

2026 State of Cloud Disaster Recovery
Iran’s drone strikes proved that geographic separation and resilience aren’t the same thing. The entire DR playbook needs rewriting.

March 1, 2026. Somewhere after 2 AM local time, Iranian Shahed 136 drones struck two of three AWS availability zones in ME-CENTRAL-1 (UAE) simultaneously and one AZ in ME-SOUTH-1 (Bahrain). Fire. Power disruption. Water damage from suppression systems. AWS declared the affected zones “hard down.”

Abu Dhabi Commercial Bank, Emirates NBD, First Abu Dhabi Bank, Hubpay, Alaan, Snowflake, Careem. All experienced service disruptions.
AWS issued an advisory that read:
“We recommend that customers with workloads running in the Middle East take action now to migrate those workloads to alternate AWS Regions.”
No recovery timeline. Just three words:
“Recovery will be prolonged.”
This was the first time in history that commercial data centers were deliberately targeted during armed conflict. Not collateral damage from a nearby strike. Not a cyber intrusion. Drones flying at physical infrastructure built to survive power outages and hard drive failures, not explosions.
A month later, on April 2, the IRGC claimed a strike on an Oracle data center in Dubai Internet City. Dubai’s Media Office confirmed “minor incident resulting from fall of shrapnel” after interception.
Between those dates, the IRGC named 18 US companies (Microsoft, Google, Apple, Meta, Oracle among them) as “legitimate targets.” The legal basis, per Just Security’s analysis: the Pentagon’s JWCC contract means US military operations run on the same AWS, Azure, GCP, and Oracle commercial infrastructure that processes banking transactions and ride-hailing requests.
The boundary between civilian compute and military command, as Amoah, Bazilian, Matisek, and Schweiker wrote for the Foreign Policy Research Institute four months before the strikes, “has effectively vanished.”
Multi-AZ (multiple availability zones within a single cloud region, typically 30-60 miles apart) was designed for hardware failures. Disk dies, power grid flickers, cooling system fails. The workload fails over to another zone. That model assumed the threat was entropy. The Iran strikes introduced a threat model where an adversary deliberately targets multiple zones in a coordinated attack. Every DR architecture built on the assumption that multi-AZ equals resilience needs to be re-examined against threats that didn’t exist in any vendor’s whitepaper 18 months ago.
The four patterns of cloud DR (and where most organizations stopped)
The terminology gets thrown around loosely and the distinctions actually matter. Two numbers define every disaster recovery plan.
RPO (Recovery Point Objective): how much data can an organization afford to lose, measured in time. An RPO of one hour means tolerating the loss of the last 60 minutes of transactions. RTO (Recovery Time Objective): how long until systems are back. An RTO of four hours means four hours of downtime the business can absorb.
ELI5: Think of RPO as “how far back do I have to rewind?” and RTO as “how long am I sitting in the dark?” A backup from last night means the RPO is ~24 hours. A hot standby that takes over in seconds means the RTO is near zero. Every DR decision is a trade-off between those two numbers and what it costs to shrink them.
AWS’s disaster recovery whitepaper defines four patterns, and they’re useful because every major cloud provider’s DR services map to the same framework:
Backup and restore. Cheapest. Periodic backups get stored in another region, and if disaster hits, new infrastructure spins up and restores from backup. RPO depends on backup frequency. RTO can be hours to days because recovery means rebuilding from scratch. Most small and mid-sized organizations live here.
Pilot light. Core infrastructure (database replication, identity services) runs continuously in the DR region. Application servers stay off until needed. Flipping the switch still requires “turning on” servers, deploying additional infrastructure, and scaling up. Near-zero RPO for data; RTO measured in minutes to hours. AWS DRS automates this pattern at $0.028/server/hour, roughly $20 per server per month.
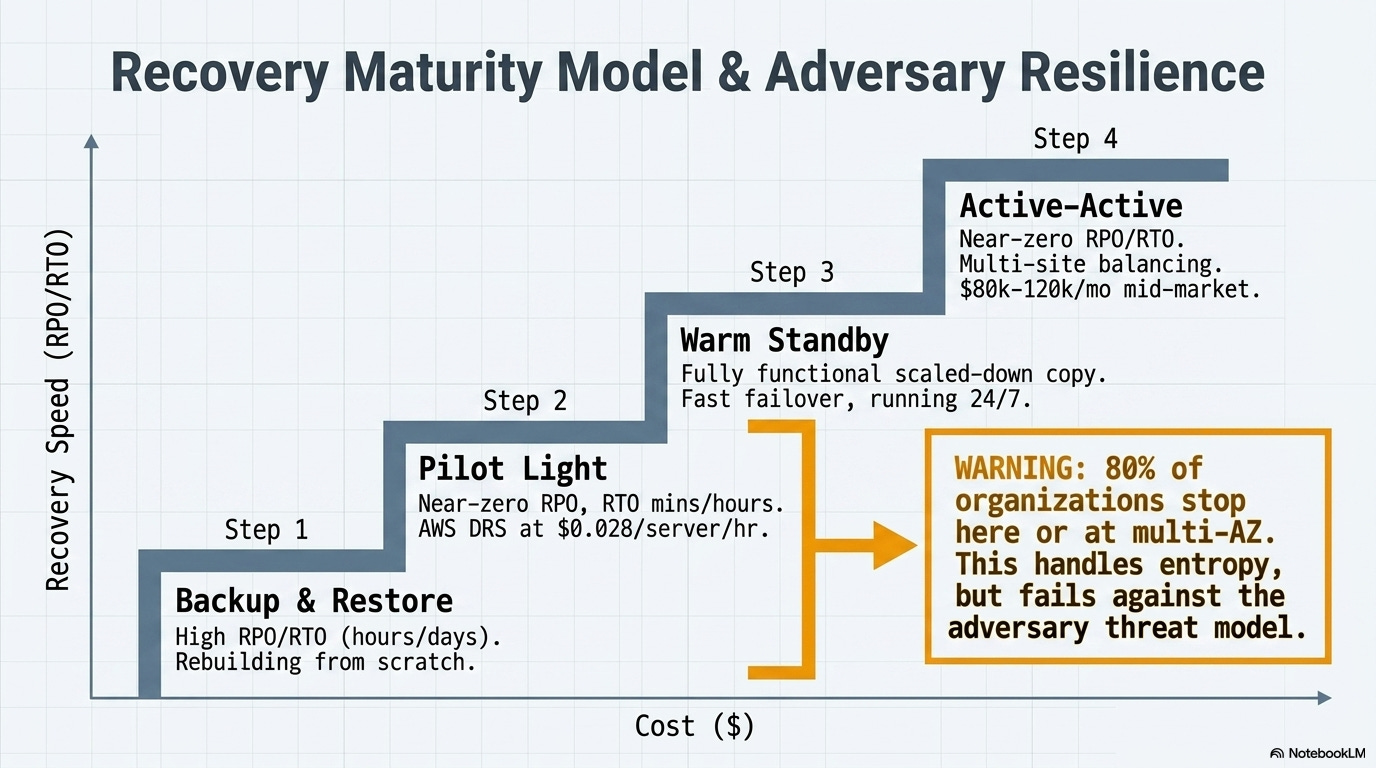
Warm standby. A fully functional but scaled-down copy of the production environment runs continuously. The key distinction from pilot light, per AWS: “warm standby can handle traffic immediately... pilot light requires you to ‘turn on’ servers.” The trade-off is paying for a smaller version of production to run 24/7, but failover is fast.
Active-active (multi-site). Workloads run simultaneously in multiple regions. Traffic is balanced across them. If one region goes down, the others absorb the load with near-zero RTO and RPO. This is the gold standard and the most expensive option by a wide margin. Aurora Global Database replicates with sub-second latency and can promote a secondary region to read/write in under a minute.
In practice: A mid-market financial services firm running 200 servers might pay $4,000/month for pilot light DR with AWS DRS. The same firm doing active-active across two regions could spend an estimated $80,000-120,000/month in compute, storage, and cross-region replication, before egress fees (the cost a cloud provider charges to move data out of its network or between regions). That’s why 80% of large organizations report using multi-region cloud storage for DR, but the majority of those are running backup-and-restore or pilot light, not active-active.
Most organizations stopped at multi-AZ within a single region. It’s included in the base cost of most managed services. It handles the failures teams actually encounter: hardware faults, rack-level outages, the occasional power event. For a decade, it was enough. The threat model was entropy: things break randomly, and geographic separation within a metro area handles random breakage well.
March 1 proved that model has a ceiling. An industry expert quoted by InfoQ put it directly: “Multi-AZ is NOT disaster recovery. It protects you from hardware failures, not a missile hitting an entire availability zone cluster.”
What each provider actually offers
Comparing cloud DR across the four major providers is harder than it should be, because each one packages capabilities differently and none of them makes pricing simple. Here’s what I found when I went through the official documentation.
AWS — 38 regions, 120+ availability zones, 6 more planned (Mexico, New Zealand, Saudi Arabia, Thailand, Taiwan, European Sovereign Cloud).
DR service: Elastic Disaster Recovery (DRS) — the most mature single-product offering at $0.028/server/hour
Replication: S3 Cross-Region Replication, Aurora Global Database with sub-second replication, DynamoDB Global Tables
Egress: $0.02/GB within North America
Sovereign cloud: GovCloud (US) only; European Sovereign Cloud planned but not yet live
Gulf exposure: The infrastructure that was struck is AWS’s primary Middle East presence. No Russian data centers, never will
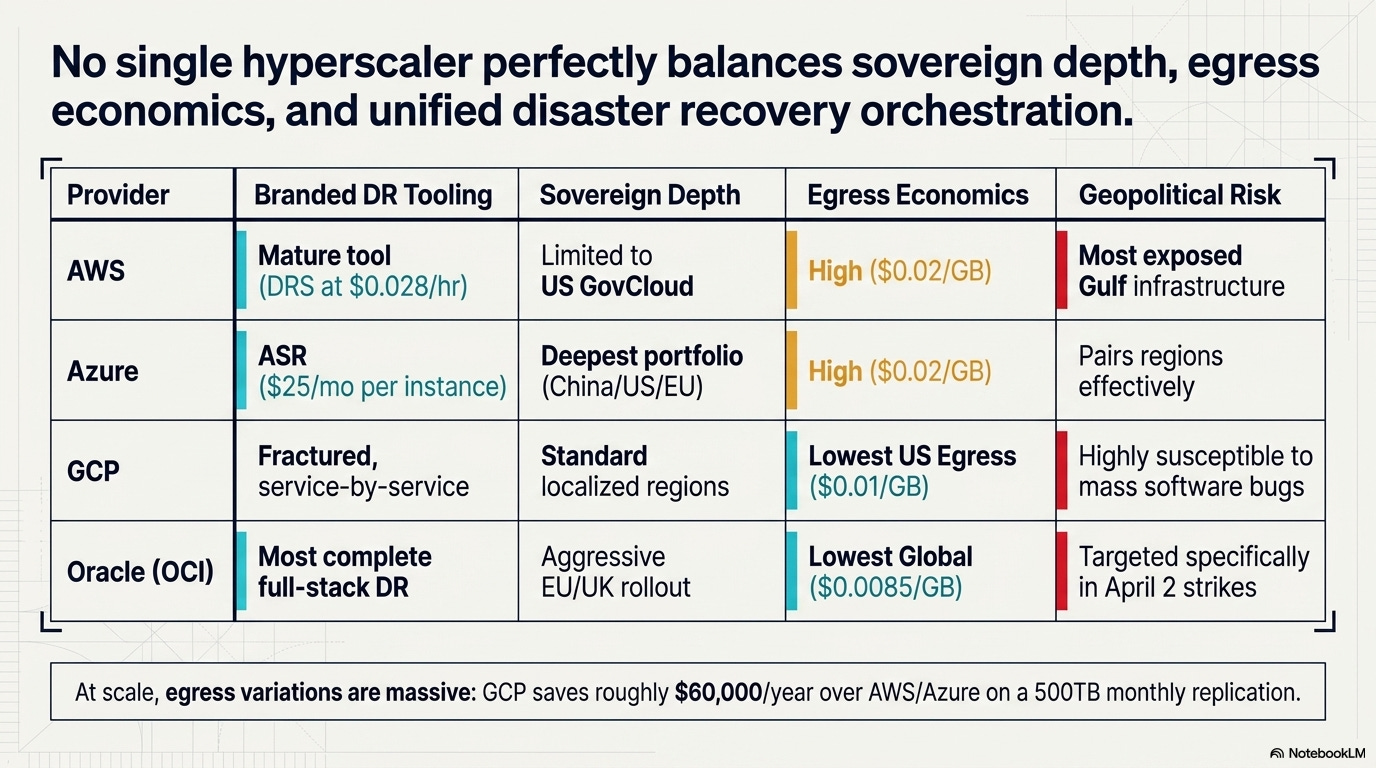
Azure — 60+ announced regions (not all generally available).
DR service: Azure Site Recovery (ASR) — $25/month per protected instance. Supports Azure-to-Azure, on-premises-to-Azure, and on-premises-to-secondary datacenter
Standout feature: Geo-redundant storage (GRS) with regional pairing — Switzerland pairs with France, UAE with a second UAE zone
Sovereign cloud: The deepest portfolio of the four — Azure Government (US), Azure China operated by 21Vianet, new Azure Germany regions in 2026. The China partnership is a genuine differentiator for multinationals needing compliant cloud presence in both the US and China
Egress: $0.02/GB, matching AWS
GCP — 43 regions, 130 zones, 7.75 million km of private fiber network.
DR approach: Architecturally different — no single branded DR orchestration tool. Each service handles its own replication (BigQuery managed DR, Cloud SQL cross-region read replicas, AlloyDB cross-region replication)
Replication: Dual-region and multi-region Cloud Storage buckets with automatic replication. The lack of a single-pane DR product is a weakness for organizations that want one dashboard
Egress: $0.01/GB within the US — half of AWS and Azure. At 500TB monthly replication, that saves roughly $60,000/year on egress alone
Trade-off: A June 2025 outage exposed a null pointer vulnerability that took down 50+ services across 40+ regions simultaneously. Software failures don’t respect region boundaries
Oracle Cloud Infrastructure (OCI) — 50 regions.
DR service: Full Stack Disaster Recovery — orchestrates compute, database, networking, and application DR across regions. The most complete stack-level DR product of the four
Sovereign cloud: The most aggressive strategy — EU Sovereign Cloud (Germany + Spain, 4 data centers, 1,500+ EU-based staff), UK Government cloud (London + Newport, the only sovereign dedicated dual-region in the UK), Australia Government cloud in Canberra
Egress: 10 TB free per month — 100x more than the 100 GB free tier from AWS, Azure, and GCP. Beyond the free tier, $0.0085/GB still undercuts all three competitors. A deliberate competitive play for DR workloads where egress is a major cost driver
Gulf exposure: The Oracle data center in Dubai Internet City took shrapnel damage from the April 2 interception. Targeted specifically, per IRGC statements, because of Larry Ellison’s ties to Israel and DoD contracts
ELI5: Picking a cloud DR provider is like choosing between four insurance companies after a hurricane. They all cover the basics, but the premiums, deductibles, and fine print are wildly different. AWS has the widest network of offices. Azure has the most government-approved plans. Google offers the cheapest data transfer. Oracle covers the entire building, not just the walls. And right now, they’re all scrambling to add coverage for a type of disaster none of them had in their actuarial models.
No single provider solves the fundamental problem exposed by the Gulf strikes. Multi-region DR only works if the secondary region is outside the blast radius of the threat. “Blast radius” now includes coordinated military operations across an entire geographic theater.
The data residency collision
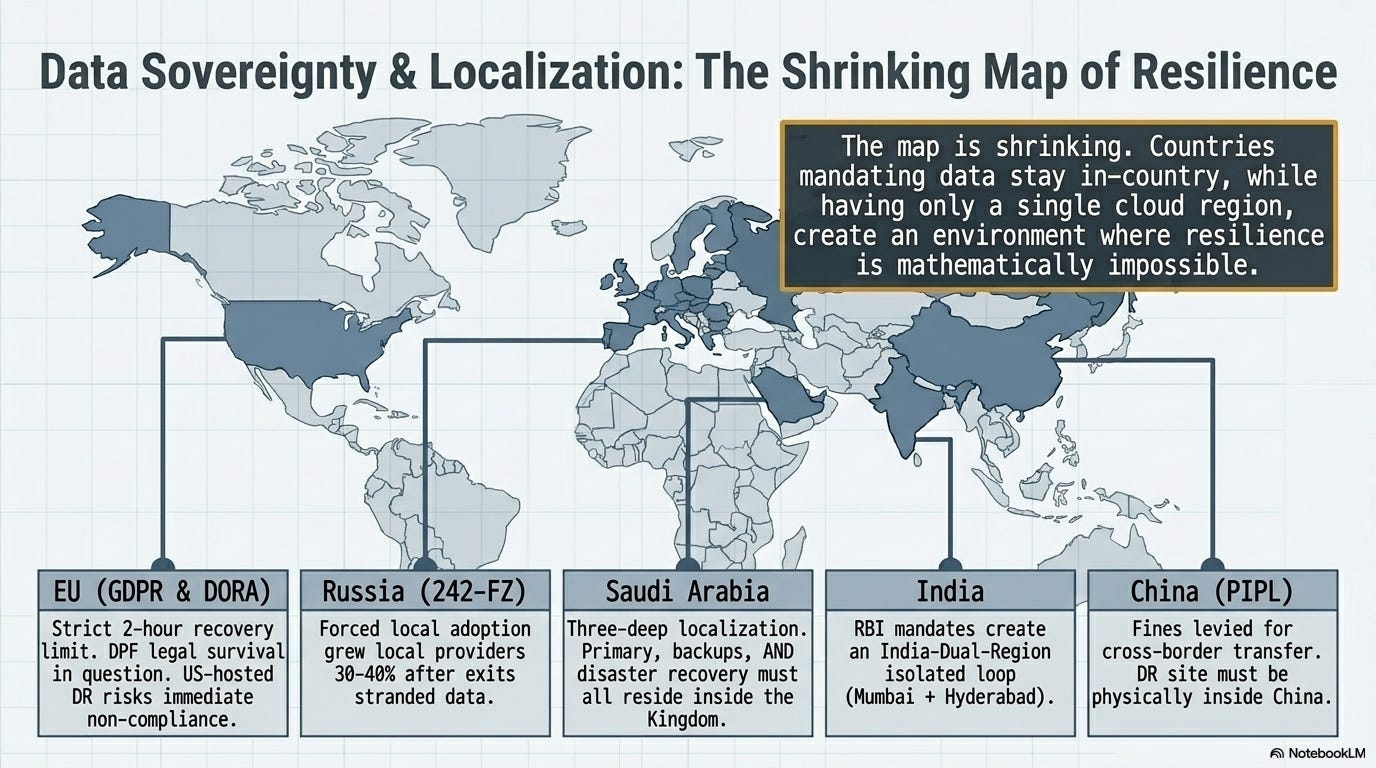
DR planning runs head-first into regulatory reality. The best defense against a regional disaster is replicating data to a distant region. The fastest-growing body of regulation globally says data must stay inside the country.
Those two requirements are irreconcilable in a growing number of jurisdictions.
EU GDPR and Schrems II treat backup replicas in US data centers as international data transfers, subject to the same compliance requirements as primary data hosting. A common mistake, as one EU analysis noted: “hosting the primary database in Europe but storing backup replicas in a US data center, which constitutes an international data transfer.” The EU-US Data Privacy Framework survived its first legal challenge in September 2025, but the PCLOB (the key oversight body) has been gutted by the Trump administration. NOYB expects a CJEU referral. If the DPF falls, every US-hosted DR site holding EU citizen data becomes non-compliant overnight.
Russia’s 242-FZ (effective since September 2015) requires all personal data of Russian citizens to be stored on servers physically in Russia. When cloud providers exited in 2022, the data couldn’t legally leave. LinkedIn has been blocked since 2016 for non-compliance. Local Russian cloud providers saw 30-40% growth in 2023, forced adoption rather than organic market success. Customers ended up stranded on less capable platforms because the law left them no choice.
China’s PIPL requires critical infrastructure operators to store data within China and subjects cross-border transfers to government security assessment. In September 2025, a European luxury brand’s Shanghai subsidiary was fined for illegal cross-border data transfer. For DR purposes, this means China-hosted data stays in China. The DR site for Chinese operations must also be in China.
Saudi Arabia has the most interesting layered approach. The PDPL (enforcement began September 2024) requires personal data transfers to be approved case-by-case by SDAIA. But the National Cybersecurity Authority’s Cloud Cybersecurity Controls go further: primary data, backups, AND disaster recovery systems for critical infrastructure must ALL reside within the Kingdom. That’s three-deep localization: not just the live data but every copy of it.
South Korea enacted a new regulation effective February 2026, requiring large financial companies to establish dedicated disaster recovery centers. India’s RBI and SEBI localization mandates have created an “India-Dual-Region” model where Mumbai serves as primary and Hyderabad as DR. Brazil’s 2026 mutual adequacy decision with the EU makes European data centers the preferred low-friction DR location for Brazilian companies. Canada outlined a Sovereign Cloud Initiative in October 2025 requiring government data to be stored and processed exclusively in Canada.
EU DORA (effective January 17, 2025) applies to financial entities specifically and requires documented DR plans, an immutable third backup that is physically and logically segregated, recovery within 2 hours, and annual testing. That 2-hour recovery requirement matters: AWS declared “prolonged” recovery for Gulf data centers with no timeline. If a DORA-regulated financial institution had its primary site in the UAE and its DR site in another Gulf region, it was non-compliant the moment the drones hit.
The structural problem: many countries have only one cloud region from any given provider. Saudi Arabia, for example, has AWS’s planned region but no current multi-region option. The UAE had ME-CENTRAL-1, now damaged. Countries that mandate data stay in-country while having only a single cloud region are creating a regulatory environment where compliance and resilience are mathematically impossible to achieve simultaneously. The data residency mandate and the DR best practice are pulling in opposite directions, and the gap is widening as more countries adopt localization laws.
ELI5: Imagine you’re told your backup house key must stay inside your house. That’s data residency. Now imagine your house catches fire and someone asks why you didn’t have a key stored at a neighbor’s place. That’s disaster recovery. You can’t do both at the same time, and more countries are requiring the first while physics demands the second.
When conflict hit: Russia, Iran, Ukraine
I’m not drawing geopolitical conclusions here. I don’t have an angle on who’s right or wrong in any of these conflicts. But the infrastructure implications are concrete and worth examining on their own terms, because they create precedents that every technology leader needs to factor into planning.
Russia: the exit that stranded data (2022-2024)
When Russia invaded Ukraine in February 2022, the cloud provider exits happened fast but unevenly. AWS never had data centers, infrastructure, or offices in Russia and stopped new sign-ups in March 2022. Microsoft had no Russian data centers but had partnered with Russian telecom MTS since 2018 for Azure-based services; it suspended all new sales in March 2022 and by 2024 had suspended access to cloud services for Russian users entirely under EU sanctions. Google confirmed it stopped accepting new Cloud customers in Russia. Oracle suspended all operations, triggering litigation between Russian distributors and customers.
The data residency problem was immediate. Russian law (242-FZ) required personal data to stay on Russian servers. Cloud providers were leaving. The data couldn’t legally leave. The combined Russia and Ukraine market was 5.5% of European ICT spending, about 1% worldwide. Small in global terms but large enough that thousands of organizations had data that was suddenly both legally immovable and operationally inaccessible. Local Russian providers absorbed the demand, growing 30-40% in 2023, but these were less capable platforms filling a void created by sanctions, not a market functioning normally.'
Iran: the first military strike on commercial data centers (March-April 2026)
The March 1 strikes on AWS established a precedent. The April 1 strike on an additional AWS data center in Bahrain extended it. The April 2 IRGC claim against Oracle’s Dubai Internet City facility (confirmed as shrapnel damage from interception) demonstrated that the target list was expanding beyond any single provider. On March 31, the IRGC published a list of 18 US companies designated as “legitimate targets.”
The legal analysis from Just Security was blunt: “This represents an unprecedented, perhaps even first, attack on commercial data centers by a party to an armed conflict.”
The JWCC contract (the Pentagon’s Joint Warfighting Cloud Capability deal, awarded in 2023) means US military workloads run on the same commercial cloud infrastructure as civilian customers.
Under international humanitarian law, a civilian data center becomes a lawful target only if it provides “effective contribution to military action.” The dual-use nature of these facilities now makes that determination permanently ambiguous.
The strike damaged more than servers. The Red Sea submarine cable cuts told the other half of this story. Four major cables severed in March 2024 (AAE-1, EIG, SEACOM, TGN) disrupted roughly 25% of internet traffic between Asia, Europe, and the Middle East. Additional cables near Jeddah were cut in September 2025.
The lesson: data doesn’t need to be destroyed to be unreachable. Severing the network path between primary and DR sites has the same operational effect as destroying the DR site itself. 17% of global internet traffic passes through Red Sea cables. 80% of Asia-to-West traffic uses these routes.
Ukraine: the counter-narrative where cloud saved everything
Ukraine migrated 15+ petabytes of government data to AWS, Azure, and GCP after the invasion. 161 state registries, 356 organizations moved to cloud. AWS shipped Snowball devices from Dublin through Poland. PrivatBank, holding accounts for 40% of Ukraine’s population, migrated 270 applications, 4 petabytes, and 3,500 servers in 45 days. Ukraine’s Ministry of Defense website moved to cloud and withstood what Amazon described as “even the largest coordinated assaults by Russian hackers.” By August 2023, 25% of Ukraine’s telecom infrastructure had been physically destroyed. Total damage cost: $1.6 billion. Over 9,000 cyber incidents recorded between 2022 and 2024.
Cloud migration saved Ukrainian government continuity. Ukraine’s Digital Transformation Minister said it directly: “Cloud migration saved Ukrainian government and economy.”
The same cloud architecture that saved Ukraine’s government by distributing its data across distant regions created the vulnerability in the Gulf by concentrating commercial infrastructure in geographically exposed facilities. Cloud saved Ukraine because the data moved away from the target zone. Cloud failed in the Gulf because the data was the target zone. Same technology, opposite outcomes, determined entirely by whether the threat model pointed inward (at physical buildings) or outward (at digital assets stored elsewhere).
I reviewed Chris Miller’s Chip War book last year arguing that semiconductor manufacturing concentration is the defining geopolitical vulnerability of this decade. Ninety percent of advanced chips from a single company on a single island.
Data centers have the same exposure. If TSMC is the single point of failure for compute manufacturing, hyperscale data center clusters in geopolitically exposed regions are the single point of failure for compute delivery.
Silicon wafers or stored bytes: geographic concentration creates fragility either way.
The budget conversation no one wants to have
On average, disaster recovery consumes 15-25% of total IT budget. The DRaaS (Disaster Recovery as a Service) market is projected to grow from $16.1 billion in 2025 to $46.1 billion by 2032, a 16.2% compound annual growth rate. That’s a nearly 3x increase in seven years, driven largely by the kind of events I’ve described above.
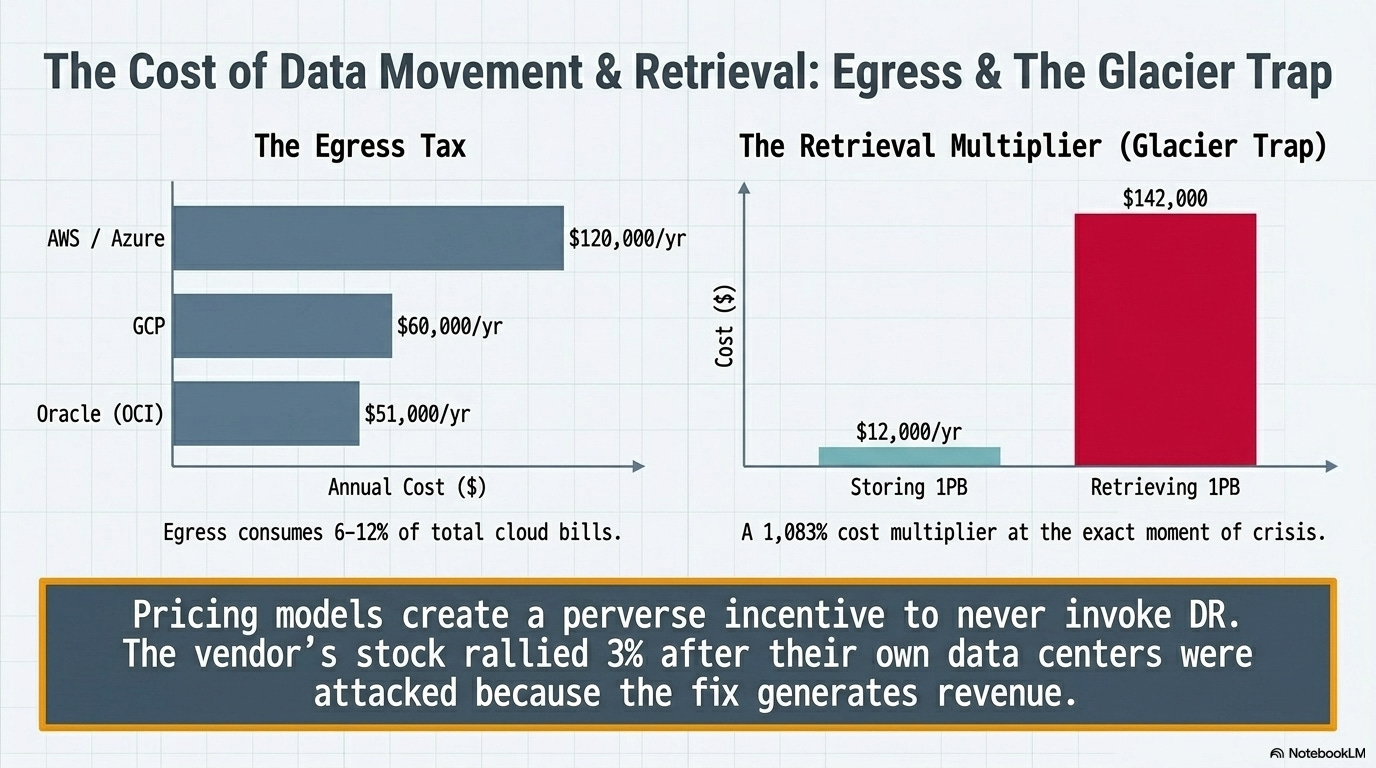
Egress fees are the hidden DR tax.
Cross-region data transfer costs 6-12% of typical cloud bills. At $0.02/GB for AWS and Azure, a SaaS platform replicating across three regions might pay an estimated $25,000-$40,000 per month in egress alone. Annually, that’s $300,000-$480,000 just for the privilege of moving data between the same provider’s regions.
GCP’s lower egress ($0.01/GB) and Oracle’s even lower rate ($0.0085/GB) are genuine competitive differentiators here. Oracle’s pricing for 500TB monthly replication saves roughly $69,000/year versus AWS. That’s not a rounding error when DR budgets are under scrutiny.
The egress cost problem gets worse at the moment it matters most.
A Wasabi analysis of AWS S3 Glacier Deep Archive found that storing 1 petabyte costs roughly $12,000/year, but actually retrieving it during a disaster costs $142,000: a 1,083% cost multiplier at the exact moment of crisis. The pricing model creates a perverse incentive to never invoke DR, which might explain the next number.
A concrete benchmark: a 50-VM environment using Azure Site Recovery runs $3,300-$5,000/month.
A mid-sized organization (500-2,000 employees) should budget $75,000-$150,000 annually for DRaaS.
Larger organizations (2,000+) are looking at $150,000-$300,000 or more, and those numbers assume standard DR, not compliance-driven multi-region with sovereign cloud requirements.
DORA’s mandate for an immutable third backup in a physically separate location adds another infrastructure layer that nobody’s published clean pricing for, because the consultancies selling the compliance work aren’t eager to let organizations self-serve.
The most striking number from the aftermath: Amazon’s stock rallied approximately 3% after its own data centers were attacked. Analysts predicted organizations would be forced into multi-region deployments, driving increased cloud service revenues. The vendor’s stock goes up when its infrastructure gets hit because the fix (more regions, more replication, more services) means more revenue.
IDC cut its 2026 global IT spending growth forecast from 10% to 9% because of the Middle East conflict, but private cloud spending specifically is projected to surge 36%, potentially hitting $80 billion in 2026.
In July 2024, a CrowdStrike software update took down 8.5 million systems globally.
No missiles. No drones. A bad software push on a Friday.
The CrowdStrike outage caused more total economic damage than the Iran strikes, affecting vastly more systems across every continent. The most likely DR failure mode for most organizations remains poor planning and untested recovery procedures, not geopolitical conflict.
Cockroach Labs surveyed 1,000 VP-level executives and found that 71% of organizations do zero failover testing. Sixty-two percent don’t do regular backup restoration exercises. The Uptime Institute’s 2025 data tells the same story from the other direction: outage frequency has dropped from 78% to 50% over four years, and only 9% of 2024 incidents were classified as serious or severe, the lowest level ever recorded. The underlying risk is declining while DR spending surges 25-31% annually. Technology sector downtime costs $10,000 to $1 million per outage. Healthcare ransomware runs $900,000/day. Manufacturing: $1.9 million/day.
That doesn’t mean the geopolitical threat is irrelevant. It means the budget conversation needs to cover both: the mundane failures that are statistically more likely AND the catastrophic scenarios that are now proven possible. The CrowdStrike outage was a software problem with a software fix. The Gulf strikes destroyed physical infrastructure with no announced recovery timeline. Different failure modes require different budget lines.
The emerging “sovereignty tax” is making this harder for everyone except the largest organizations. Compliant multi-region DR in a world of data localization mandates (separate sovereign cloud instances, in-country backup copies, out-of-country DR replicas with appropriate legal frameworks) creates a two-tiered market. Organizations large enough to absorb 20-30% cost premiums for sovereign cloud get genuine resilience.
Everyone else makes trade-offs between compliance and survivability. A new role is emerging in response: the “geopolitical cloud architect,” blending technical infrastructure knowledge with international law. That job title didn’t exist two years ago.
To be fair
The expected-value math doesn’t support rewriting a DR budget around drone strikes. The CrowdStrike outage in July 2024 took down 8.5 million systems across every continent because of a bad software push on a Friday. No missiles. No geopolitical adversary. Just a configuration change that wasn’t tested properly. That single incident caused more aggregate economic damage than coordinated military strikes on purpose-built cloud infrastructure. For most organizations, the statistically dominant DR failure mode is still a Monday morning where the backups turn out to have been silently failing for six weeks, or a regional failover that nobody tested end-to-end because the tabletop exercise got a green checkmark and the real test got deferred to next quarter. (71% of organizations, per Cockroach Labs, do zero failover testing. The backups exist for auditors, not for actual disasters.)
I don’t think that makes the geopolitical threat irrelevant. What happened on March 1 established a precedent that won’t be un-set, and the JWCC dual-use classification means the target list for any future conflict is already written.
But if a mid-market organization has a $150K DR budget and its last real recovery test was eighteen months ago, the honest priority is testing what exists before buying what doesn’t. The missiles made headlines. The untested backup that silently failed last Tuesday will make the incident report.
What to do this quarter
The threat model changed. The playbook has to change with it.
This month:
Inventory every workload by region. Map which jurisdictions’ data residency laws apply to each. Identify any workload where compliance and DR are currently pointing at the same single region. Those are the highest-risk items.
Confirm RPO/RTO targets reflect current business reality, not the numbers someone wrote three years ago. Financial services firms operating under DORA: a stated 2-hour RTO better have a tested recovery path that doesn’t depend on a single geographic theater.
Review cloud provider contracts for force majeure language. “Military action” was theoretical when those contracts were signed.
This quarter:
For any workload currently running multi-AZ only, evaluate multi-region. Get real pricing. Egress costs will be the sticker shock. Budget for them explicitly rather than discovering them in next quarter’s bill.
Test a regional failover. Not a tabletop exercise. An actual failover to the designated DR region, under load, with a clock running. Most organizations that think they have DR have never tested it end-to-end.
Start the data residency mapping exercise that will take six months anyway. Which data can legally leave its current jurisdiction? Which can’t? Where are the single-region bottlenecks?
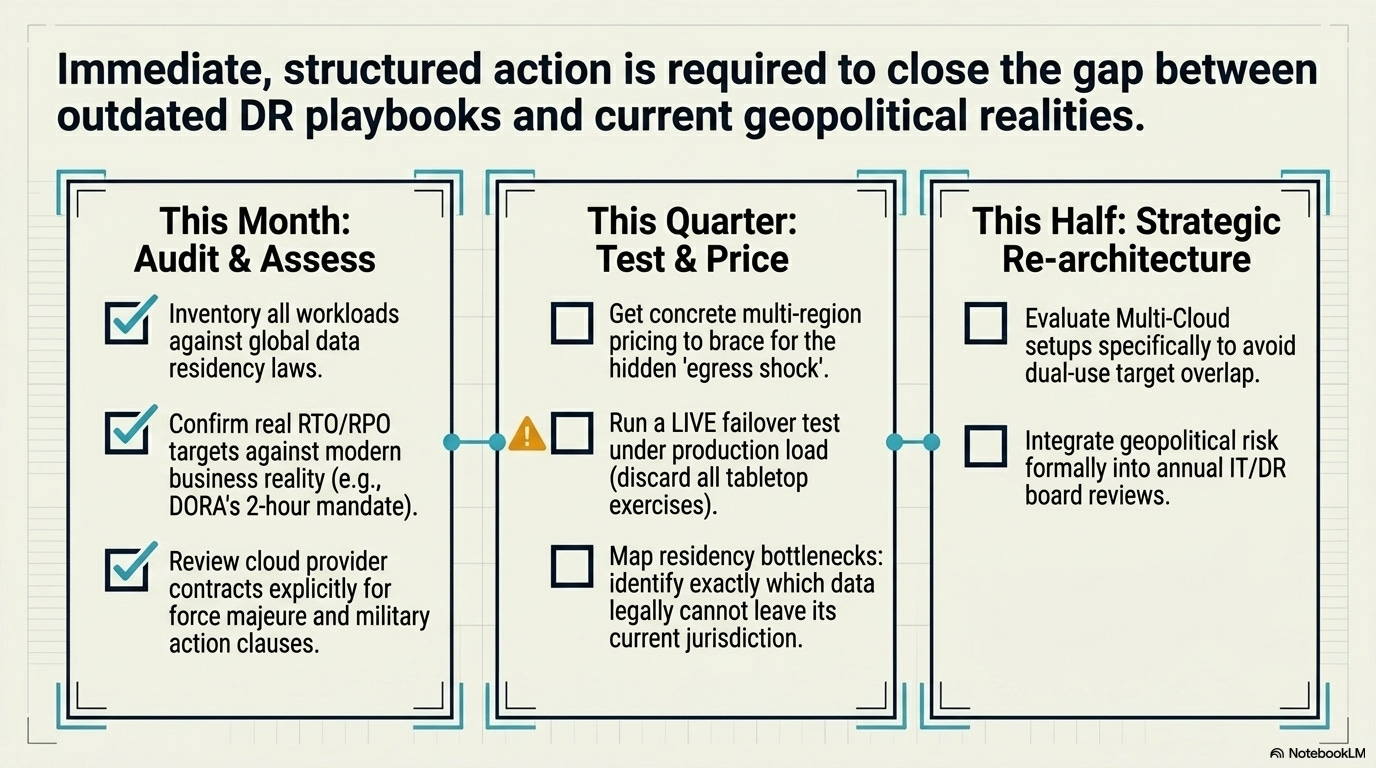
This half:
Evaluate multi-cloud DR for critical workloads. This is expensive and operationally complex, but the JWCC dual-use problem means that any single US-headquartered cloud provider’s infrastructure could become a target designation in a future conflict. Spreading critical workloads across providers, not just regions, is the only architecture that survives a provider-level targeting decision.
Build the geopolitical risk assessment into the annual DR review. Which cloud regions are in countries with active territorial disputes, sanctions exposure, or single-provider presence? This is the kind of planning that didn’t exist in any playbook before March 2026.
The post-9/11 financial system response is a useful reference point. After the attacks destroyed telecom infrastructure in lower Manhattan, regulators mandated geographic separation for financial system resilience.
The Gulf strikes may trigger the same regulatory reflex for cloud infrastructure.
DORA is already there for European financial services. The question is how quickly other jurisdictions follow.
The question thats on my mind is if the precedent of targeting commercial data centers holds, what does “safe distance” mean for DR when the threat is a nation-state with ballistic capability?
The old answer was “another availability zone 30 miles away.”
That answer died on March 1.
References:
FPRI: Data Centers at Risk — The Fragile Core of American Power
Federal Reserve: Implications of 9/11 for Financial Services
Cockroach Labs / Wakefield Research: State of Resilience 2025
War on the Rocks: Data Centers on the 21st Century Battlefield
Silicon Canals: When Militaries Share Data Centers with Banks