

The Terraform Migration That Isn’t About Terraform
IBM’s March 31 deadline passed. The free tier is gone. And most teams are asking the wrong question about what to do next.

March 31, 2026 came and went. The Terraform Cloud free tier is officially dead.
If your team was running anything beyond a personal hobby project on Terraform Cloud’s legacy free plan, you either migrated, started paying, or woke up yesterday to a dashboard asking for a credit card.

The Slack channels and Reddit threads have a predictable split. Half the posts are migration war stories. The other half are some version of “we’re just going to pay it.”
Both camps are treating this as a pricing event. I think it’s an architecture referendum that most teams have been avoiding for a couple of years, and the bill finally came due.
How we got here: open source to IBM asset
Terraform launched in 2014 from HashiCorp, founded by Mitchell Hashimoto and Armon Dadgar. The timing was perfect. AWS had been around for eight years, but infrastructure management still meant clicking through web consoles or writing CloudFormation templates that read like XML nightmares.
Terraform offered something different: declarative infrastructure as code that worked across every cloud provider.
Write what you want in HCL (HashiCorp Configuration Language). Terraform figures out how to make it happen. The same syntax works for AWS, Azure, GCP, and 3,000+ other providers.
It was open source under the Mozilla Public License 2.0. The community exploded. By 2025, Firefly’s State of IaC report measured 90% adoption across the industry.
Think of Terraform like a universal remote for cloud services. Instead of logging into AWS, Azure, and Google Cloud separately and clicking buttons, you write a recipe file that says “I need two servers here, a database there, and a network connecting them.” Terraform reads the recipe and builds it all, no matter which cloud you’re using.
Then August 2023. HashiCorp switched Terraform to the Business Source License (BSL), a restrictive license that allows use but prohibits building competing products. Not quite open source, not quite proprietary. Within weeks, Gruntwork, Spacelift, Harness, Env0, and Scalr announced OpenTofu: a fork under the original open-source license. The Linux Foundation adopted it.
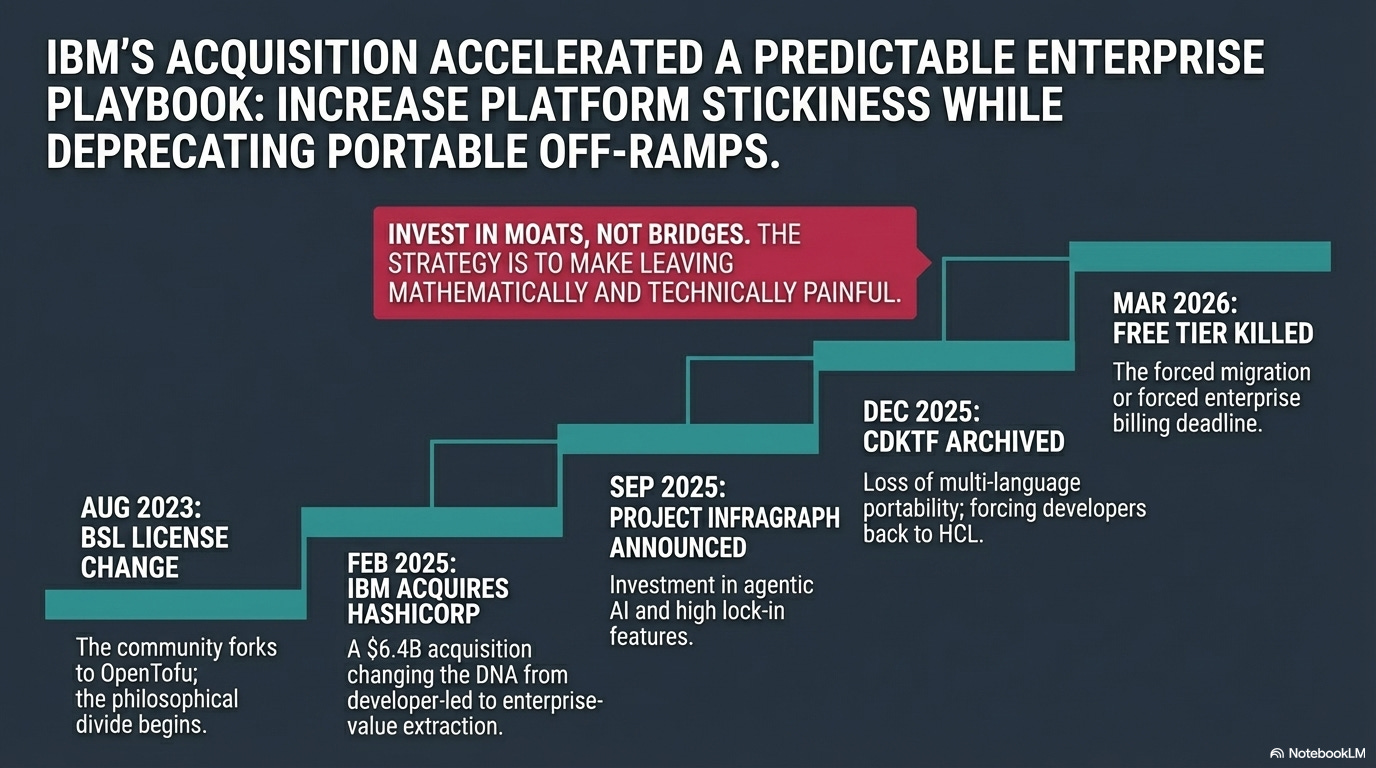
Then February 27, 2025. IBM acquired HashiCorp for $6.4 billion. Enterprise software veterans shrugged. IBM’s playbook is predictable. Buy the market leader. Rationalize pricing. Extract value from the installed base.
Then March 2026. The free tier disappeared. Pricing jumps to $0.10 per resource per month (Essentials), $0.47 (Standard), or $0.99 (Premium). A team managing 10,000 resources on Premium is now looking at $118,800 per year. You could perhaps hire a platform engineer for that, and they’d actually build something.
And then, almost as a footnote: in December 2025, IBM archived the Cloud Development Kit for Terraform (CDKTF), the tool that let developers write infrastructure in Python, TypeScript, Java, or C# instead of HCL.
The official reason? “Did not find product-market fit at scale.” The practical effect? If you’d built your infrastructure workflow around writing Python instead of HCL, you just got told to go back to HCL or find your own way.
CDKTF was like being able to write your cloud recipes in any language you already knew. IBM shutting it down is like a restaurant saying “we know you liked ordering in English, but from now on, the menu’s only in French.”
The pattern hiding behind the pricing change
The CDKTF sunset isn’t a one-off. It fits a pattern that keeps replaying across enterprise tech.
MongoDB switched to a restrictive source-available license in 2018. The community forked it. Elasticsearch followed in 2021. Redis in 2024. Terraform in 2023. Each time, the community response was the same: fork it, build it independently, move on.
What “open source” actually means (and why the distinction matters)
To understand why the community reacted so strongly, you need to know what was actually lost. I have been a big fan of open source but the term “open source” gets thrown around loosely in enterprise conversations, usually meaning “we can see the code.”
The reality is more specific, and the differences are worth underatanding.
The license spectrum, explained simply:
Copyleft (GPL, AGPL): “If you modify and share this, you must share your modifications too.” If you build on GPL code, your additions inherit the same obligation. Companies can use it internally without sharing, but the moment they distribute, the code stays open.
Permissive (MIT, BSD, Apache 2.0): “Do whatever you want, just keep the copyright notice.” Companies can take the code, modify it, make it proprietary, sell it. Most commercial open-source adoption runs on permissive licenses because they impose almost no obligations. Gemma 4 release from Google today uses this.
Business Source License (BSL): “Look but don’t compete.” You can read the code, run it, even modify it for internal use, but you cannot build a competing product. After a set time period (typically 2-4 years), it converts to a genuine open-source license. This is what Terraform uses now.
Source-available: You can see the code but don’t have the rights the Open Source Definition requires. It’s transparency without freedom.
There’s a history here. In the 1980s, Richard Stallman articulated the principle that software freedom isn’t about price, it’s about control. “Free as in speech, not free as in beer.” His four freedoms: the right to run, study, redistribute, and modify software. The GPL was designed to make those freedoms permanent and inheritable, so no downstream user could strip them away.
Then in 1998, Christine Peterson proposed the term “open source” because “free software” confused people (they kept hearing “zero cost”). Tim O’Reilly convened a summit that voted for the new label 9 to 6. Stallman wasn’t invited. The rebranding preserved the code-sharing practice but stripped the philosophical claim about user rights. As George London puts it: “Open source became a development methodology that corporations could adopt without changing their relationship to their users at all.”
Then SaaS made even the open-source distinction feel academic. When software runs on someone else’s servers, having the source code doesn’t help. The GPL’s sharing obligation triggered on distribution, not on running code. SaaS never distributes. The four freedoms became theoretical for most users. This is exactly why MongoDB, Elasticsearch, and Redis changed their licenses: cloud providers were running their open-source code as a service, capturing all the revenue, and sharing none of the code back because they weren’t technically distributing anything.
This context matters for the Terraform story.
BSL is none of the above traditional categories. It’s a new breed: source-available but not open source by any recognized definition, time-delayed open source (it eventually reverts), but controlled by a corporation that can change terms at will. When we say “Terraform went from open source to BSL,” that’s a philosophical category change dressed up as a licensing update. The community didn’t fork over features. They forked over freedom.
But the Terraform situation breaks this pattern. Elastic reversed course. In early 2024, Elastic moved Elasticsearch and Kibana back to an open-source-approved AGPL license, explicitly citing the damage the restrictive license had done to community trust. Redis followed a similar path. The companies that controlled these projects realized that restrictive licensing was costing them more in community goodwill than it was protecting in revenue.
Terraform hasn’t reversed. And with IBM as the owner, it almost certainly won’t. I’d love to be wrong on this one. Different ownership structure entirely. HashiCorp was a publicly traded company that needed developer adoption to grow. IBM is a $180 billion enterprise that bought HashiCorp for its installed base, not its community.
The CDKTF shutdown reinforces this potential. IBM is investing in features that increase platform stickiness while removing features that reduced vendor dependency. Invest in moats, not bridges. If you’ve watched what happened to Lotus Notes, Informix, or Rational after IBM acquired them, this looks familiar. Enterprise features got investment. Community and developer tools got deprecated. Red Hat and Ansible is the exception, not the rule - perhaps there is hope.
In practice: If your team built CDKTF-based workflows, say TypeScript modules that let frontend developers provision their own staging environments, you now need to either rewrite everything in HCL or migrate off Terraform entirely. Neither is small. For teams with 50+ CDKTF modules, budget a quarter of engineering time.
The IBM contradiction
The complication: IBM isn’t just squeezing. They’re also investing.
In September 2025, HashiCorp previewed Project Infragraph, a real-time infrastructure knowledge graph designed for agentic orchestration. The pitch: AI agents will understand your entire infrastructure topology, dependencies, and drift state, and can make autonomous decisions about provisioning and remediation. IBM has 16 open engineering positions on the Terraform team. Development velocity, by at least one practitioner’s account, has increased since the acquisition.
So which is it? Is IBM killing Terraform or investing in it? It appears to be both.
IBM is investing in the features that potentially makes Terraform Cloud stickier to the Enterprise users: infrastructure graphs, agentic automation, enterprise governance.
These are features that increase switching costs. At the same time, IBM is removing the features that made Terraform more portable. External language support (CDKTF), the free tier that let small teams evaluate without commitment, and the open-source license that let competitors build on the same foundation.
In practice: A CIO evaluating Terraform’s roadmap might look at Project Infragraph and say “IBM is serious about innovation.” That’s true. But the innovation is pointed at lock-in, not openness. Infragraph makes your infrastructure data more valuable inside IBM’s ecosystem. It doesn’t make it easier to leave.
Classic enterprise software strategy. Make the product better for paying customers while making the exit ramp steeper. Oracle has been running this play for 30 years.
The real question: does the value Infragraph creates exceed the optionality it removes?
To be fair
The “IBM is extracting value” framing is an easy target. It runs the risk of being incomplete. IBM has 16 open engineering positions on the Terraform team. Development velocity has measurably increased since the acquisition. Project Infragraph is an ambitious technical bet, not a cost-cutting exercise dressed up in a press release.
For a CIO running 5,000+ resources across multiple clouds in a regulated industry, the integrated governance story that IBM is building might actually be worth the premium. Lock-in and value creation aren’t mutually exclusive. Oracle has proven that for three decades. Run the numbers: if Infragraph reduces your mean time to infrastructure remediation by 40%, does it matter that switching costs went up? For some organizations, the answer is genuinely no, operational outcomes over philosophical preferences about software licensing. The mistake would be making that trade without acknowledging you’re making it.
The market options: four lanes, not one
While IBM was restructuring Terraform’s economics, the competitive landscape was assembling itself into four distinct lanes.
Lane 1: Sovereign (OpenTofu). The open-source fork has now surpassed 10 million downloads, 25,000+ GitHub stars, and 70+ active contributors. The Cloud Native Computing Foundation (CNCF) accepted it into its Sandbox in April 2025. OpenTofu 1.11 already has features Terraform doesn’t have: ephemeral resources that keep credentials in memory (never persisted to state), write-only attributes for secrets, cleaner conditional syntax.
One practitioner reported migrating from Terraform 1.14.7 to OpenTofu 1.11.5 in ten minutes with zero infrastructure changes.
Lane 2: Orchestrated (Spacelift, env0). Spacelift closed a $51 million Series C in July 2025. Its customer list (Redfin, Figma, 1Password, Moody’s, Duolingo, SailPoint) reads like a who’s who of companies that take infrastructure governance seriously.
On March 18, 2026, Spacelift launched two products that reframe the entire IaC conversation: Spacelift Intelligence (AI-powered analysis of infrastructure patterns, cost anomalies, and drift) and Spacelift Intent (natural language infrastructure provisioning).
Spacelift’s co-founder Marcin Wyszynski called it bringing “vibe coding to infrastructure provisioning.” That framing is worth paying attention to.
If a product manager can type “I need a staging environment that mirrors production but with smaller instance sizes and a 4-hour auto-shutdown” and get a working Terraform plan, HCL fluency stops being a requirement. The governance layer, who can deploy what, where, under what conditions, becomes the only thing that matters.
The platform is engine-agnostic by design.
Spacelift works with Terraform, OpenTofu, Pulumi, CloudFormation, Ansible, and Kubernetes. The IaC engine underneath is a pluggable component, not a commitment. This matters because it decouples the “which engine” decision from the “which management platform” decision entirely.
Policy enforcement runs on Open Policy Agent (OPA). Write Rego policies like “no S3 buckets without encryption” or “all EC2 instances must have backup tags” and they’re enforced at plan time, before anything touches production. Developers never interact with raw Terraform state. They work through Spacelift’s abstraction layer, which means a misconfigured policy blocks a deployment before it starts, not after an incident report.
The pricing model is per-worker (execution environment), not per-resource like Terraform Cloud. Costs scale with deployment frequency, not infrastructure size. For teams with large resource counts but moderate deployment cadence, say 15,000 resources but only 200 runs per month, this can be dramatically cheaper than Terraform Cloud’s per-resource billing.
One caveat worth noting: self-hosted Spacelift is missing some Azure and GCP cloud integrations that the SaaS version includes. If you self-host for data residency reasons, verify that the integrations your team needs are available in that deployment model before committing.
Spacelift Intelligence, launched alongside Intent in March 2026, analyzes infrastructure patterns across all your stacks, surfaces cost anomalies, predicts drift before it causes incidents, and recommends optimization. Think of it as a consultant that watches every deployment and learns what “normal” looks like for your organization, then flags when something deviates.
In practice: A mid-market SaaS company with 300 engineers and 8,000 resources across AWS and GCP is paying Terraform Cloud $45,000/year on Standard tier. They switch to Spacelift with 10 workers. Their developers request infrastructure through Spacelift’s self-service portal, OPA policies enforce tagging and encryption standards automatically, and Intelligence catches a cost anomaly where a team left GPU instances running in a dev environment for three weeks. The Spacelift bill is lower, but the real savings come from the governance automation they couldn’t build themselves.
Imagine telling Siri “set up a test version of our website that turns off at midnight to save money” and having it actually work, with all the right security rules applied automatically. That’s what Spacelift Intent is trying to do for cloud infrastructure.
Lane 3: Platform-native (Harness). Harness raised $240 million at a $5.5 billion valuation in December 2025 (Goldman Sachs led). On track to exceed $250 million in annual recurring revenue. Their angle is different from Spacelift’s: infrastructure management isn’t a standalone problem, it’s part of the software delivery pipeline.
Harness is a full software delivery platform, not just an IaC tool. The IaC Management (IaCM) module sits alongside Continuous Integration, Continuous Delivery, Feature Flags, Cloud Cost Management, Service Reliability Management, Security Testing Orchestration, and Software Engineering Insights.
Eight modules, one platform, one vendor relationship. For organizations tired of stitching together fifteen SaaS tools with custom glue code, that consolidation could be attractive.
The IaCM module shipped in 2024, making it roughly 18 months old. Most published Harness case studies showcase CI/CD, not IaCM specifically. The strongest IaCM reference is an unnamed global bank that deployed 4,000 workspaces in six months using templates.
“Several dozen enterprise customers” is the honest number for IaCM adoption, which is candid marketing for “early.”
The platform’s CI/CD reputation is battle-tested. The IaCM module is still earning its stripes.
The self-hosted option (Self-Managed Platform, or SMP) is still in Beta, not GA. Cost estimation doesn’t work in the self-hosted version. Air-gapped environments need extra configuration work. For organizations that require on-premises deployment for regulatory reasons, that Beta status is a real constraint, not a footnote.
AIDA (AI Development Assistant) is built into every module. For IaC specifically, it analyzes failed deployments, suggests remediation steps, auto-generates rollback plans, and explains why a policy check failed in plain English. When a Terraform plan fails an OPA check at 2 AM, AIDA can tell the on-call engineer what went wrong, why the policy exists, and what to change, without requiring that engineer to understand Rego syntax.
Harness’s thesis, articulated in their Series E pitch, is that AI solved the “writing code” problem but created a new gap between code generation and production deployment. They call it the “after code gap.” Code gets written faster than ever, but the pipeline between code and production (testing, security scanning, compliance checks, staged rollouts, observability) hasn’t sped up proportionally. Their platform sits in that gap.
Infrastructure changes in Harness go through the same approval workflows, canary deployments, and rollback mechanisms as application code. No separate process for infra versus app. A Terraform plan gets the same staged rollout treatment as a microservice deployment: deploy to 5% of environments, verify metrics, expand to 25%, verify again, then full rollout.
If drift is detected, the same rollback pipeline that handles application failures handles infrastructure failures.
The Harness 2026 State of DevOps Modernization report found that 73% of organizations lack standardized infrastructure templates, and teams using heavy AI code generation see a 22% deployment remediation rate. Meaning AI is writing infrastructure code faster than organizations can govern it.
In practice: An enterprise financial services company with 1,200 developers runs Harness across the full delivery lifecycle. A developer uses GitHub Copilot to generate a Terraform module for a new payment processing service. The code enters the Harness pipeline, where AIDA flags that the security group allows inbound traffic from 0.0.0.0/0, a PCI-DSS violation. The pipeline blocks, AIDA suggests the correct CIDR range, and the developer fixes it before the plan ever runs. The same pipeline handles the application deployment, the feature flag rollout, and the cost monitoring. One platform, one audit trail, one place to look when something breaks.
Lane 4: Backend swap (Scalr). There’s a fourth option most IaC analysis misses. Scalr isn’t an orchestration platform or a DevOps suite. It’s a remote operations backend, a drop-in replacement for Terraform Cloud. The pitch: point your existing Terraform CLI workflows at Scalr instead of TFC. Your engineers keep running terraform plan and terraform apply exactly as they do today. The backend changes. The workflow doesn’t.
Scalr’s hierarchy (Account, Environment, Workspace) was designed for multi-team governance. Environments are true isolation boundaries: variables, policies, credentials, and RBAC are all scoped at that level. One team literally cannot see another team’s workspaces. For organizations with globally distributed teams at different skill levels, that clean isolation model with zero workflow disruption is compelling.
The pricing is per-run, all features included, no tiering. Self-hosted agents can run in each region’s cloud subscription, keeping state files local while centralized governance stays consistent.
The tradeoffs are real. Scalr supports Terraform and OpenTofu only (no Pulumi, Ansible, or CloudFormation). The company has $7.35M in total funding, 48 employees, and roughly $5.3M in annual revenue. It’s profitable and bootstrapped, which is a survival advantage, but a 48-person company backing a global enterprise standard is a concentration risk. The review corpus is thin: TV4 (Sweden’s largest commercial TV network) migrated 1,000 workspaces and reported being “very happy” after a year, but large-scale enterprise references beyond that are limited.

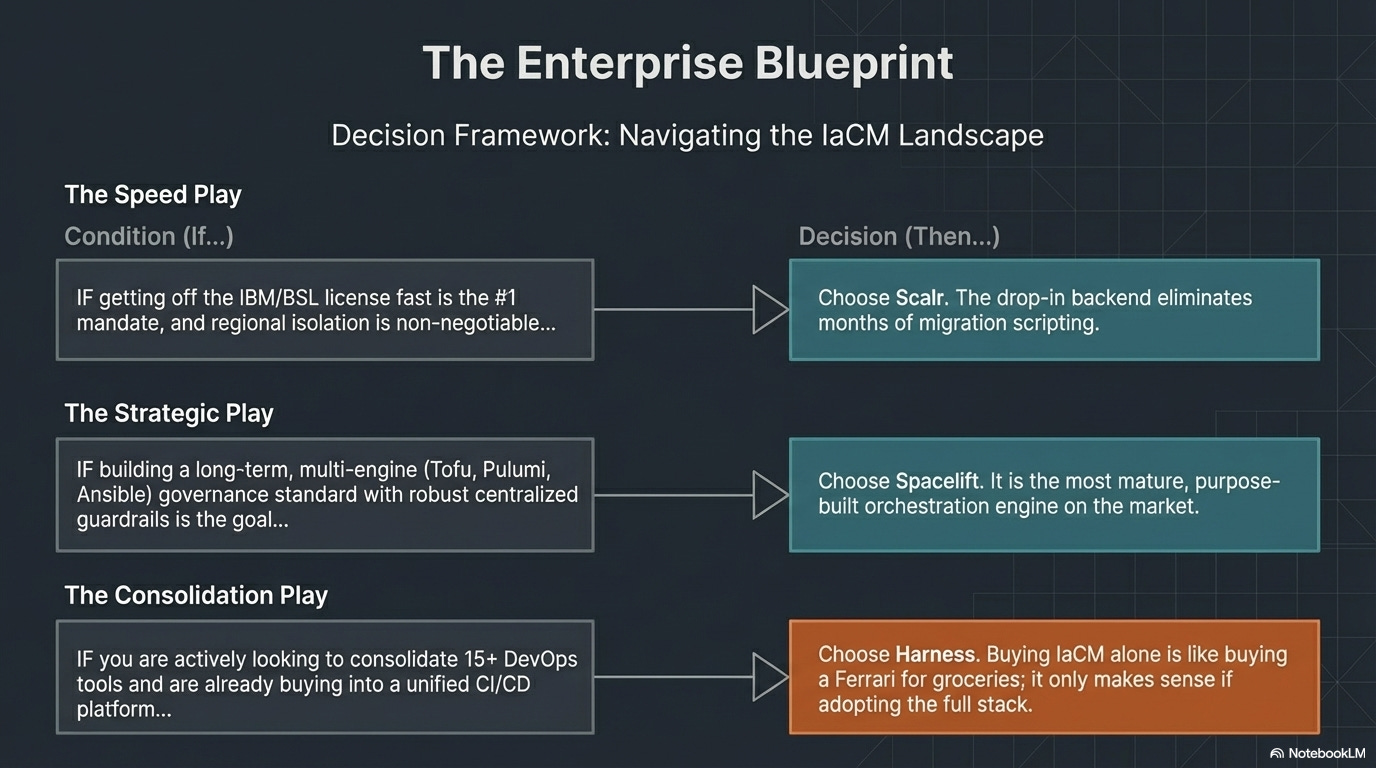
The right choice depends on where your organization places its complexity budget, not which tool has more checkboxes on a feature comparison.
Head-to-head: Terraform Cloud vs. Spacelift vs. Harness vs. Scalr
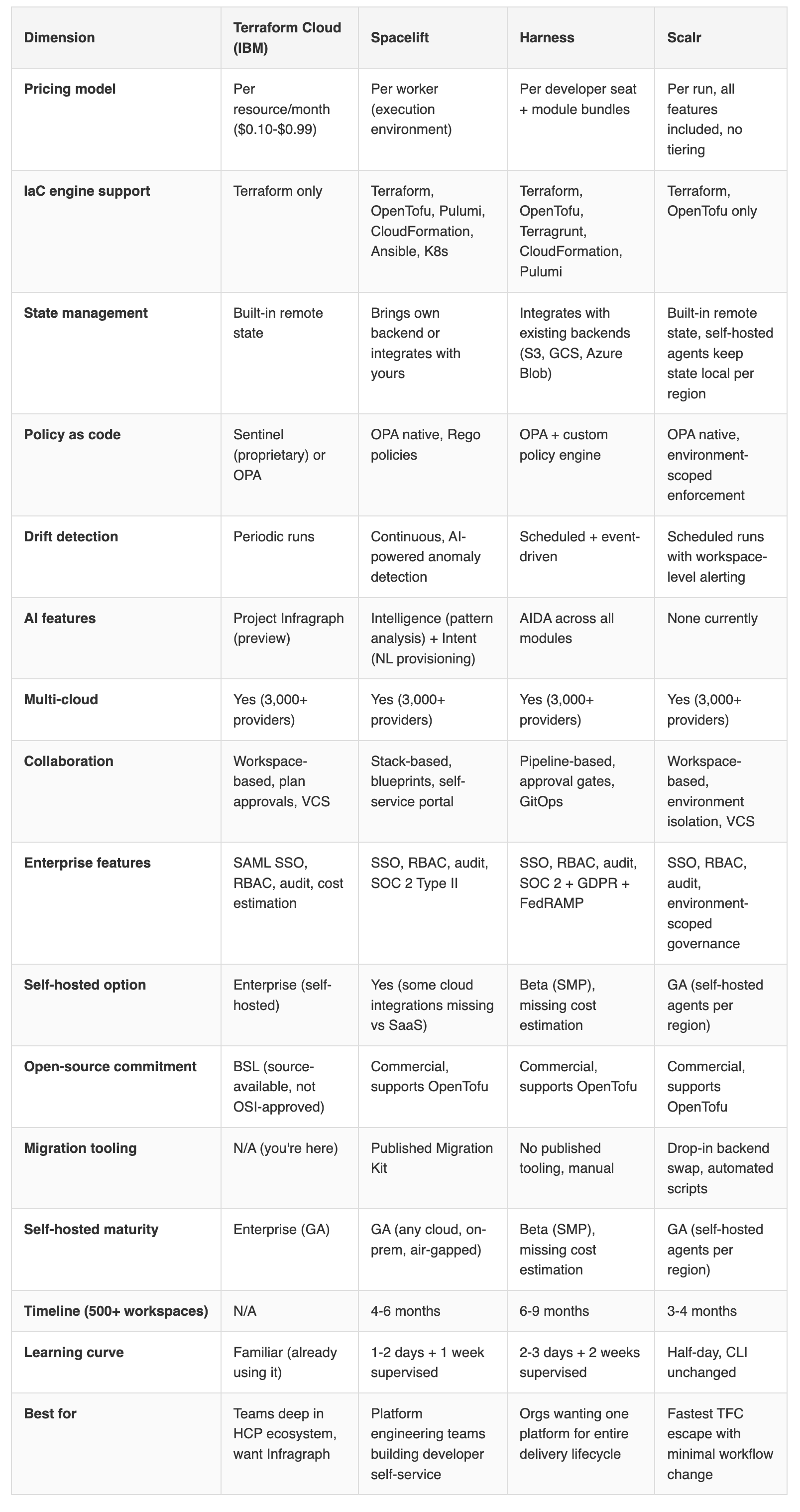
No table makes this decision for you. The comparison above shows capability parity on most dimensions.
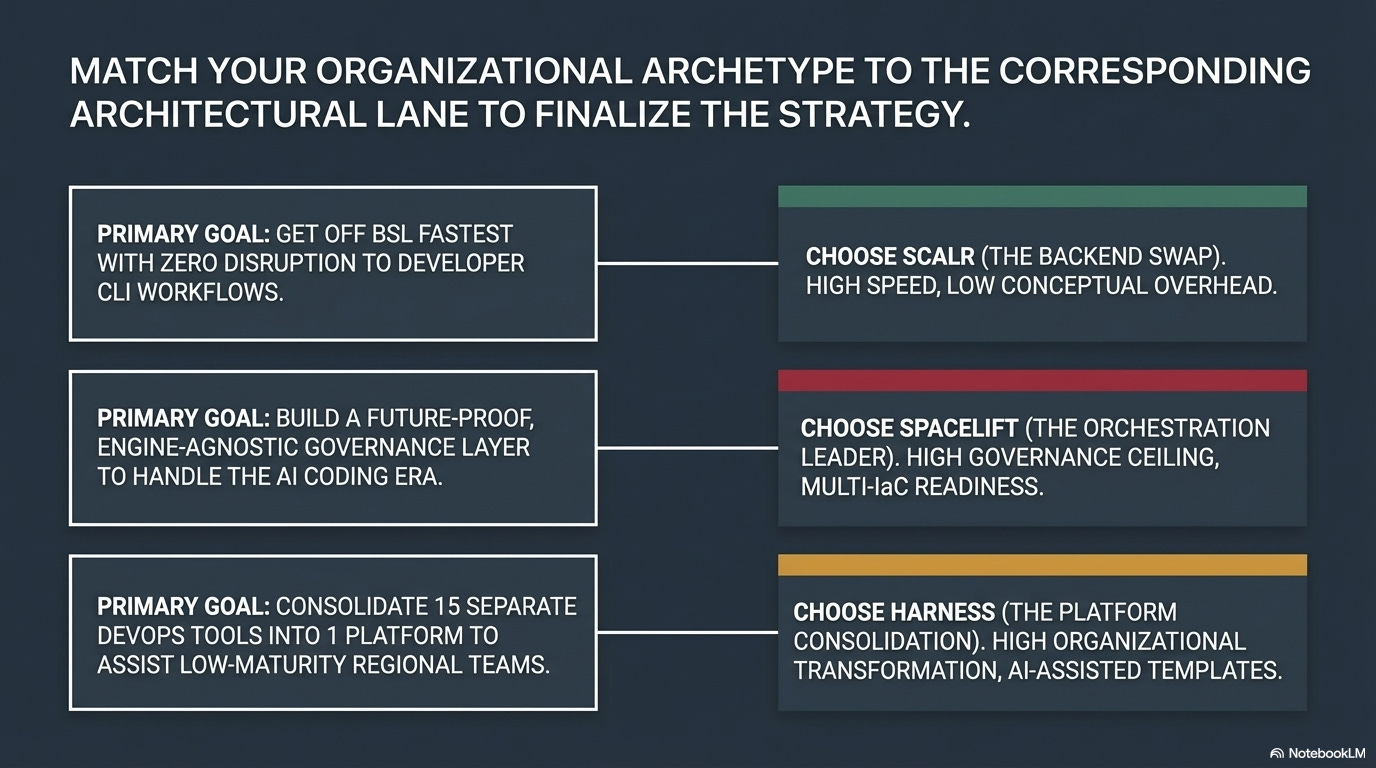
The real differentiator is philosophy:
do you want a standalone IaC platform (Terraform Cloud),
an engine-agnostic governance layer (Spacelift),
IaC as one module inside a broader delivery platform (Harness), or
the fastest possible TFC escape with the least disruption (Scalr)?
The answer depends on which problem you think you’re solving.
What real users actually say
Every vendor comparison cherry-picks features. The more useful question is what actual users complain about after six months of production use. Here’s what the G2, PeerSpot, and Capterra reviews surface when you filter out the marketing.
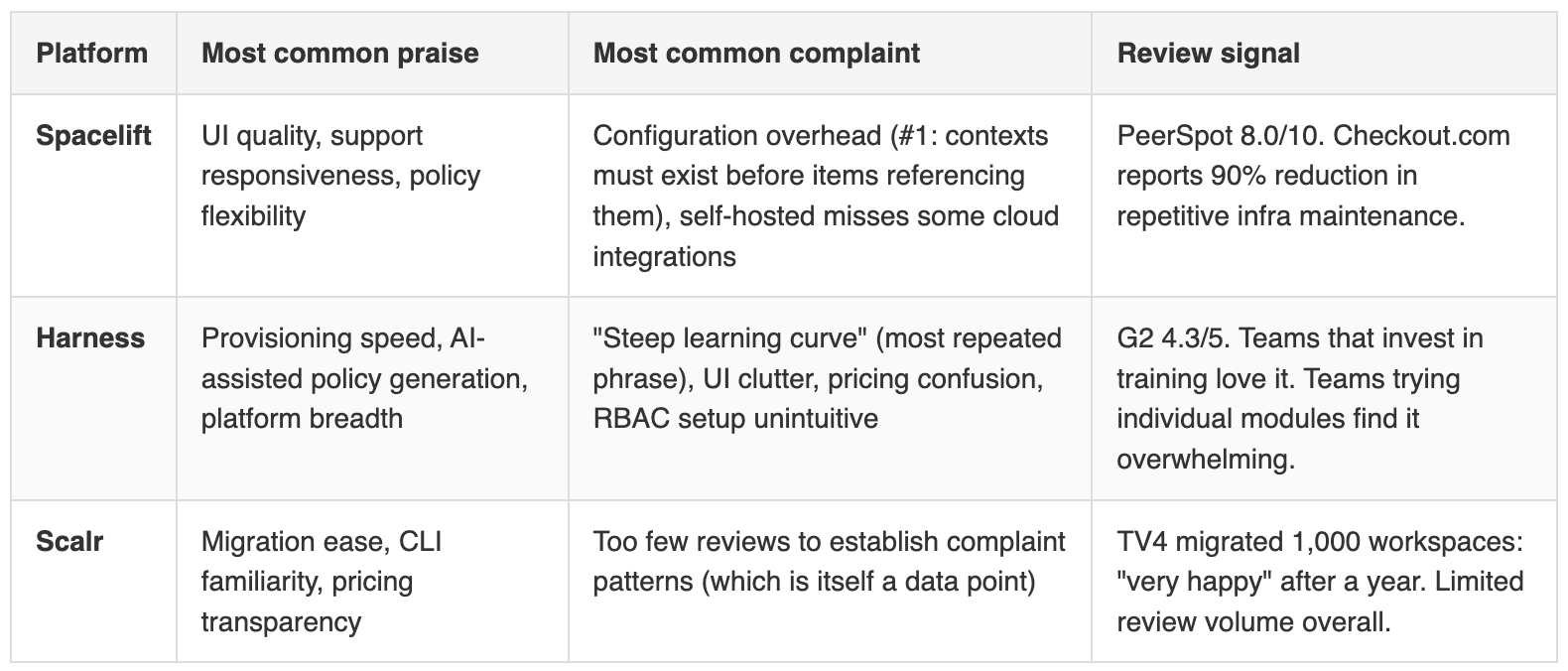
Harness’s learning curve complaint isn’t a minor gripe. It appears in nearly every critical review. Concepts like services, environments, pipelines, templates, delegates, and connectors all have Harness-specific meanings that take weeks to internalize. For organizations with teams at different skill levels across different regions, this is a material implementation risk. You can’t assume that the team in Mumbai and the team in Dallas will absorb the same training at the same speed. Multiply that onboarding cost by every new hire, every team rotation, every contractor onboarding.
Spacelift’s config overhead is less severe but creates real friction during onboarding: you hit a chicken-and-egg problem where adding configuration items requires contexts to already contain those items. The workaround is straightforward once you know it, but it trips up every new user. Spacelift’s support team is responsive enough that most teams get past it quickly, which is why the praise and the complaint coexist in the same reviews.
Will these companies exist in 5 years?
Every enterprise buyer asks this question. Here’s the data:
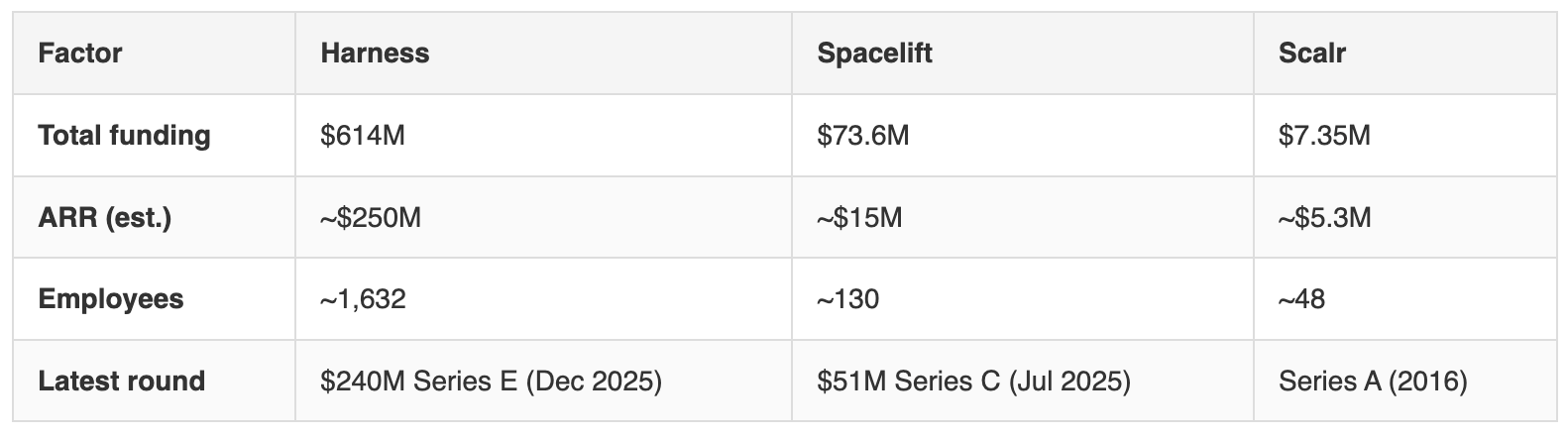
Harness is the safest bet on company survival: $5.5B valuation, Goldman Sachs backing, approaching IPO scale. The risk isn’t that Harness dies. It’s that IaCM stays a secondary module and never gets the investment attention that CI/CD gets.
Spacelift is well-funded for its stage, with infrastructure orchestration as its entire business, an existential commitment to the problem.
Scalr is profitable and bootstrapped, which is genuinely a survival advantage over VC-dependent companies, but 48 people supporting enterprise-scale deployments is concentration risk. If a key engineer departs, your platform roadmap feels it.
The AI velocity paradox nobody’s pricing in
There’s a deeper signal here.
Harness’s finding, the 22% deployment remediation rate among heavy AI coders, connects to the IaC market in a way most analysis misses. If AI generates infrastructure code faster than humans ever could, the bottleneck isn’t authoring HCL or writing Pulumi programs. The bottleneck is governance. Who reviews the AI-generated plan? Who catches the misconfigured security group? Who enforces that Frankfurt customer data stays in EU-Central-1?
The IaC engine, Terraform, OpenTofu, Pulumi, Crossplane, is becoming a commodity.
What matters is the layer above it: policy enforcement, drift detection, cost controls, compliance audit trails.
That’s where Spacelift and Harness are placing their bets.
Spacelift Intent takes this one step further. If natural language can provision infrastructure, HCL fluency isn’t a moat anymore. The IaC language wars (HCL vs. Python vs. TypeScript vs. YAML) may be a distraction. Within two to three years, the authoring layer could be irrelevant. The governance layer won’t be.
George London, CTO of Upwave, recently argued that AI coding agents could make free software matter again. His point: Stallman’s four freedoms assumed you needed to be a programmer to exercise them. If an AI agent can read, understand, and modify source code on your behalf, access to source code stops being a symbolic right for developers and becomes a practical capability for anyone. A product manager who can’t write HCL could ask an agent to customize their infrastructure workflow, but only if the code is actually accessible.
Apply that to the IaC context. When agents can generate and modify infrastructure code, the question of whether that code runs on an open engine (OpenTofu) or a source-available one (Terraform BSL) stops being philosophical and starts being operational. An agent can fork, patch, and extend OpenTofu. It cannot do the same with Terraform’s BSL-licensed code without IBM’s permission. The license isn’t just a document in a repo. It’s the boundary of what your agent can do.
In practice: A platform engineering team debating “should we migrate to OpenTofu or Pulumi?” might be asking the wrong question entirely. The better question: “Who governs the infrastructure code that AI is about to start generating at scale?” If the answer is “nobody, we’ll review it manually,” that works at 50 deployments a month. It breaks at 500.
Same structural pattern we covered in AI Waypoints Edition #1.
Enterprise signals that look like pricing stories on the surface but are actually architectural inflection points underneath.
What this means: this month and this quarter
This month:
Audit your actual exposure. How many resources is your team managing? Multiply by $0.10 (Essentials) and $0.47 (Standard). If the annual number is under $5,000, this may not be worth a migration. If it’s over $50,000, you owe your leadership a formal options analysis.
Check your CDKTF exposure. If any of your infrastructure workflows depend on CDKTF, start planning the rewrite now. IBM archived it in December 2025 and won’t be maintaining it.
Read your Terraform Enterprise contract renewal terms. Some teams are discovering pricing changes they didn’t expect. Know what you’re signing before auto-renewal kicks in.
This quarter:
Run a proof-of-concept migration. One practitioner reported Terraform-to-OpenTofu migration in ten minutes for a simple project. Real enterprise migrations with 50+ workspaces, Sentinel policies, and compliance frameworks take 6-12 months. The PoC tells you whether you’re in the “ten minutes” or “twelve months” camp.
Evaluate the orchestration layer independently from the engine. Spacelift works with both Terraform and OpenTofu. Harness is engine-agnostic. Scalr is a direct backend swap. The “which IaC engine” decision and the “which management platform” decision are separate. Don’t conflate them.
Factor AI into the timeline. If your organization is adopting AI code generation for infrastructure (GitHub Copilot for Terraform, Spacelift Intent, or internal tools), governance becomes urgent. The 22% remediation rate Harness found isn’t getting better on its own.


What to watch:
Whether IBM offers meaningful price concessions before Q3 renewal season. If they do, the pricing was a market test, not a strategic shift. If they don’t, plan accordingly.
OpenTofu’s CNCF graduation timeline. Sandbox status is fine. Graduated status signals long-term institutional backing.
Whether Elastic and Redis’s license reversals put pressure on IBM to reconsider the BSL. The pattern exists. The structural incentives against it are strong. But stranger things have happened.
Is your team treating the Terraform deadline as a pricing problem or an architecture problem? I’m collecting migration stories. Hit reply if you’re in the middle of this decision. The patterns are more useful than any vendor comparison chart.
References: