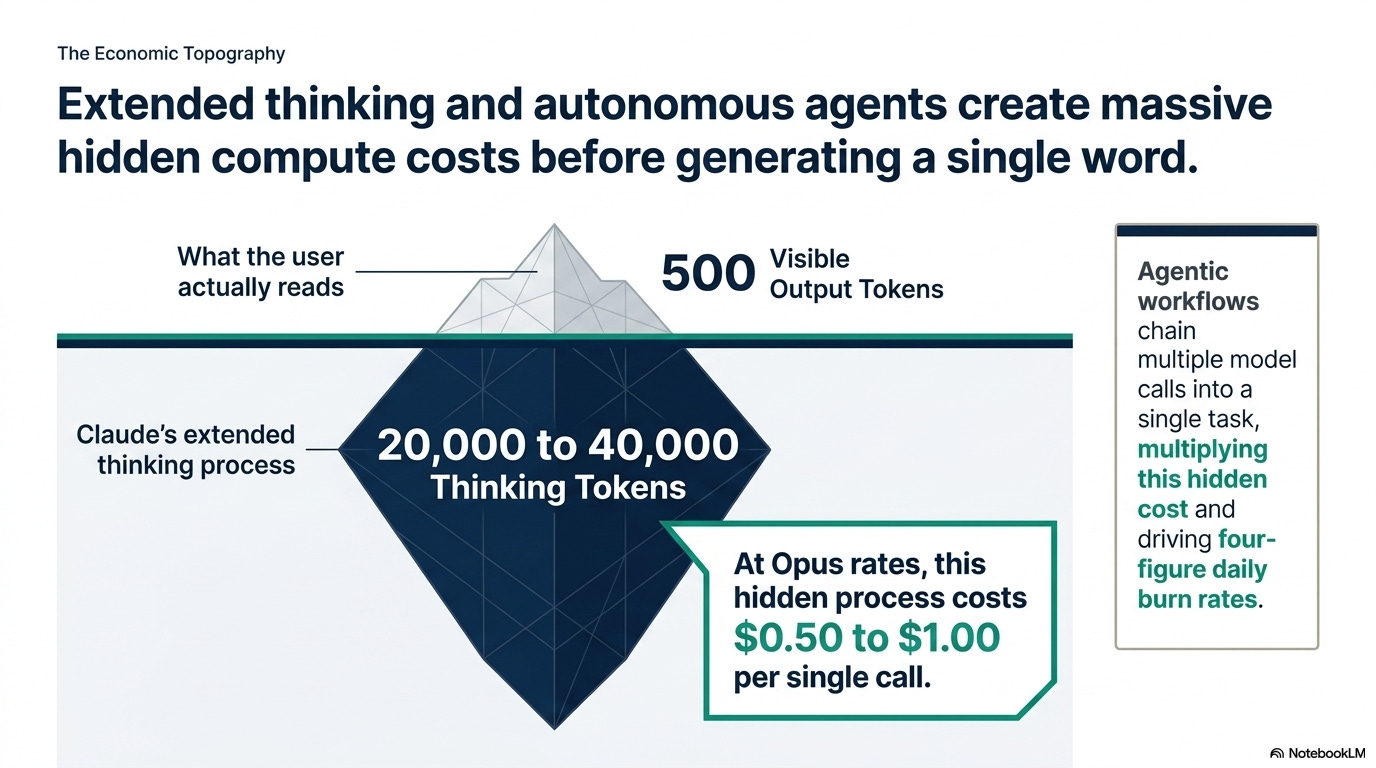
Tokens-per-task moved the other way. Reasoning mode burns 5 to 50 times more tokens than a one-shot answer.
Claude’s extended thinking can spend 20,000 to 40,000 thinking tokens before showing 500 visible ones.
At Opus rates that’s $0.50 to a $1 per call before the reader sees the first word.
Agentic workflows chain multiple model calls into a single task. That is the math that produced the four-figure-per-day burn rates behind the early-April block.
The Information has OpenAI’s 2025 inference costs quadrupling, adjusted gross margins falling from 40% to 33%, 2026 cash burn forecast at $25 billion, cumulative through 2030 raised by $111 billion. Sacra projects OpenAI’s 2026 inference bill alone at $14.1 billion.
David Cahn at Sequoia keeps repeating the same line: AI companies are bringing in tens of billions a year, but they’re spending trillions over the next five years on data centers and power.
Each question gets cheaper to answer, but people are asking way more of them — so the total bill keeps climbing.
The same thing is happening to regular consumers.
What replaces it
A menu of subscription options from free to $300/month.
Free with ads at the bottom.
A $7 to $10 lite tier above that: Go, AI Plus, SuperGrok Lite.
The $20 tier still there in name, increasingly hollow in practice.
A $100 Pro that holds what $20 used to.
A $200 to $300 ceiling for the actual frontier. And usage-based pricing for anyone whose workload is honest about what it costs.
The other half of the menu is the part the labs don’t advertise.
Frank Nagle and his collaborators at the MIT Initiative on the Digital Economy ran the numbers in January: open models hit 89.6% of closed-model performance at release and close the gap within thirteen weeks, while costing roughly 87% less per million tokens.
They estimate that reallocating usage to open models would save the AI economy around $25 billion a year. Closed models still hold about 80% of token usage.
Meta released Llama 4 Scout in April 2025: 17B active, 109B total, 10M-token context, runnable on a single high-end GPU or an M-series Mac with enough unified memory.
Google shipped Gemma 4 on April 2 across four sizes, Apache 2.0, “frontier multimodal intelligence on device” in their words.
Microsoft’s Phi-4-mini fits 3.8B parameters of reasoning into a laptop.
Apple Intelligence runs a 3B foundation model for free on every recent M-series Mac and iPhone, quietly improving each macOS release.
The global open-weights field fills in the rest.
DeepSeek-R1-distilled-32B beats GPT-4o on GPQA.
Qwen3-Coder, the open-weight 480B-A35B variant, sits at frontier on coding benchmarks.
GLM-5.1 became the first open-weight model to top SWE-bench Pro and can run an eight-hour agentic session on a single prompt.
Kimi K2.6 lands within five percent of Claude Opus 4.7 on coding agents.
Mistral Large 3 is within seven percent of GPT-5.5 on general reasoning.
A Mac Studio M3 Ultra at 96GB ($5–6K), an RTX 5090 desktop ($3K street plus a $1K build), or an ASUS Ascent GX10 at $2,999 will run a stack mixing several of these at zero marginal cost after hardware. That stack covers the middle 80% of what a $20 ChatGPT Plus subscriber actually does: chat, code, summarization, multi-step reasoning.
It does not cover the absolute frontier. GPT-5.5 Pro extended thinking, Claude Opus 4.7 with 64K thinking tokens, Gemini 3.1 Pro Deep Think.
Those still live in the cloud, behind a $100 to $300 paywall.
The 1995 rhyme
Microsoft and Apple sold polished bundles to the median consumer between 1995 and 2000: Windows 95, Windows 98, Mac OS.
Linux ran adjacent on the hobbyist tier, faster-improving and free, never close to replacing Windows for the median user. I worked with Linux distros as my “power user” setup for 2 decades.
But the hobbyist tier permanently capped what Microsoft could charge for the OS. And it became the substrate for almost everything that came next: Apache, Linux servers, Android.
The 2026 consumer LLM market is rhyming. ChatGPT, Claude, Gemini, and Grok are the polished bundles at $20 to $300 a month. Better UX, faster iteration on product, the only realistic place to live for the median consumer who wants something that just works on a phone.
Ollama, LM Studio, llama.cpp, Jan, and Msty are the hobbyist tier. They run adjacent. They improve faster than the bundles. They will not replace the bundles for most people.
The MIT Sloan number — 80% of usage still in closed models — is the same pattern as Linux’s desktop share in 1998. The hobbyist tier never won the median user. It capped what the median user got charged.

The labs’ incentive is to understate this. Admitting that a determined consumer can run Llama 4 plus Qwen3-Coder plus DeepSeek-R1-distilled on a Mac Studio for the price of two years of Pro limits their pricing power forever.
So they don’t admit it. The current coverage on this is sourced largely from the labs but it is good news for the consumers that there is a hobbyist option gaining foothold.
To be fair
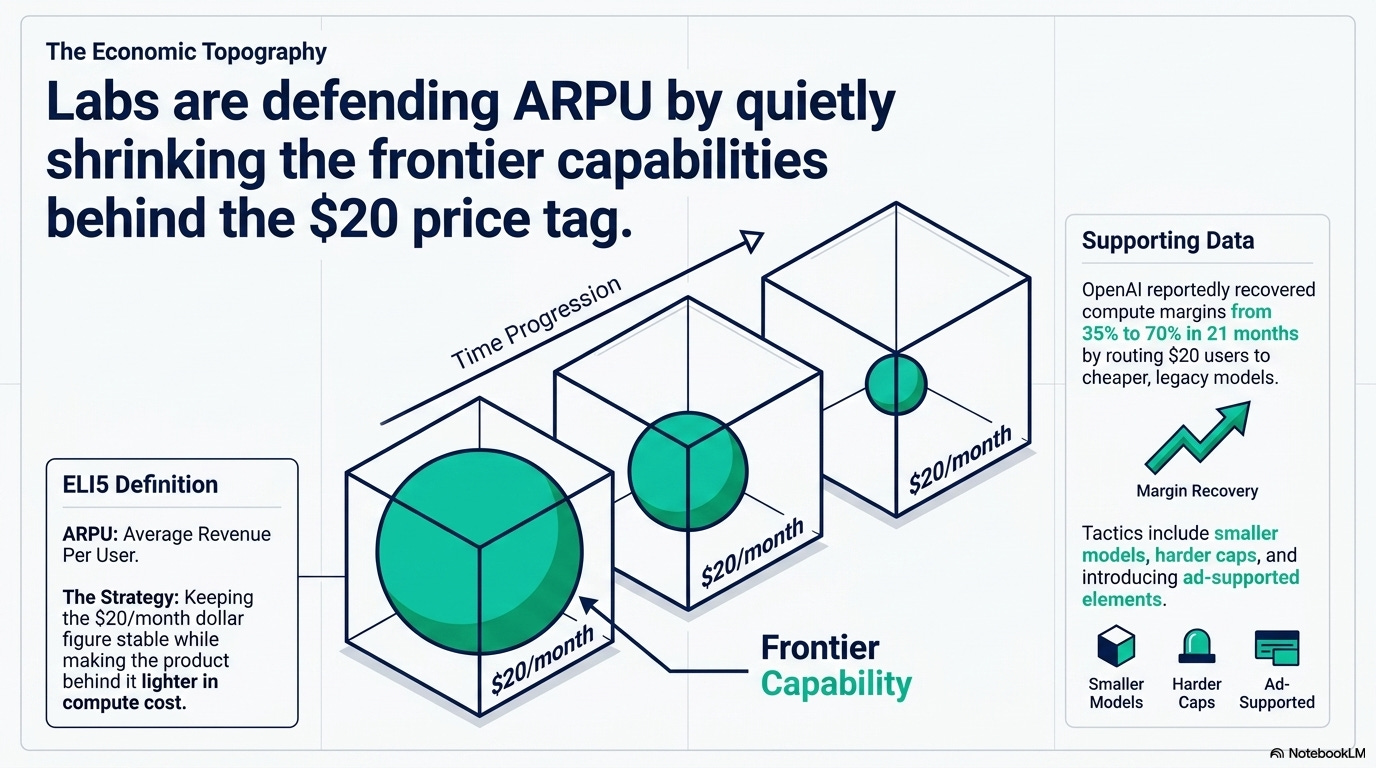
To be fair, the strongest counter is that $20 doesn’t end, it just hollows. Per-token cost is still falling 200x a year on legacy models, OpenAI reportedly recovered compute margin from 35% to 70% in twenty-one months, and a stripped $20 with ads, smaller models, and harder caps is a perfectly rational funnel for a lab defending ARPU without scaring its addressable market.
ELI5: ARPU
Average Revenue Per User — how much money a company makes per customer, on average. If a lab has 10 million subscribers paying $20/month, ARPU is $20. When they say “defending ARPU,” they mean keeping that per-customer dollar figure from dropping, even if the product behind it gets lighter in capability.
The price stays firm; the product behind it shrinks. The other honest counter is hobbyist tiers rarely impact medians in the short term. Linux capped Microsoft’s OS pricing on servers and Android, not as effectively on the desktop.
Most $20 subscribers will never touch Ollama.
What to do if you live on a $20 plan
This month: check your renewal date. Pay attention to the model dropdown in the next ChatGPT or Claude update — the good stuff quietly moves to higher-priced plans. Read the email when limits change. Anthropic announced the March 26 cutback in a short post, not a full write-up.
This quarter: pick one workflow that runs on your $20 plan and see if it survives a tier downgrade. If it does, you were never paying for the frontier. If it doesn’t, decide whether you need $100 a month of Pro or whether a local stack on hardware you already own gets you 80% of the way. Try Ollama with Llama 4 Scout, or LM Studio with Phi-4 and Gemma 4.
Yes, it takes some effort to set up. But once you’ve done it, you’ll see that there’s a hard limit on how much the cloud subscriptions can keep charging you.
If your work depends on the absolute frontier (long extended thinking, deep agentic runs, the largest context windows), the $200 to $300 ceiling is your honest price.
The $20 plan was never going to support that. For long.
If your workflow depends on a $20 frontier seat in 2026, what’s your plan when it doesn’t?
References: