

Monotheist vs Polytheist: How to Choose Your Agentic AI Architecture
Stop asking which agent architecture is smarter. Ask whether your task splits into independent pieces.


Every leader has made this hire.
You can bring on one brilliant generalist who holds the whole problem in their head, or a team of specialists with someone to coordinate them.
You already know how each one fails.
The generalist becomes a bottleneck the day they’re out sick. The team spends Tuesday in a standup about Monday’s handoff.
This spring, that same hire became an architecture decision, and the two biggest names in enterprise software made it in opposite directions.
On April 22, OpenAI shipped Workspace Agents: one persistent agent per workflow, schedulable, carrying its own context, integrating 60-plus connected apps through a single thread. The company called it “an evolution of GPTs,” powered by Codex: one capable agent doing everything, better. Not pitched as an orchestration play.
Three weeks later, at Sapphire in Orlando, SAP introduced the Autonomous Enterprise: more than fifty domain-specific “Joule Assistants“ orchestrating over two hundred specialized agents, no generalist anywhere in the picture.
Each agent is scoped to a domain (finance, HR, procurement, supply chain) with governance embedded at the agent level. CEO Christian Klein drew the line in one sentence: “’Almost right’ just isn’t good enough.”
80%, he meant, is not good enough when you run the world’s most business-critical processes. SAP’s named outcome was RWE cutting unplanned offshore-wind-turbine downtime by feeding sensor data to AI that does its own root-cause analysis and files its own work orders (SAP-reported).
Same problem.
Enterprise workflow automation, same price point, same spring-2026 window, opposite architectures.
OpenAI is betting a smarter single thread is the unlock. SAP is betting that process-specific specialists with governance baked in are the only thing you can trust with mission-critical ERP. These are platform vendors, not two customers running a bake-off, so neither is “proof.” But they’re the two architectures you’re choosing between, which is the point.
I’ll lay out both lanes and let you place yourself. There’s no universal right answer, and the people selling you one are usually selling you their product. But once you know which question you’re answering, it’s easier to pick the right agentic architecture for the right use case.
ELI5: What are we even arguing about?
An “AI agent” is a model you hand a goal instead of a single question, and it takes a series of steps on its own to get there: reads, calls a tool, checks the result, tries again.
The monotheist bet says use one capable agent per task and let it run the whole job start to finish.
The polytheist bet says split the job across several narrower agents and have one coordinator stitch their work back together.
Same goal, two ways to wire it up.
Naming the two camps
I’m calling the camps monotheist and polytheist because it stuck in my head and it beats “single-agent versus multi-agent.”
One god-model that does everything, or a pantheon of smaller gods, each with a domain, coordinated by a planner above them.
Monotheist: one generalist agent, one continuous context, working the task on a single thread. If you need to handle more work, you run more copies of that one agent. OpenAI’s Workspace Agents is the picture: one thread, dozens of apps, no orchestrator.
Polytheist: an orchestrator that decomposes the request and routes the pieces to specialist agents, then assembles the result. SAP’s Autonomous Enterprise is the picture: fifty coordinators, two hundred specialists, no generalist.
Those are the two choices. The rest of the decision is about which one fits the work in front of you.
The tools and the evidence point opposite directions. What the industry is building bets polytheist. The research, once you compare on equal cost, leans monotheist. Some teams have only seen one side of this, so let me show you both before I get to the decision tool.
The tell is in the plumbing
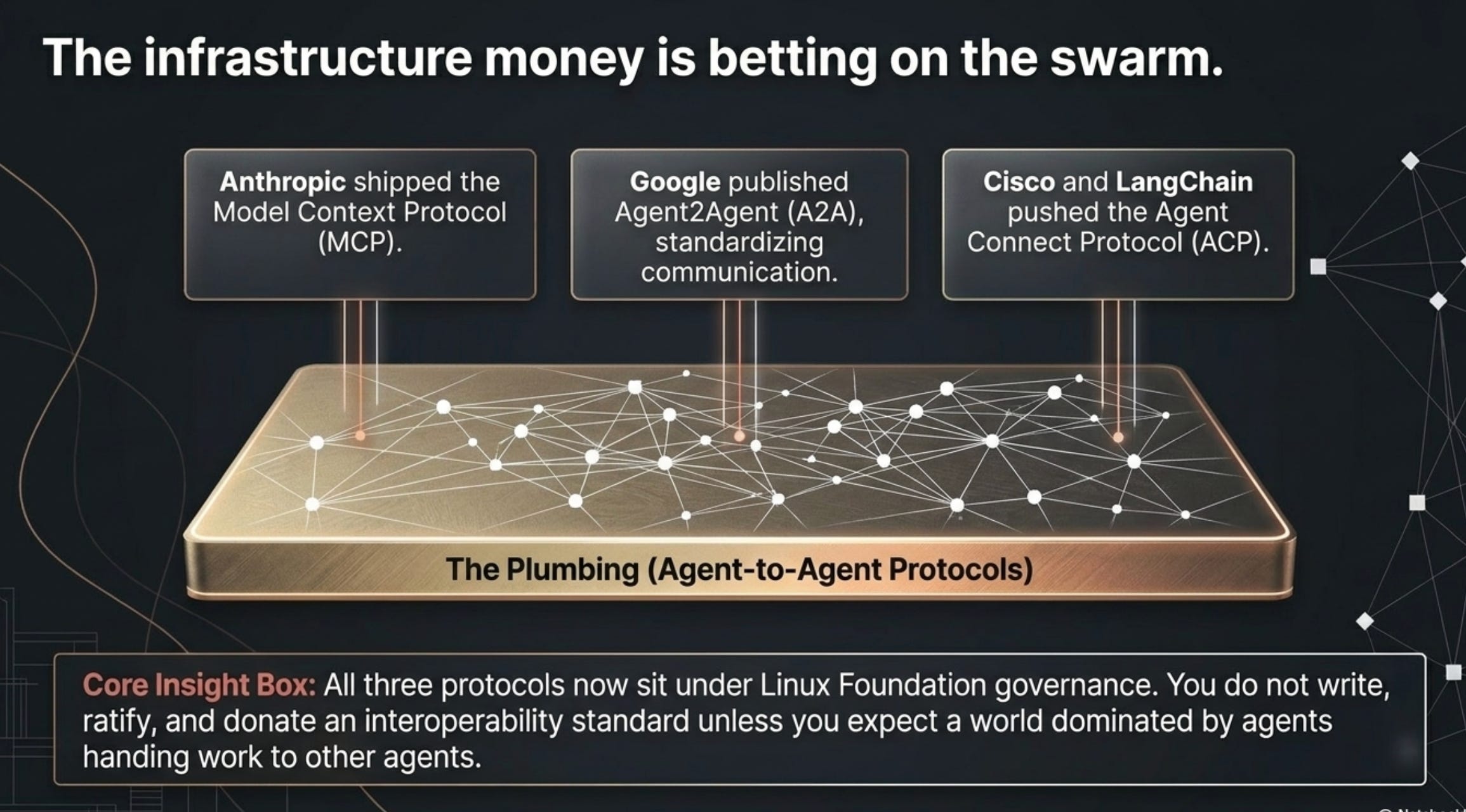
If you only watched what the AI labs said, you’d think the field was split down the middle. If you watch what they built into the wiring, the field already placed its bet, and it bet polytheist.
In the last year, every major lab shipped a protocol whose only reason to exist is agents talking to other agents. Anthropic published the Model Context Protocol (MCP). Google published Agent2Agent (A2A), which standardizes agent-to-agent communication across frameworks and vendors, and donated it to the Linux Foundation. Cisco and LangChain pushed the Agent Connect Protocol (ACP).
All 3 protocols now sit under Linux Foundation governance, and a joint MCP/A2A specification is expected in the back half of 2026.
You don’t write, ratify, and donate a standard for how agents hand work to each other unless you expect a world with a lot of agents handing work to each other. The toolmakers, the ones who make money no matter which side wins, are betting on the polytheist camp.
OpenAI is the partial holdout at the product layer, and Workspace Agents is its thesis stated plainly: bet that a single strong reasoning model is capable enough to make orchestration premature.
Subagents are on the roadmap, but the wager is that the model keeps absorbing the work a swarm would have done.
This picture isn’t unanimous. But the infrastructure money (the standards, the governance, the interoperability plumbing) points squarely at a future where you’re running a swarm of agents.
Which would be a tidy story, except the evidence pulls the other way.
The evidence has a stubborn habit
When researchers actually control for compute, the swarm’s advantage shrinks, and sometimes it flips.
That qualifier, “control for compute,” decides everything here. “Control for” is research shorthand for holding a variable equal on both sides of a test, so the comparison measures what you actually care about and not something else.
Give the single agent and the swarm the same total budget to think with, then ask which one wins.
Compute here means tokens, roughly a word’s worth of text the model reads or writes, billed per token, so more thinking and more agents means more money. Most published wins for multi-agent systems were measured against a single agent that got far fewer tokens. The swarm had three or four agents each burning a full thinking budget, so of course it scored higher. It also cost three or four times as much.
The honest comparison gives the single agent the same total budget the swarm used, then asks who wins.
Two papers from this year do exactly that, and the findings are stark.
The first, from Tran and Kiela (arXiv:2604.02460, April 2026; a preprint, not yet peer-reviewed), says it in the title: single-agent language models outperform multi-agent systems on multi-hop reasoning when you hold the thinking-token budget equal.
Their argument rests on a result from information theory called the Data Processing Inequality, which in plain terms says every time you pass information through another step, you can only lose detail, never gain it.
Every handoff between agents is a lossy copy.
Equalize the budget, they found, and most of the multi-agent “wins” in the literature evaporate. They were never about coordination. They were about spending more.
The second is peer-reviewed, accepted at ICML 2026, with James Zou as senior author: “Multi-Agent Teams Hold Experts Back“ (arXiv:2602.01011).
On machine-learning benchmarks, teams of agents underperformed their own best individual member by as much as 41.1%. The team did worse than the single smartest agent on it would have done alone, and not because it couldn’t find the expert. The expert was in the room. The team averaged the expert’s answer together with the mediocre ones and landed in the middle, the way a committee of a great cardiologist, a decent generalist, and an intern lands worse than the cardiologist alone.
The researchers call it integrative compromise, and it gets worse as the team gets bigger.
There’s older research backing all this up.
The MAST study from UC Berkeley (arXiv:2503.13657) read more than 1,600 execution traces across seven popular multi-agent frameworks (AutoGen, ChatDev, CrewAI, and others) and cataloged 14 distinct ways these systems fail, clustered into 3 buckets:
bad system design
agents talking past each other
nobody checking the final work
Different researchers grading the same traces mostly agreed on the categories (κ=0.88, a strong score), so this is the real pattern, not one person’s read. The failures weren’t unusual either. They were built into the setup, the kind you get any time you make agents coordinate on a problem that didn’t need them to.
So the labs are building for a polytheist world, and the research points monotheist, depending on the task. That split is the real story, and the way through it is looking at the work in front of you.
The variable that decides it
The deciding factor is whether your task can be cut into independent pieces, not how smart the model is.
If this rings a bell, it’s because I made a narrower version of this argument in April, under a duller name: the “failure gradient.“
The claim then was that task boundedness, not agent capability, decides whether an agentic system survives production.
This comes from work by Mieczkowski and colleagues (arXiv:2503.15703), and the bones of it are about sixty years old.
It’s Amdahl’s Law, the rule that governs whether throwing more processors at a computing problem makes it faster, and the answer turns entirely on how much of the work has to happen in sequence versus in parallel.
If a job is mostly a chain, where step B needs the output of step A and step C needs B, more workers don’t help, because they’re standing around waiting their turn. If a job genuinely splits into independent chunks, more workers finish it faster.
ELI5: Why adding workers doesn’t always make work faster
Picture moving day.
Two people carrying a couch through a doorway can’t go faster by adding a third, because the third person just gets in the way. But ten people unloading boxes from the truck finish in roughly a tenth the time one person would. The couch is a sequential step, the boxes are independent, and most jobs have both mixed together. The whole architecture question is figuring out which kind your work mostly looks like.
Agents obey the same law.
A second paper, from Gao and colleagues (arXiv:2505.18286), adds the uncomfortable corollary: the benefit of multi-agent systems over single agents shrinks as the models get smarter, naming o3 and Gemini 2.5 Pro among them.
Part of the original case for swarms was that you could gang several weak models together to compensate for any one being limited. Once individual models got strong enough to hold a hard problem in one context, that compensation mattered less.
Which means the line I’m about to hand you isn’t fixed. If rising capability keeps pulling work that used to need a swarm back onto a single thread, the decomposability boundary drifts toward monotheist on its own. ****
So the question to ask before you architect anything: is this task genuinely parallelizable, or am I paying a swarm tax to fake it?
ELI5: What’s the swarm tax?
Running several coordinated agents costs a lot more than running one, in money and in time. Anthropic’s own multi-agent research system uses roughly fifteen times the tokens of a single chat. If your task is a chain of dependent steps, splitting it across agents doesn’t speed anything up. The agents wait on each other, and you pay the coordination cost anyway. The swarm tax is what you spend on parallelism you’re not actually getting.
Picture a kitchen. Plating one complex dish, where the sauce reduces while the protein rests while the garnish gets cut, is a single cook’s job, because each step feeds the next and a second cook just gets in the way. Prepping ingredients for a hundred dinners is a crew’s job, because the chopping and portioning are all independent.
The dish is monotheist. The prep is polytheist.
The mistake is putting a crew on the dish and a single cook on the prep.
I built a one-page version of that test you could lift straight into a slide. Five questions, each answered for one column or the other. Count which column you land in more often, and that’s your lean, not a verdict, because most real systems end up mixing both.

When one cook beats the crew
Some work wants a single agent on a single thread, and the reasons are concrete.

Step-by-step reasoning is the clearest case.
Underwriting a policy, adjudicating a claim, working a credit decision: these are chains, where each conclusion depends on the last and the answer has to stay internally consistent from the first input to the signed output. The moment you split that across agents, you risk two of them making locally reasonable decisions that contradict each other.
Walden Yan of Cognition, who literally wrote a post called “Don’t Build Multi-Agents,“ summed up the problem in one line:
“Actions carry implicit decisions, and conflicting decisions carry bad results.”
His example was two subagents asked to clone Flappy Bird, neither aware of the other: one rendered a Super-Mario-style background, the other an off-model bird, and the art styles didn’t match. The pieces worked. The product was incoherent.
Work that changes things and has to stay coherent fits here too. If the agent is changing state, whether that’s moving money, modifying records, or committing code, you want one writer with one view of the world, not a committee that might clobber each other’s edits.
Cost- and speed-sensitive tasks with predictable outcomes fit here too. If you know what the task looks like and it runs a thousand times a day, the swarm tax is a recurring bill you’re paying for nothing, when one tuned agent is cheaper and faster.
And regulated decisions that need exactly one auditable trace. When a regulator or a court asks “who made this call and on what basis,” you want a single, continuous record of how the decision got made, with one accountable owner. A fragmented multi-agent record, where the reasoning is scattered across a planner and six workers and a shared scratchpad, is an auditor’s nightmare and a compliance team’s liability. “Which agent decided this” won’t hold up under audit.
OpenAI’s Workspace Agents is one real exemplar, by design. The other I find genuinely interesting is Andrej Karpathy’s single-agent research loop, which he described this spring during what he called the “loopy era“: one agent running something like 700 experiments over two days and surfacing 20 useful additive wins, with his own role reduced to “remove yourself as the bottleneck, take yourself outside.”
One agent, looping, with a human reviewing the output instead of micromanaging the steps.
The ways the single-agent lane breaks are real.
This is the brilliant generalist out sick, showing up in the architecture: one thread, one point of failure. Long-running tasks suffer from context rot, the way one cook plating the dish forgets the sauce reduction once you keep walking back and adding to the order. Cognition’s own observation: an agent “performs worse when you keep telling it more after it starts.“ Give one agent too many tools and it gets confused about which to use.
And there’s a well-documented attention problem the research literature named “lost in the middle“: Liu and colleagues (TACL 2024) showed that models reliably lose accuracy on information buried in the middle of a long context window, even when it’s right there to retrieve. Chroma’s more recent testing put a number on it, a 30%-plus accuracy drop on long-context retrieval.
ELI5: What’s a context window and what’s “context rot”?
A context window is the model’s short-term memory: everything it can “see” at once for a given task, measured in tokens. It’s finite. Context rot is what happens when you cram too much in. The model starts losing track, especially of whatever sits in the middle, the way you’d forget the middle items on a 40-item grocery list you tried to memorize. More isn’t always better. Past a point, more is worse.
When the crew beats one cook
Other work genuinely wants a crew, and the reasons are just as concrete.
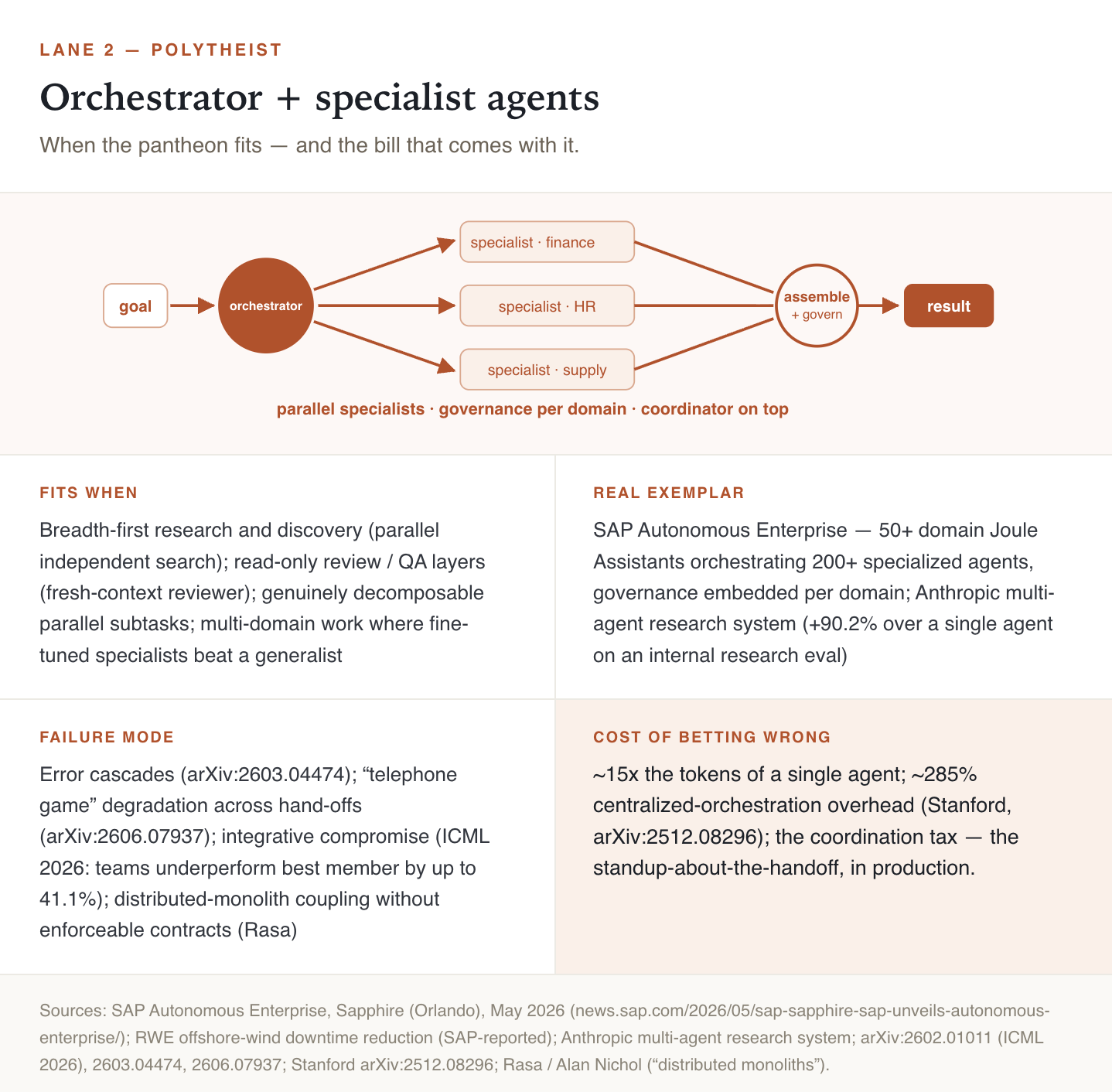
Four cases where the crew earns its cost:
1. Breadth-first research and discovery. When you need to explore many independent directions at once, whether that’s surveying a landscape, gathering sources, or chasing parallel leads, splitting the work across agents is a real speedup, because the pieces don’t depend on each other.
This is exactly where Anthropic landed.
Its multi-agent research system, the one running at roughly 15x the tokens of a single chat, beat its single-agent baseline by 90.2% on an internal research evaluation. Their own words: “Even generally-intelligent agents face limits when operating as individuals; groups of agents can accomplish far more.”
But read the fine print they published alongside it: it works for breadth-first problems with independent directions, and fails on tasks with tight interdependencies.
They told you the boundary, and the boundary is decomposability.
2. Read-only review and quality layers. You can run a separate reviewer agent, with fresh context, whose only job is to check the primary agent’s work. Cognition, the “don’t build multi-agents” people, later shipped exactly this: a read-only reviewer agent that catches roughly two bugs per pull request, 58% of them severe. It never writes; it just reads with fresh eyes and flags problems. The original monotheist critique was about write conflicts, agents stepping on each other’s changes. It said nothing against a second agent that only reads.
3. Genuinely decomposable parallel subtasks. Anything that really does break into independent chunks, like the kitchen prep for a hundred dinners. The crew finishes faster because the chopping and portioning don’t depend on each other.
4. Multi-domain problems where fine-tuned specialists beat a generalist. This is where the open-weights story comes in and changes the math, in a minute. SAP’s whole Autonomous Enterprise is a bet here, plus a quieter governance argument: when each agent is limited to one area and carries its own rulebook, you can enforce the rules agent by agent, instead of trusting one generalist to stay inside the lines across every area at once.
That’s the polytheist answer to control, and it’s a real one: many tightly bounded threads instead of one accountable one.
In practice: a retailer building a customer-service flow that genuinely spans returns, billing, and shipping (three independent domains) can route each to a specialist that’s better at its slice than any generalist would be. A pharma company’s twenty agents reading twenty papers in parallel beat one agent reading them in sequence, because the readings don’t depend on each other.
The ways this lane breaks are as real as the single-agent ones.
This is the standup side of the org-design hire, in production: the coordination tax.
Errors cascade, one agent’s mistake becoming the next agent’s input, what researchers have documented as a “telephone game” where the message degrades at each hop (arXiv:2606.07937, arXiv:2603.04474).
Picture an order moving down the line: the server writes “medium-rare,” the line cook reads “medium,” the plater calls it “well-done,” and what reaches the table is everyone’s best guess at what the diner asked for.
The integrative-compromise problem from that ICML paper really shows up here, the 41.1% drop, the same cardiologist-and-intern committee landing in the middle. And the token cost is the 15x, because you’re paying for a full prep crew even when the order is one dish. There’s also a subtler structural trap that I think is the most important warning in this whole debate.
The distributed-monolith trap
Alan Nichol, who runs Rasa, summed it up in October 2025: “multi-agents are secretly distributed monoliths.”
Over the last decade, software moved away from giant single applications, called monoliths, toward “microservices,” small independent services that each do one job and talk to each other over strict, enforced contracts. Microservices work because those contracts are real: service A literally cannot send service B a malformed request, because the contract rejects it at the door.
Now look at a multi-agent system.
The agents hand work to each other in natural language, and natural language is not an enforceable contract.
Nothing stops one agent from sending another a vague, ambiguous, or subtly wrong instruction, because “please summarize the customer’s issue“ has no schema that rejects a bad summary.
So you get all the coordination cost of a distributed system (the handoffs, the latency, the failure points) with none of the independence guarantee that made it worth the cost. You’ve rebuilt a monolith and spread it across a network where it’s harder to debug.
A lot of teams are about to discover that the expensive way.
The open-weights wildcard
Here’s where the polytheist economics get genuinely interesting.
The pantheon’s weak spot has always been cost.
Running a crew of frontier-model agents through somebody else’s API, at 15x the tokens, gets expensive fast.
Open-weights models, the ones you can download and run on your own hardware, knock the legs out from under that problem three ways at once. They use a design called mixture-of-experts, where a huge model only activates a small slice of itself per request (a “1.6-trillion-parameter” model might fire only 49 billion at a time).
They can be quantized (storing each number inside the model with less precision, the way you’d round 3.14159 to 3.14), compressing it to roughly a quarter of the memory with minimal quality loss. And they can be fine-tuned on your own data on your own machines, so the proprietary stuff never leaves the building.
For a financial-services or insurance or healthcare shop staring at data-sovereignty rules, that last point is very critical.
ELI5: What’s “mixture-of-experts,” and why does it make a swarm of specialists cheap?
A mixture-of-experts model is one giant model internally divided into many sub-networks, but it only switches on the few relevant ones for each request instead of all of them. Think of a hospital with two hundred specialists on staff, but any one patient only sees the three relevant to their case. The hospital is huge; each visit is cheap because most of the building stays idle. So a model can be a trillion parameters in total but only fire forty billion per question, which is what makes a swarm of cheap specialists economically real.
The full global field matters here, and it isn’t only an American story. The open-weight performance charts in 2026 are led, uncomfortably for some readers, by Chinese labs.
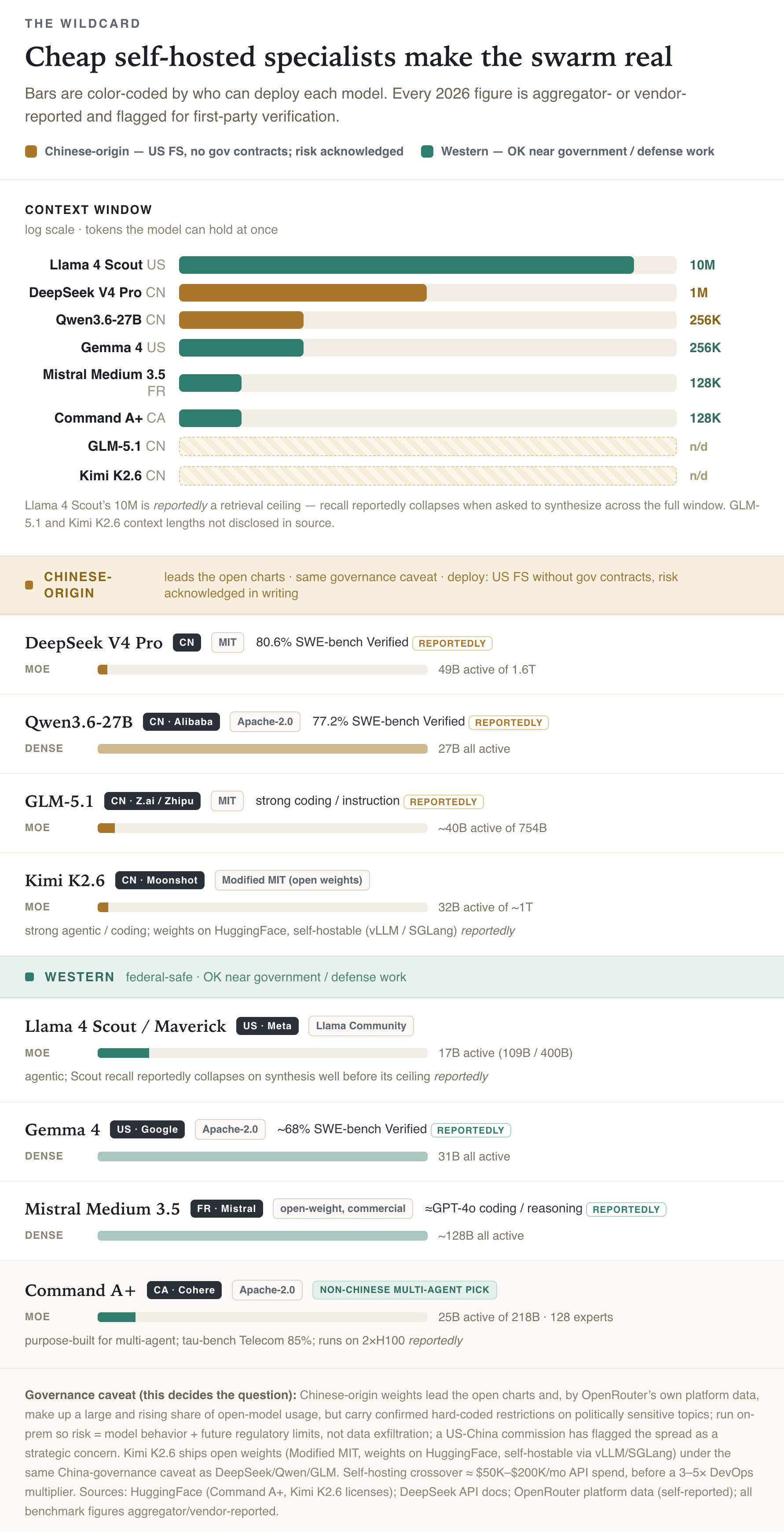
Every benchmark below is reportedly-so until first-party verified, since these come from aggregators.
Chinese-origin (all four carry the same governance caveat):
DeepSeek V4 Pro — reportedly hit 80.6% on SWE-bench Verified, among the highest of any open-weight model.
Alibaba Qwen 3.6 — in the conversation on the leaderboards.
Z.ai GLM-5.1 — same.
Moonshot Kimi K2.6 — ships open weights under a Modified MIT license and self-hosts the same way the others do.
Western:
Meta Llama 4 Scout — reportedly ships a 10-million-token context window, though its recall reportedly collapses when asked to synthesize across that full window rather than just retrieve from it.
Google Gemma 4 — rounds out the field.
Mistral Medium 3.5 (France) — same.
Cohere Command A+ (Canada) — the one I’d flag for anyone building a pantheon: reportedly purpose-built for multi-agent work, and it runs on two H100 graphics cards rather than a data center.
There’s a catch.
Chinese-origin open weights lead the performance charts and, by OpenRouter’s own platform data, make up a large and rising share of open-model usage. They also carry documented restrictions on politically sensitive topics. Because you run these on your own hardware, the risk is the model’s behavior on certain inputs (not data walking out the door), and the possibility of future regulatory restriction, since the US posture toward Chinese open-source models is hardening and US policy bodies have already flagged their spread as a strategic concern.
So what you do depends on who you are.
A US financial-services firm with no government contracts can deploy DeepSeek, Qwen, GLM, or Kimi today, eyes open, risk acknowledged in writing. Anyone with federal or defense adjacency should stay on Llama, Gemma, Mistral, Command A+, or Phi, full stop.
And the rough economic line for self-hosting at all sits somewhere around $50,000 to $200,000 a month in API spend before it pencils out, and even then only after you multiply your DevOps headcount by three to five to keep the thing running.
The cheap-specialist swarm is real. It’s just not free, and the bill moves from your API invoice to your payroll.
Where the builders landed
The most interesting signal in this whole debate is a convergence nobody planned.
Start with the two loudest opposite voices.
Cognition published “Don’t Build Multi-Agents” in June 2025.
Anthropic published “How We Built Our Multi-Agent Research System” and posted the 90.2% number.
About as far apart as the field gets, rhetorically. And yet, look at the topology each one shipped after a year of production reality, and they land in the same place: a single agent owns all the writes and stays on one thread, while any additional agents are read-only and run in parallel.
Cognition got there by adding that read-only reviewer agent to its single-writer system.
Months after telling everyone not to build multi-agents, it published “Multi-Agents: What’s Actually Working,” and the reversal was narrow and useful: multi-agent setups work when writes stay single-threaded and the extra agents add intelligence, not actions.
Anthropic got there from the other side, building an orchestrator that fans work out to subagents who explore in parallel but never write to a shared notebook and never talk to each other, with all coordination living in the one orchestrator on top. Different starting philosophies, same answer.
I’m presenting that as an observation, not advice.
It looks to me like the field discovering, the expensive way, that the monotheist critique was right about one specific thing, that you can’t have multiple agents writing and deciding at cross-purposes, and silent about another, that a second agent which only reads is a genuine intelligence multiplier with none of the conflict risk.
Andrew Ng, who I trust on this because he’s architecture-agnostic to a fault, has been saying a version of this for a while. He lists four agentic design patterns, in roughly the order you should reach for them:
Reflection — the agent reviews its own draft and revises before handing back the answer.
Tool use — the agent calls outside services (search, code execution, APIs) instead of working only from what it already knows.
Planning — the agent breaks the goal into ordered steps before doing any of them.
Multi-agent collaboration — multiple agents split the work and coordinate.
Multi-agent collaboration sits at the fourth slot for a reason: it’s the advanced move, not the default. Reach for it when the task earns it, not because the plumbing exists.
The cost of betting wrong
All of this would be an interesting architecture debate if the stakes were theoretical.
They aren’t.
KPMG published a report titled “Total Experience: Redefining Excellence in the Age of Agentic AI.“ As the Financial Times and The Register reported on June 12, 2026, an AI-assisted review found that only 5 of its 45 citations correctly matched their sources, and case studies the report attributed to UBS, Swiss Federal Railways, Transport for London, and Emirates were fabricated or unverifiable.
UBS told the Financial Times the claims about it were “factually incorrect.”
KPMG withdrew the report.
So the right read is that even the advisors aren’t immune to the very problem they’re paid to manage, and it’s the one either architecture has to defend against.
A confident wrong answer with no error signal is exactly what you get when you over-orchestrate work that needed one coherent chain, or when you trust a single thread past the point where its context rots.
The architecture doesn’t make the failure go away. It just changes which direction it comes from.

And this isn’t a one-off.
A Sinch survey found that 74% of enterprises have rolled back at least one deployed AI customer-service agent. Gartner forecast, back in June 2025, that more than 40% of agentic AI projects will be canceled by the end of 2027 (a forecast, not a count, so weight it as a projection). You can bet wrong in both directions.
Both directions have a real cost.
Pick the pantheon on sequential work, and you build a distributed monolith that’s slower and pricier than what it replaced.
Pick the single generalist on parallel work, and the competitor’s swarm finishes first.
The expensive move is picking a lane before checking what the task actually needs.
Where this leaves you, by role
No verdict, because the verdict depends on your task.
But here’s what each seat in the room should do with this.
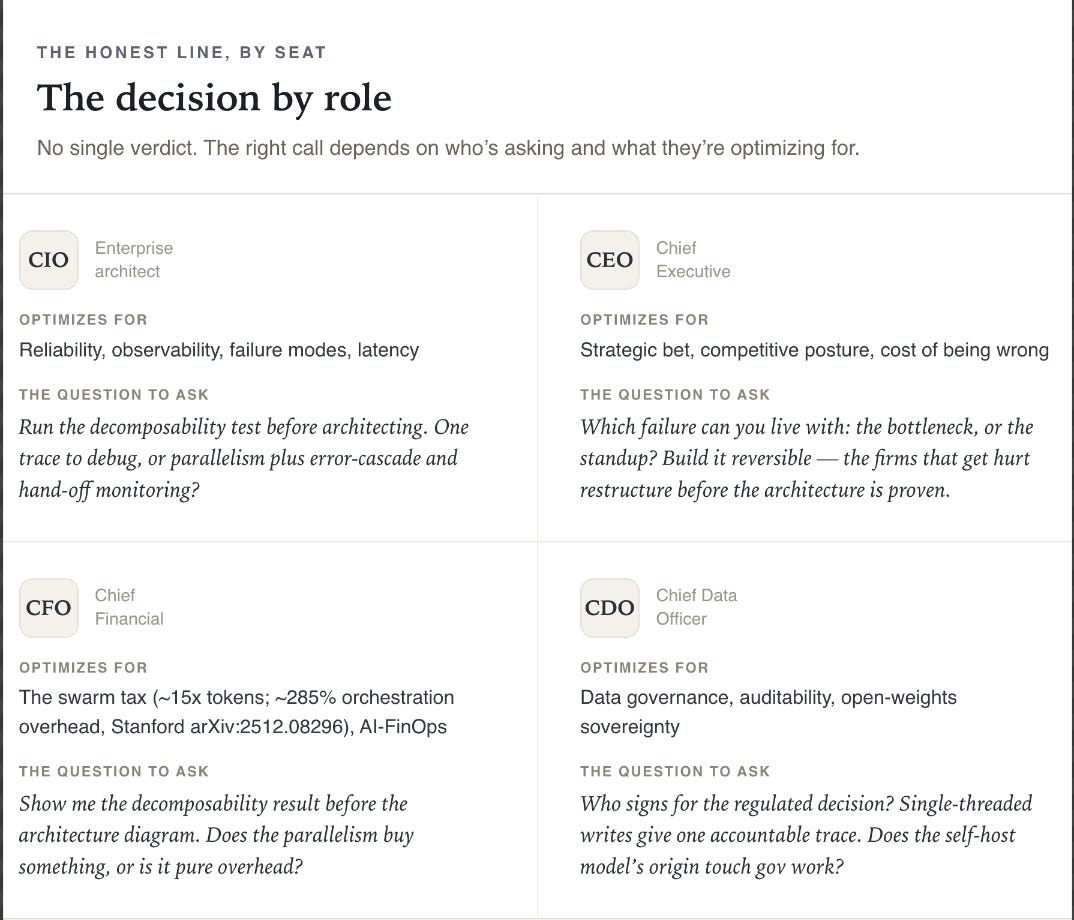
If you’re the enterprise architect or CIO, the decomposability test goes first on every workflow. MCP and a slick multi-agent demo can talk a team into orchestrating a problem that was always sequential, and a multi-agent failure is much harder to trace than a single-agent one. If you go polytheist, the monitoring needs to be ready before you need it.
If you’re the CEO, this is a strategic bet with a real cost of being wrong, and it’s reversible if it’s built that way. The firms that get hurt restructure irreversibly around an architecture before it’s proven on their actual work. A pilot on a workload that matters, with the option to switch intact, is the cheaper path.
If you’re the CFO, the swarm tax is a real line item, easy to miss until the invoice lands. A multi-agent setup can cost on the order of 15x the tokens of a single agent. That spend is justified when the task is genuinely parallel and the speedup or quality gain is real, and it’s waste when the task was a chain.
AI cost should sit in the budget with an owner, the way cloud spend does. And before any multi-agent architecture gets funded, the case for why the task actually splits up needs to be on paper.
If you’re the chief data officer, the open-weights sovereignty play is the one easy to miss and hard to reverse. Self-hosting fine-tuned specialist models behind your own firewall keeps proprietary data in the building, gives you an auditable trail, and lets you build the pantheon without renting it.
The China-governance question lands on your desk along with it, and so does accountability. For a regulated decision you have to defend as one call, a single accountable trail answers “who signed?” A trail scattered across six agents can’t.
Where governance has to hold across many domains at once, specialists limited to one area with their own rulebooks can be easier to enforce than trusting one generalist everywhere. Either way, the auditor belongs in the room as much as the engineer.
Circle back to the hire we started with.
You’d never settle the generalist-versus-team question by reading an essay. (albeit a good one as this one :-) )
You’d look at the work sitting on the desk and ask what shape it has. The architecture decision is the same kind of decision. It isn’t a belief to hold about which approach is smarter. It’s a shape to match, and the decomposability test is how you see it.
The question is which kind of failure you can live with: the bottleneck, or the standup.
Which lane is your hardest current workflow on, and how confident are you that you checked, rather than guessed?
References:
OpenAI Workspace Agents (announced April 22, 2026; one persistent agent per workflow, 60+ connected apps, “an evolution of GPTs, powered by Codex”; Rippling ~5–6 hrs/week outcome, vendor-reported): openai.com
SAP Autonomous Enterprise (Sapphire, Orlando, May 2026; 50+ Joule Assistants, 200+ specialized agents; CEO Christian Klein quotes; RWE offshore-wind outcome SAP-reported): news.sap.com
KPMG “Total Experience: Redefining Excellence in the Age of Agentic AI”: withdrawal, GPTZero forensic review (5/45 citations matched), fabricated UBS / Swiss Federal Railways / Transport for London / Emirates case studies, UBS “factually incorrect” to the FT; coverage June 12, 2026 — Financial Times and The Register
[link TK — confirm specific articles]Sinch enterprise survey: 74% of enterprises rolled back ≥1 deployed AI customer-service agent (vendor-reported) — sinch.com
[link TK — confirm survey page]Gartner forecast (June 2025): 40%+ of agentic AI projects canceled by end of 2027 (FORECAST, not a count) — gartner.com press release
[link TK — confirm specific release]Tran & Kiela, “Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets,” arXiv:2604.02460 (April 2026, preprint; not peer-reviewed)
Zou et al., “Multi-Agent Teams Hold Experts Back,” arXiv:2602.01011 (ICML 2026, peer-reviewed; up-to-41.1% underperformance vs. best member)
“Why Do Multi-Agent LLM Systems Fail?” (MAST), UC Berkeley, arXiv:2503.13657 (March 2025; κ=0.88)
Mieczkowski et al., task-decomposability / Amdahl’s Law derivation, arXiv:2503.15703
Gao et al., “benefits of MAS over SAS diminish as LLM capabilities improve,” arXiv:2505.18286
Multi-agent error-cascade / “telephone game” analyses, arXiv:2603.04474 and arXiv:2606.07937
Stanford, “Towards a Science of Scaling Agent Systems,” arXiv:2512.08296 (~285% centralized-orchestration overhead)
Liu et al., “Lost in the Middle: How Language Models Use Long Contexts,” TACL 2024 — arXiv:2307.03172 (coined the term); Chroma long-context testing
[link TK — confirm specific post](~30%+ drop)Cognition: “Don’t Build Multi-Agents” (June 2025) and “Multi-Agents: What’s Actually Working” by Walden Yan
[link TK — confirm second post URL]Anthropic, “How We Built Our Multi-Agent Research System” (June 13, 2025)
Alan Nichol (Rasa), “multi-agents are secretly distributed monoliths” (October 2025) — rasa.com blog
[link TK — confirm specific post]Andrew Ng, four agentic design patterns — DeepLearning.AI “The Batch”
[link TK — confirm specific issue]Andrej Karpathy, single-agent research loop (”loopy era,” March 2026)
[link TK — tweet or talk URL]MCP (Anthropic), A2A (Google)
[verify], ACP (Cisco/LangChain)[link TK], Linux Foundation governance[link TK]Open-weights model figures (DeepSeek V4 Pro, Qwen3.6, GLM-5.1, Kimi K2.6 [open-weight, Modified MIT], Llama 4 Scout, Gemma 4, Mistral Medium 3.5, Command A+): aggregator/vendor-reported via Artificial Analysis and Hugging Face Open LLM leaderboard, reportedly-so until first-party verified
OpenRouter platform data: Chinese-origin open models a large and rising share of open-model usage — openrouter.ai
[link TK — confirm rankings page]